As everything from streaming services to e-commerce platforms and social networks grows, so does the available data and the need for efficient algorithms. To power these platforms and engage the end users, an increasing number of companies are investing in recommendation systems. Modern recommendation systems require a complex pipeline to handle both data processing and feature engineering at tremendous scale, while promising high service level agreements for complex deep learning (DL) models. Additionally, these complex DL models also need to be constantly updated and retrained to guarantee the best possible performance, while keeping the training price point down.
In this article, we introduce some of the challenges of running modern recommender systems. To tackle these challenges, we propose an end-to-end (E2E) democratization solution that includes optimized parallel data processing based on Apache Spark* and user-guided automatic model democratization via SigOpt AutoML. We present how the solution improves the E2E pipeline efficiency on commodity clusters for common recommender system workloads.
Motivations
Challenges of Recommendation Systems
The goal of a recommendation system is to automatically predict a user's preference based on context about the user and context about all possible preferences. The use of recommendation systems has been growing steadily in retail and e-commerce, healthcare, transportation and more. For some platforms, recommendations from automated recommendation systems account for as much as 30% of revenue. It is said that 35% of what consumers buy on Amazon comes from automated recommendations, and that 75% of what users watch on Netflix come from automated recommendations (source: How Retailers Can Keep Up with Consumers).1
Figure 1 shows the architecture of a modern recommendation system consisting of two major workstreams: data processing and modeling. Data processing handles data collection, processing, and uses feature engineering to generate features for model training. Modeling can be divided into two subcategories: model training and model serving.
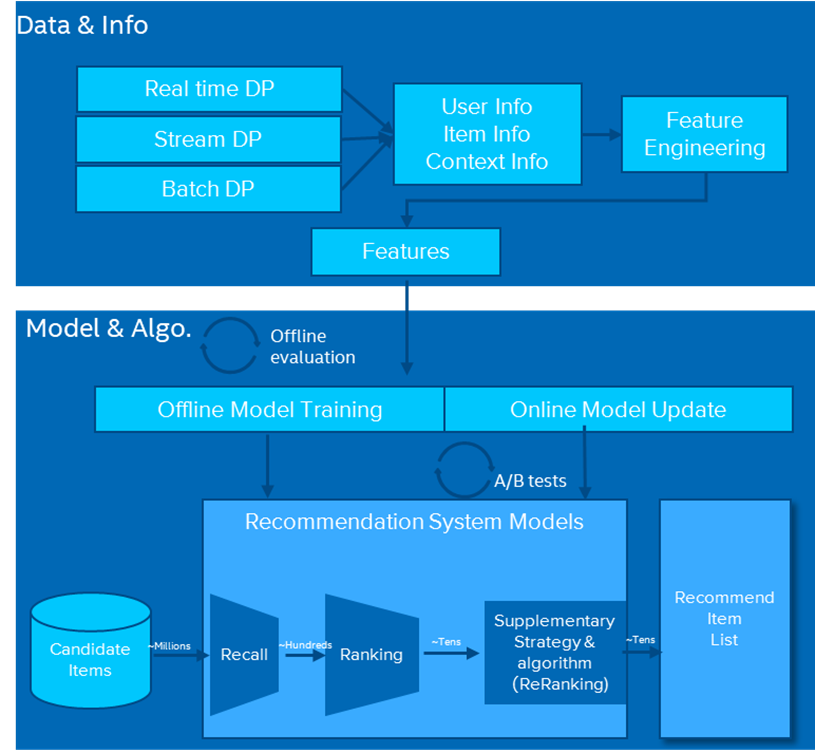
Figure 1. Recommendation system architecture.
Accuracy is critical when building an E2E recommendation system, but challenges arise with excessively large models and datasets:
- Huge datasets: Recommendation systems are often trained on large datasets (terabytes and sometime even petabytes), which requires large clusters to store and process the data. Slow data movement between the data processing and training/inference clusters can be challenging.
- Data preprocessing: Datasets need to be loaded, cleaned, preprocessed, and transformed into a suitable format for DL models and frameworks. This requires complex data processing technologies like batch/streaming data processing based on the type of data being processed.
- Feature engineering: Numerous sets of features need to be created, engineered, and tested, which is error-prone and time-consuming.
- Models and algorithm: Companies develop complex models and algorithms to generate the best business predictions. Those models require deep expertise and unique capabilities.
- Repeated experiments: Building and maintaining the best performing models is an iterative process that requires multiple experiments.
- Huge embedding tables: Categorical features require embedding and a large amount of memory, something that tends to be very bandwidth intensive.
- Distributed training: The heavy models usually require extreme computing power, so distributed training is a must, which makes both hardware and software scalability a critical challenge to be resolved.
Artificial Intelligence (AI) Democratization
The purpose of AI democratization is to make it accessible and affordable to every organization and end-user. Currently, AI is restricted to data scientists and data analysts who are specifically trained in this field. Therefore, making AI accessible to a wider user base is one of the goals of AI democratization. Moreover, AI requires hardware that can be expensive, so another goal of AI democratization is to make AI scale on commodity hardware that exists in most data centers.
There are multiple areas to be democratized:
- Data: Data democratization is a priority because AI cannot generate insights without data. Besides the amount of data, improving data quality and making data access easier and faster is also critical.
- Infrastructure: The effectiveness of AI relies on the infrastructure. Architecting the software and hardware platform, efficiently managing resource allocation, and auto-scaling are all important factors for infrastructure democratization.
- Hardware: The compute-intensive nature of AI requires specialized, and sometimes expensive, accelerators. Democratization aims to migrate AI frameworks from expensive accelerators to commodity hardware to reduce cost.
- Algorithms: To get an accurate prediction or inference, the models and algorithms can be very complex. Democratization tries to simplify the use, development, and sharing of AI algorithms to reduce the entry barriers.
SigOpt
The SigOpt intelligent experimentation platform helps users produce the best models. SigOpt is completely agnostic to the modeling framework. It automatically tracks and logs everything that has been done throughout the modeling process. This allows the user to visualize everything in a hosted dashboard. SigOpt also offers a set of proprietary optimization algorithms that help users optimize their models for the best performance. It gives modelers the ability to optimize multiple metrics and add both thresholds and constraints to guardrail these metrics and their impact on the final model.
Smart Democratization Advisor
After seeing customers struggle to bring deep learning recommendation models (DLRM) into production, we decided to democratize them to remove the common pain points like slow training times, large memory consumption, slow convergence, and communication overhead. We developed Smart Democratization Advisor (SDA), a human intelligence enhanced toolkit to generate recipes for SigOpt AutoML with parametrized configuration files (Figure 2). SDA uses SigOpt to automatically make the training faster through intelligent optimization, reduce the size of the model, find the optimal gradient descend method, and reduce the need for looking through massive look-up tables.
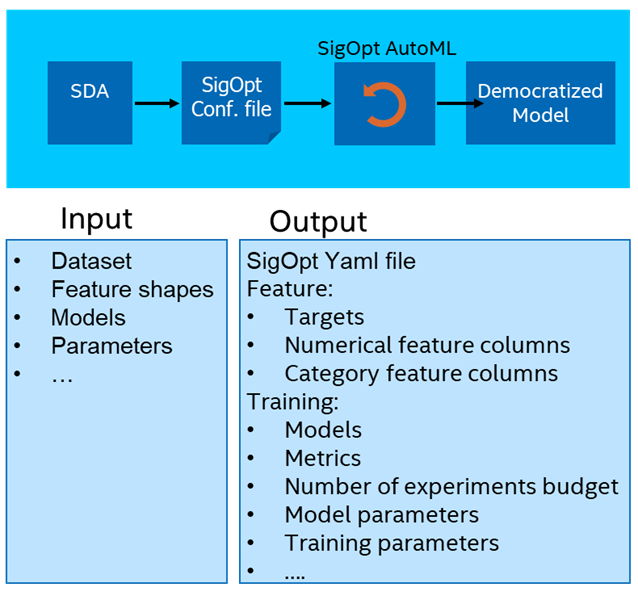
Figure 2. SDA overview.
SDA facilitates the generation of a SigOpt recipe based on expert-level knowledge of how a particular model, like DLRM, can be parametrized. SDA takes input choices around data, feature shapes, and models, and uses this information to automatically generate all the information needed to start a SigOpt experiment. Through built-in expert-level knowledge — such as the best suited number of layers, optimizers and hyperparameters — SDA automatically generates a parameterized configuration to facilitate SigOpt AutoML.
The generated configuration includes target features, models, model metrics, and some training-specific parameters like epochs, steps, etc. SDA converts the time-consuming, manual model tuning and optimization process to automated hyperparameter optimization (HPO), which simplifies the process of AI democratization, increases efficiency and empowers data scientists to deliver more value.
SDA Examples
SDA automatically generates a parameter configuration for all built-in models in YAML format that contains model parameters, training parameters, SigOpt parameters, etc. Figure 3 shows an example for a wide and deep model that includes model parameters (e.g., number of layers, hidden units per layer, size of embeddings, and dropout rate), training parameters (e.g., learning rate, learning rate decay, warmup steps, batch size, and optimizer), and SigOpt parameters (e.g., observation budget and parallel bandwidth). Users also have the freedom to add or remove parameters in any of the categories.

Figure 3. SDA-generated YAML file for a wide and deep model.
Once the YAML file has been generated, the user can start the SigOpt optimization loop. With SDA-generated model parameters, SigOpt experiments budget can be greatly reduced. Meanwhile, SDA can leverage SigOpt multimetric optimizations to further improve AutoML efficiency. The joint solution reduces the time needed to get the desired models into production.
Performance Evaluation
To evaluate how SDA performs, we designed several experiments to show whether SDA can democratize typical recommendation systems automatically, and how it performs compared with original models.
DLRM is a personalization model open-sourced by Meta (Figure 4). It was conceived by the union of the two perspectives in recommendation systems: both collaborative filtering and predictive analytics-based approaches. DLRM is able to work efficiently with production-scale data while delivering state-of-the-art results. It leverages embeddings to process sparse features and adopts multilayer perceptron (MLP) to process dense (numerical) features, then it interacts with features explicitly using statistical techniques. Finally, it predicts the event probability by postprocessing the interactions with another MLP.
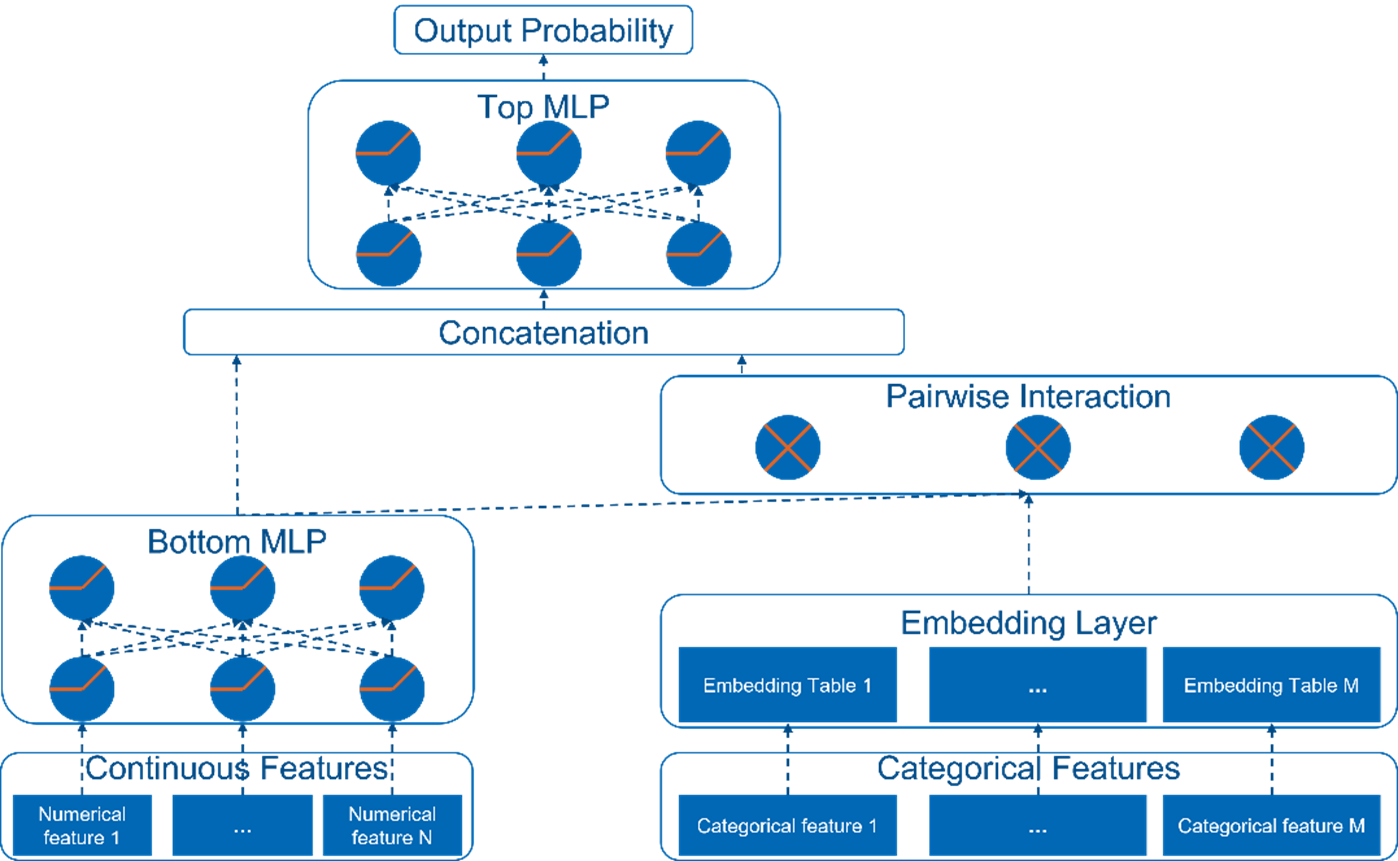
Figure 4. DLRM model architecture.
DLRM on commodity CPUs can be challenging, The initial NumPy data processing and model training can take several days. For data processing, the single-threaded NumPy data processing becomes a bottleneck. To resolve this issue, Intel developed and open-sourced RecDP, a parallel data processing toolkit for recommendation systems based on PySpark. RecDP can fully utilize multithreading and multi-node benefits when doing data processing and deliver up to 100x speedup over the original data processing solution.
The tests were conducted on a four-node cluster, each node equipped with two Intel® Xeon® Platinum 8358 processors, 512GB memory, and connected with 40GB Ethernet. A 1TB Intel® SSD DC P4500 NVMe was used as a data drive. Table 1 shows a detailed configuration.
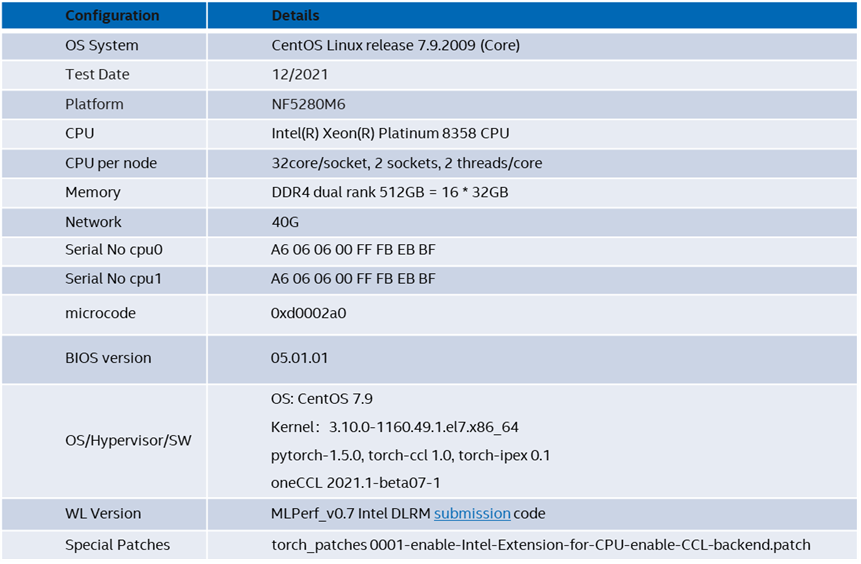
Table 1. System configuration.
To evaluate the improvement from SDA, we designed four test cases (Table 2):
- Original DLRM: The original DLRM model using E2E model training time as metrics
- SDA-assisted DLRM: The SDA-optimized model including all model tunings and optimizations
- SigOpt AutoML: The total execution time of five SigOpt experiments
- SDA-assisted SigOpt AutoML: The total execution time of SigOpt experiments, using SDA-generated configurations
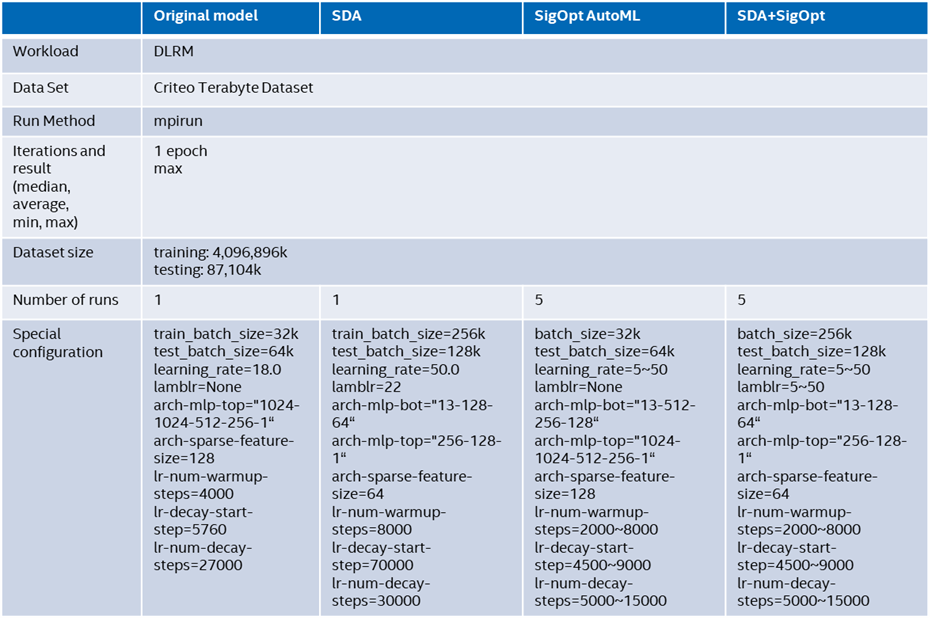
Table 2. Test configuration.
The DLRM performance comparison of the four test cases is shown in Figure 5. It shows that SDA can deliver 5.4x performance improvement over the original DLRM model and 5.2x speedup for SigOpt AutoML of five experiments while maintaining the same AUC (area under the ROC curve) as the original model.
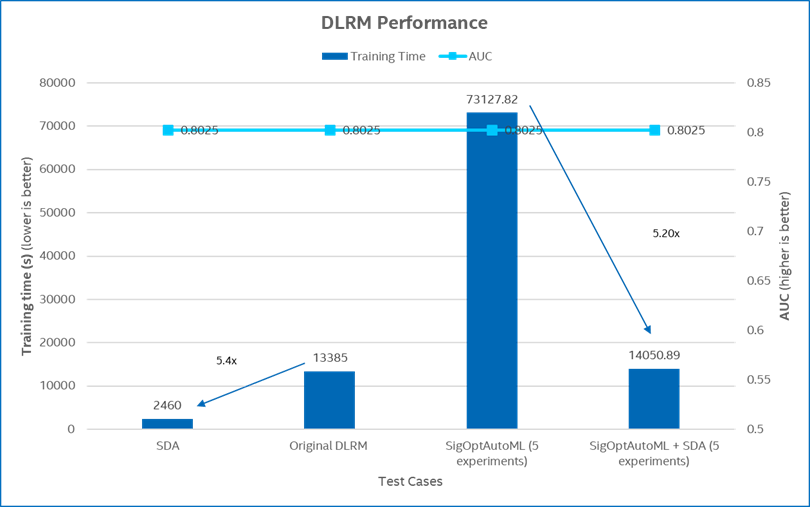
Figure 5. DLRM performance comparison.
SDA cannot deliver such results without the help of SigOpt multi-metrics and metrics threshold. To evaluate the effect of multi-metrics (accuracy and training time) in the SigOpt tuning process, we compare the performance of SigOpt AutoML plus SDA with or without multiple metrics. Figure 6 shows that multi-metrics and metrics threshold were able to reduce training time, delivering up to 1.26x speedup for the best metrics.
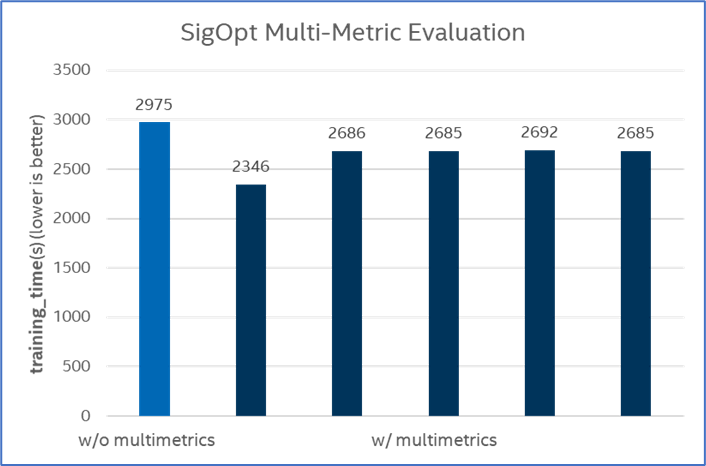
Figure 6. Multiple metrics performance.
To analyze the effect of multiple metrics, we explored both the time and AUC metrics for with and without multi-metrics (Figure 7). With multi-metric and metric thresholds, the number of experiments that delivered the same AUC but with lower training time increased.
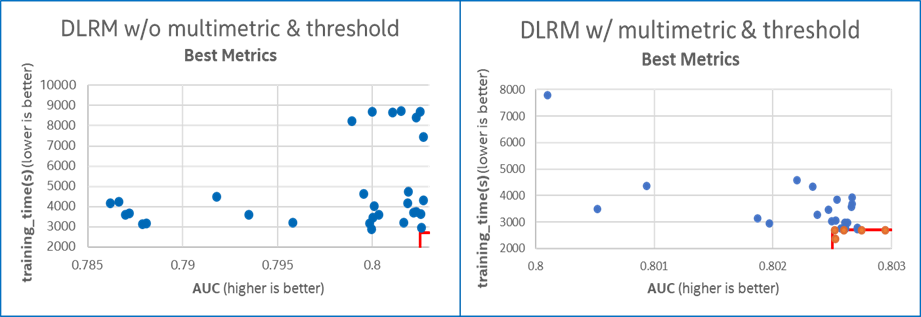
Figure 7. Best metrics comparison with and without multi-metrics and metrics threshold.
Summary
Recommendation systems are becoming increasingly popular as it brings genuine business values, but it also poses a lot of challenges due to its unique nature. E2E AI democratization is targeted to address those challenges to make AI accessible and affordable to every organization and every user. This article introduced SDA, one component of Intel AI democratization kit, to simplify and automate AI democratization. SDA is a toolkit to generate SigOpt recipes for autoML with parametrized configuration files generated by built-in expertise. Performance evaluation showed SDA-assisted SigOpt autoML delivers very promising results – up to 5x performance speedup for DLRM model while remaining at the same AUC. Meanwhile, SigOpt multi-metrics and metrics threshold further improves efficiency.
SDA is our first attempt toward AI democratization. If you want to use it, please check out the RecDP repo and stay tuned for future articles. If you want to use SigOpt for your own projects, visit sigopt.com/signup and sign up for free.
See Related Content
Articles
- Hyperparameter Optimization with SigOpt for MLPerf Training
Read - MiniNAS: Accelerate Neural Architecture Searc
Read - Optimizing Artificial Intelligence Applications
Read - A Scale-out Training Solution for Deep Learning Recommender Systems
Read - Cost Matters: The Case for Cost-Aware Hyperparameter Optimization
Read