DLRM (Deep Learning Recommendation Model) is a deep learning-based model for recommendations introduced by Facebook. It’s a state-of-the-art model and part of the MLPerf training benchmark. DLRM poses unique challenges on single- and multi-socket distributed training because of the need to balance compute-, memory-, and I/O-bound operations. To tackle this challenge, we implemented an efficient scale- out solution for DLRM training on an Intel® Xeon® processor cluster using data and model parallelization, new hybrid splitSGD + LAMB optimizers, efficient hyperparameter tuning for model convergence with much larger global batch size, and a novel data loader to support scale-up and scale-out. The MLPerf v1.0 training results demonstrate that we can train a DLRM with 64 Intel Xeon 8376H processors in 15 minutes, a 3x improvement over our MLPerf v0.7 submission (which could only scale to 16 Intel Xeon 8380 processors). In this article, we describe the optimizations that were applied to achieve this performance improvement.
Vertical Split Embedding Table-Based Hybrid Parallelism
We use a hybrid parallel solution to improve the scalability of DLRM MLPerf training, and then use a vertical split embedding table to improve scaling even further (Figure 1).
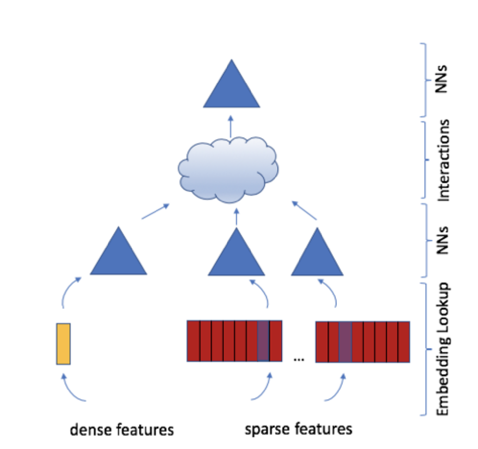
Figure 1. DLRM model structure. Dense features are the input of the bottom MLP (multilayer perceptron) layer, and sparse features are inputs for the embedding table. The outputs from the bottom MLP and embedding are the input to the top MLP layer.
There are 26 embedding tables in MLPerf DLRM training. The table entry numbers are 40M, 40M, 40M, 40M, 40790948, 3067956, 590152, 405282, 39060, 20265, 17295, 12973, 11938, 7424, 7122, 2209,
1543, 976, 155, 108, 63, 36, 14, 10, 4, and 3. To model the semantics for every entry, 128 Float32/Bloat16 numbers are used. A straightforward way to address an embedding table is to use data parallelism via sparse all-reduce. Model weights need to be replicated across model instances. With data parallelism, all embedding tables should be replicated, so 26 embedding tables require more than 100 GB memory for a single model instance.
To reduce communication overhead and the memory requirement on each device, we use a hybrid-parallel distributed training solution (Figures 2 and 3). The embedding table is divided into smaller tables that use dense gradients and large embedding tables that use sparse gradients. In the case of MLPerf DLRM, an embedding table is treated as a small table if an entry number is less than 2048; otherwise, it is treated
as a large table. We get 10 small and 16 large embedding tables. For model parallelism, model instances would hold a local copy of part of the large embedding tables. For example, if we use eight sockets and one
instance per socket, then every instance will hold two large embedding tables. For 16 sockets, every instance will only hold one large embedding table. Instead of lookup embedding tables with indices in a local batch, each model instance lookup local embedding table with indices in a global batch. After the lookup operation, model instances not only have lookup entries of their own local batches, but also have lookup entries of other instances’ batches. All-to-all collective communication is used to exchange embedding information between ranks. For data-parallelism, bottom MLP, top MLP, and 10 small embedding tables are replicated
in every model instance, and all-reduce collective communication is used to average the gradient between ranks.
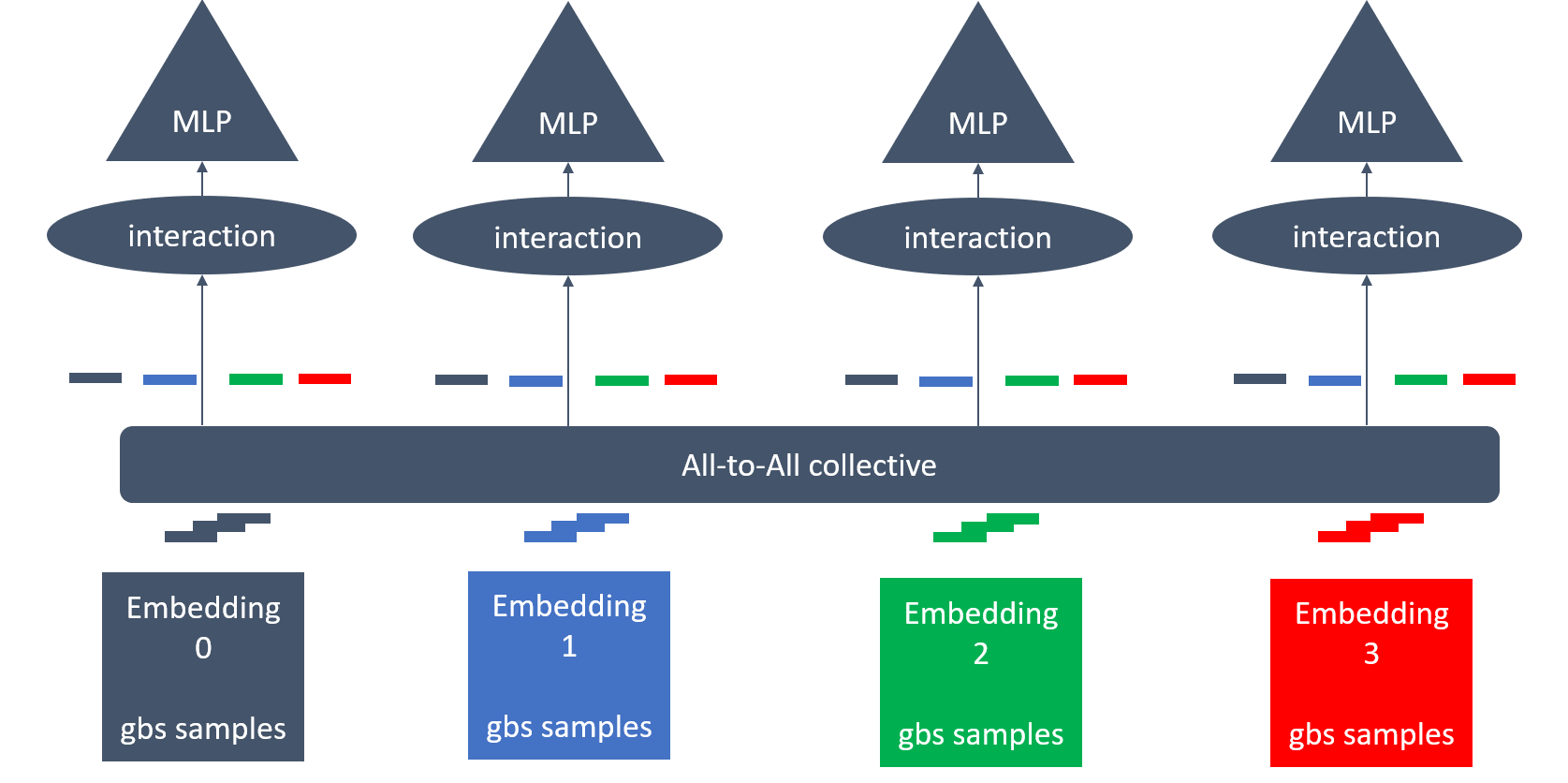
Figure 2. Illustration of hybrid parallelism between four model instances with four embedding tables. The colored blocks indicate different embedding tables (gbs: global batch size). Lookup entries from the same embedding table are dispersed to different instances.
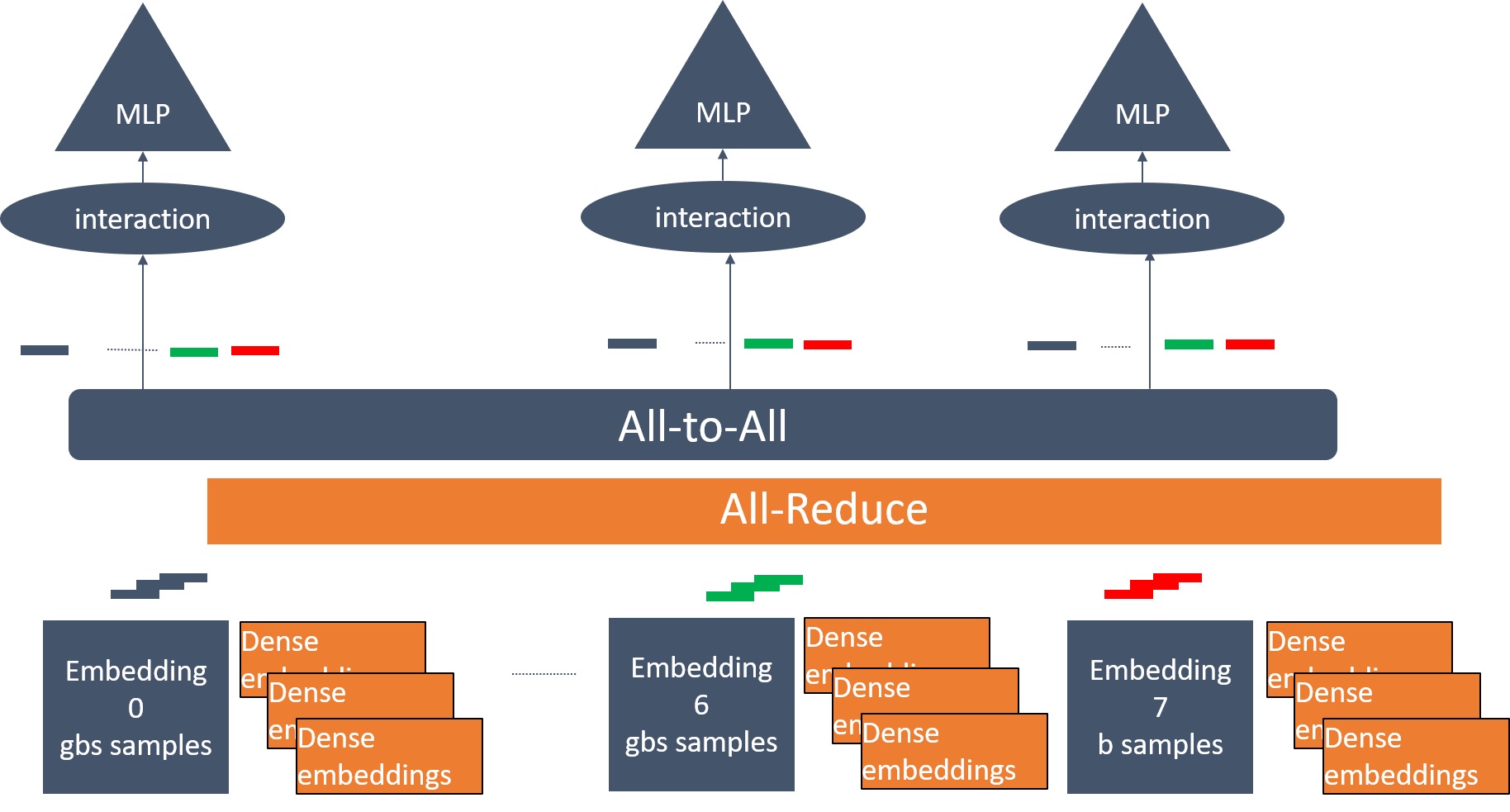
Figure 3. Turning small embedding table gradients into dense gradients. All-reduce is used to synchronize the gradients for data parallelism, and all-to-all is used to exchange embedding information for model parallelism.
The limitation of this approach is that the number of instances cannot exceed the number of large embedding tables. For MLPerf DLRM, we only have 16 large embedding tables, which means that we cannot scale to more than 16 instances. To improve scaling, we use vertical split embedding-based model parallelism (Figure 4). In this method, large embedding tables are vertically split into multiple embedding tables with the same entry number as the original. Each table has a subset of the columns in the original table. We then let each model instance hold one of the split tables and use all-to-all communication.
Suppose p (the number of ranks) is divisible by N (the number of embedding tables in the model) and the group number is g=p/N. We divide each embedding table into g tables. There are g*N=p embedding tables after vertical splitting. We put one embedding table on each model instance, lookup each table with global batch, and then use all-to-all to transpose the lookup entries among instances. After that, we concatenate entries belonging to the same original embedding table, and then go through the upper layers as in the data parallel approach.
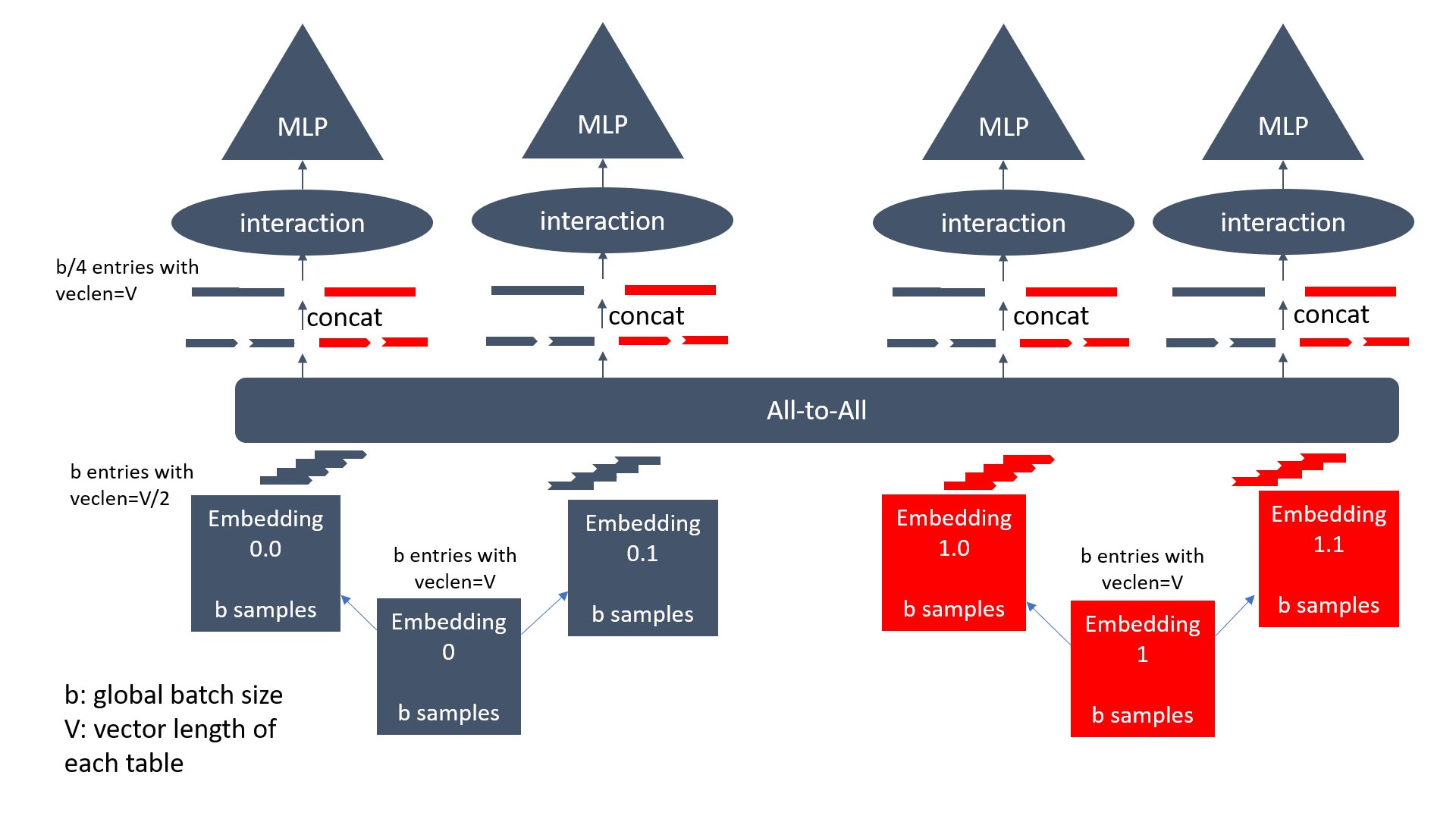
Figure 4. A model with two embedding tables training on four instances. Each table is split vertically into two tables (V: vector length of each row in embedding table). The lookup entries are transposed among all instances, and entries belonging to the same table (same color) are concatenated. This allows us to train a model with two embedding tables on four ranks, which wasn’t previously possible.
The advantages of our vertical split embedding-based hybrid parallel approach are as follows:
- Compared to sparse all-reduce data parallelism, by treating small tables as dense and splitting large sparse tables vertically, we reduce the communication overhead of models with embedding tables. This reduces TTT (time-to-train) and allows more efficient scaling of multiple model instances.
- DLRM training is a memory-bound workload because of the large embedding tables. In our solution, there is only local copy to the subset of columns of the large embedding table, which reduces the memory requirement. For example, 26 embedding tables require 100+ GB memory when a single node is used for training. When we scale to 64 ranks using the solution described above, there is only a subset of one large table on every rank. With vertical split embedding, the feature size is 32 instead of 128 for single node training. So, we only need about 6 GB for 10 small embedding tables and a large embedding table with a subset of columns of the original large embedding table. Therefore, the vertical split embedding optimization is also a general solution to train workload with oversized embedding tables.
Large Batch Size DLRM BFloat16 Training with Split-LAMB Optimizers
To get better scaling efficiency, a layer-wise adaptive large batch optimization technique, called LAMB, is used to enable large batch-size training. We also use a split version of LAMB and SGD to leverage the BFloat16 Intel® DL Boost instruction. This allows scaling to 64 sockets and higher to reduce the TTT for DLRM training. A 32K global batch size is common for DLRM. When we scale to more ranks, the local batch size will be exceedingly small, which means that the local workload cannot saturate the processors. In this case, there is no opportunity to overlap between communication and computation. Therefore, we need to use a larger global batch size when scaling to more ranks.
SGD (stochastic gradient descent) is the default optimizer in the reference code of DLRM. It works well and converges in 0.75 epochs with 64K global batch size, but fails to converge at larger batch size (i.e., 256K). In our solution, we use LAMB (an Adam-based optimizer) to enable 256K global batch size training and achieve convergence in 0.8 epochs for DLRM training. LAMB stores the first- and second-order moments for every weight. Compared to the naïve SGD optimizer, LAMB needs 3x the memory footprint. DLRM is memory-bound because of the large embedding tables and because the gradients of the large embedding tables are sparse. To reduce the memory footprint, the LAMB optimizer is only used in the data parallel part of the computation. The sparse embedding table still uses the SGD optimizer.
We use the Intel DL Boost BFloat16 instruction to speed up DLRM training. Master weight is often used to maintain training accuracy with BFloat16. Master weight is a copy of Float32 weight stored in the optimizer to update weight, while a BFloat16 weight converted from master weight is also needed to forward and backward pass. It needs about 1.5x higher memory footprint compared to Float32 training and aggravates the memory bound nature of DLRM. In this part, we use the split optimizer to reduce the memory footprint of BFloat16 training (Figure 5). All inputs parameters in Scope I work with BFloat16 (which are truncated from corresponding Float32 parameters) at forward and backward training stages, and then are fed into BFloat16 operators (InnerProduct, EmbeddingBag) to leverage Intel DL Boost BFloat16. When running into parameter-update stage (SGD optimizer scope), it will pack BFloat16 data in Scope I, with another bottom half data in Scope II (which also exist with BFloat16) into full precision Float32 parameters and do normal calculation in Float32. After each update, it will split Float32 data back to separate BFloat16 representation in Scopes I and II. Hence, the Split-SGD doesn’t involve additional memory overhead for every weight. For Split-LAMB, we use the same method to pack and unpack weight and keep momentums in Float32.
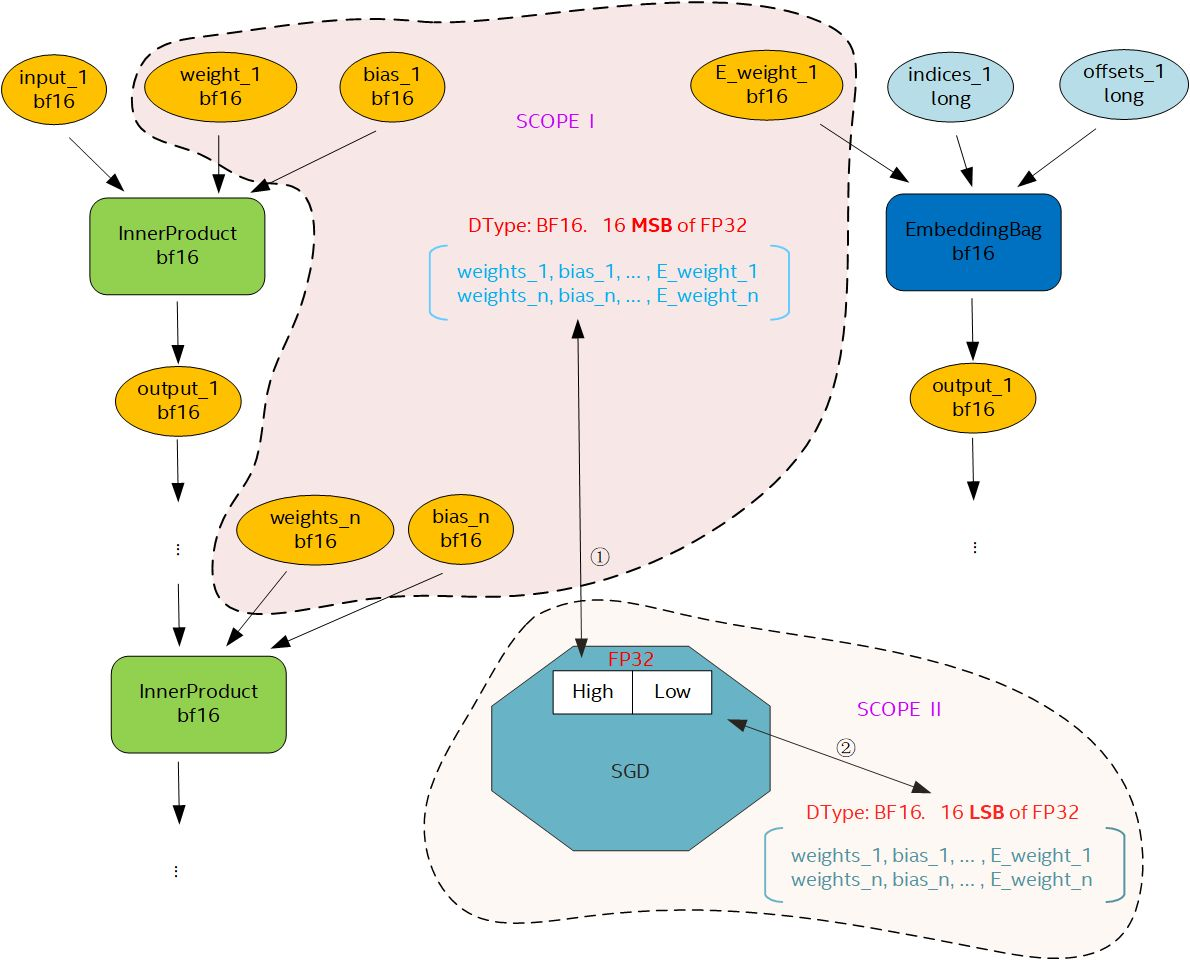
Figure 5. Split-SGD schematic diagram
Hyperparameter Optimization Powered by SigOpt
With this combination of innovative data and model parallelization, BFloat16 optimization, and new hybrid split-SGD and LAMB optimizers, it is crucial to run hyperparameter optimization to maximize performance against our metrics. Hyperparameter optimization can be time- and resource-intensive using traditional methods like grid search or random search. We apply a much more sample-efficient search method designed to find the optimal hyperparameters.
We used SigOpt, a leading experimentation platform that combines run tracking with scalable hyperparameter optimization for any type of model (e.g., deep learning, machine learning, high performance computing, and simulation). Acquired by Intel in October 2020, SigOpt allows for the use of any hyperparameter optimization (HPO) method with its scheduler (e.g., random search, grid search, and Bayesian optimization), but also offers a proprietary optimizer that combines the best attributes of a variety of Bayesian and global optimization algorithms. We found SigOpt’s optimizer performed best for our purposes.
DLRM training converges in a few iterations and reaches the 0.8025 AUC (area under curve) threshold for 256K global batch size (Figure 6). This exceeds the 0.75 AUC achieved for 32K global batch size. We can see that SigOpt quickly finds the hyperparameter set that meets the threshold and continues to improve beyond our threshold. SigOpt provides a variety of out-of-the-box visualizations, charts, plots, comparisons, and tables in a web dashboard. The SigOpt parameter importance analysis shows the critical parameters for our experiment (Figure 7).
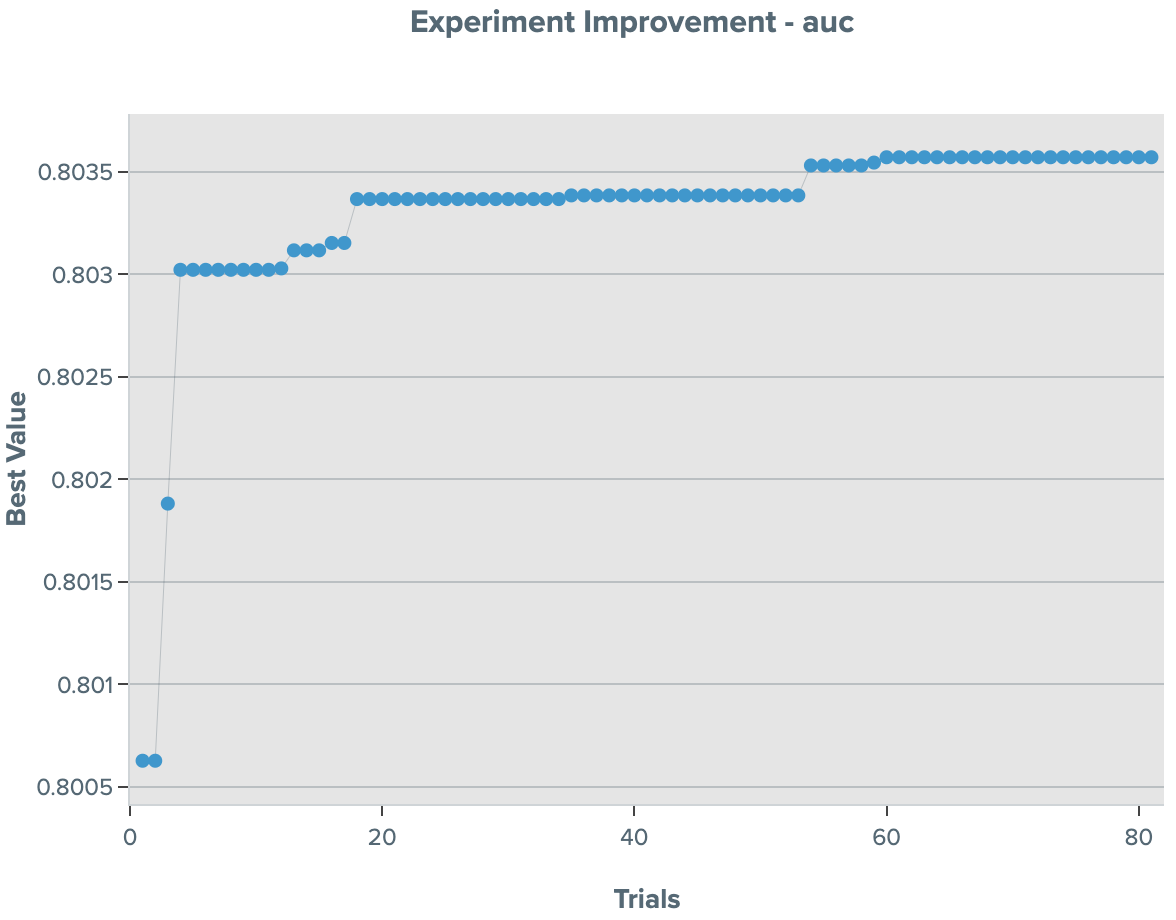
Figure 6. DLRM experiment improvement on AUC score
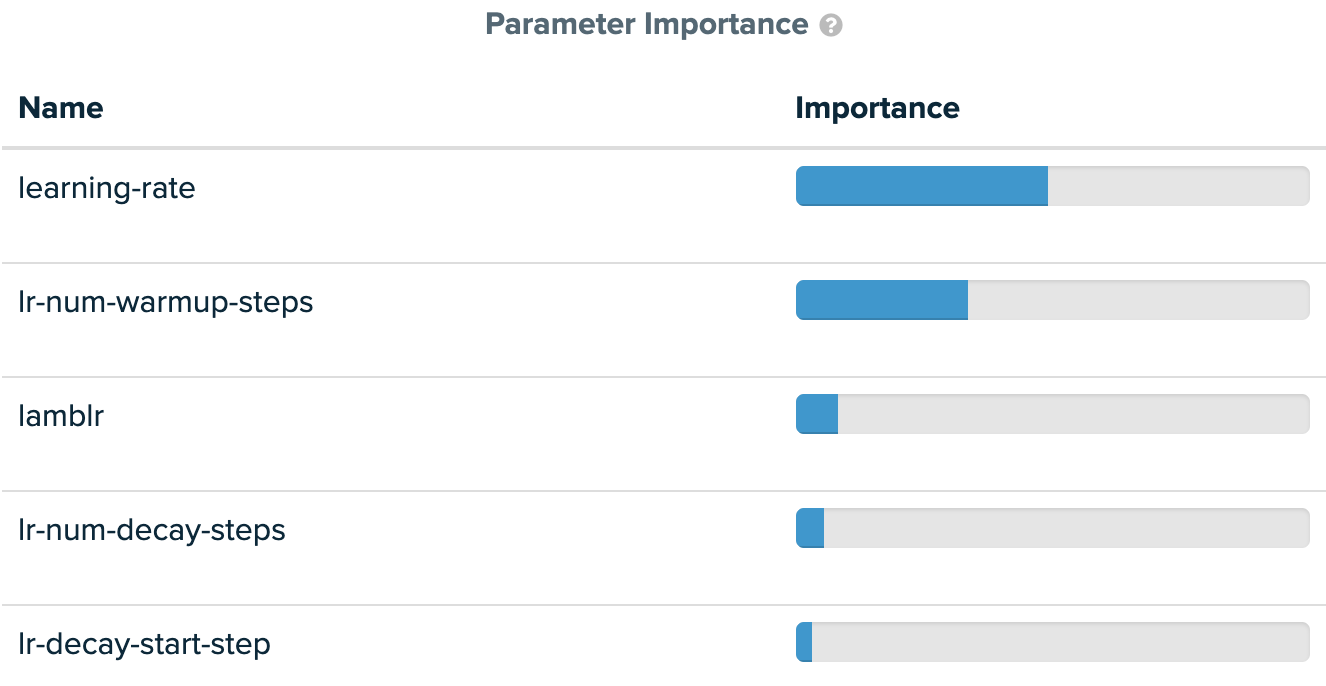
Figure 7. Parameter importance for DLRM
A Novel Model Parallel Friendly Data Loader
So far, we have described the vertical split embedding table to scale to more ranks and reduce memory footprint. A large global batch size with LAMB can also help to get better scaling efficiency, if everything goes well. A large embedding table needs to lookup global batch size entries with model parallelism, which means that we also need to read global batch size inputs from disk. Therefore, I/O is a potential bottleneck on multi-socket systems. A novel model parallel data loader is used to reduce this overhead. The loader will only read the local batch size inputs, which is a fraction of global batch size inputs, and use all-to-all communication to get global batch size inputs.
A terabyte dataset is used to train the MLPerf DLRM model. The data is row-major and contiguous in memory. There are 40 elements per sample (one label, 13 numerical features, and 26 categorical features) and every element uses four bytes. Numerical features work as inputs of bottom MLP (data parallelism), and categorical features work as inputs for embedding. (Small tables work with data parallelism, large tables work with model parallelism.) For a single-instance case, we need to read local batch size (LBS) samples for every iteration. If we just use the data parallel scale-out solution, every instance just reads LBS samples per iteration, but when we use the hybrid parallel approach, there is only local copy to part of the large embedding tables for every instance. So, global batch size (GBS) embedding indices are needed for large embedding tables in the current instance, and inputs data for every instance.
For LBS inputs, there are 26 categorical features for every sample, which means that the current instance not only reads LBS categorical features for its own large tables, but also LBS categorical features for other model instances. So, a naïve idea is that every instance only reads LBS samples per iteration and uses all- to-all communication to get GBS categorical features for large embedding tables (Figure 8). The inputs for every instance here mean the LBS categorical features for the large embedding tables in the first instance and all rank-0 will be integrated into GBS categorical features. Rank-1 means the LBS categorical features for the large embedding tables in the second instance, and so on. Before looking up embedding tables, all- to-all communication is used to collect GBS categorical features for every instance. If we use N instances, we can save (N-1)/N I/O bandwidth compared to the naïve data loader.

Figure 8. A novel model parallel friendly data loader. Every instance first reads LBS inputs, and then uses all-to-all to get GBS categorical features for the large embedding tables in the current instance.
Results
The DLRM scale-out solution is implemented using PyTorch, Intel® Extension for PyTorch (IPEX) , and Intel® oneAPI Collective Communications Library (oneCCL). We submit both closed division and open division MLPerf benchmarks (Figure 9). The closed division results (retrieved June 30, 2021) show that it takes about two hours to get convergence if we only use four sockets with 32K GBS on an Intel Xeon Platinum 8380H processor. When we used LAMB to enable 256K GBS and vertical split embedding table to scale to 64 sockets on an Intel Xeon Platinum 8376H processor, it only took 15 minutes to converge (open division results, retrieved June 30, 2021).
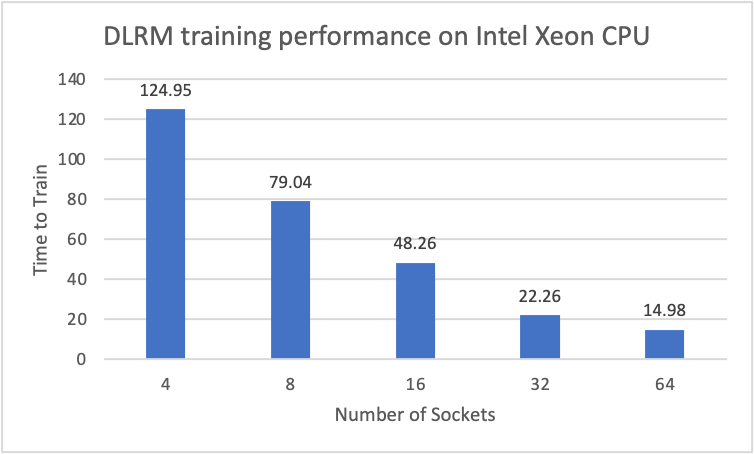
Figure 9. DLRM training performance for different numbers of sockets. We use one model instance (rank)/socket. The 4-, 8-, and 16-socket results were submitted to the MLPerf closed division. The 32- and 64-socket results were submitted to the open division.
Summary
For DLRM MLPerf training, we provide a complete scale-out training solution to resolve the challenge of balancing a mixture of compute-, memory-, memory capacity-, and I/O-bound work. First, we use hybrid parallel to reduce communication cost and memory consumption. Vertical split embedding tables not only helped us to scale to more ranks, it is also a fantastic solution to train any other workloads with oversized embedding tables. Second, a LAMB optimizer enables large batch size training to get better scaling efficiency. At the same time, split optimizer is also the overwhelming choice to leverage Intel DL Boost BFloat16 instruction for training. Finally, a novel model parallel data loader reduces the I/O bandwidth requirement. With this solution, you can train the DLRM MLPerf model in 15 minutes (or less if more sockets are used). At the same time, most techniques used in this article can be generalized to other distributed training approaches.
Related Content
Read
Optimize the Latest Deep-Learning Workloads Using PyTorch* Optimized by Intel
Watch
AI Analytics Part 1: Optimize End-to-End Data Science and Machine Learning Acceleration
Watch
Intel® oneAPI AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.