
It’s no secret: new hardware accelerators continue to emerge. Which means developers want to (frankly need to) take advantage of innovation across the spectrum of new hardware environments.
The software-execution flow employs more varied architectures; tasks are forked, spawned, and merged across these architectures.
In the easiest and most common scenario, a matrix-multiply-centric workload gets parallelized and offloaded to a dedicated GPU. However, already quite a few workloads take advantage of multiple diverse concurrent compute nodes. In 2021, an Evans Data Corporation report1 found that 40 percent of developers are already targeting heterogeneous systems that use more than one type of processor, processor core, or coprocessor to perform a given function.
Until recently, most developers were locked into a specific architecture, leading to the need to recode applications and use different libraries for each architecture they were targeting. Often, performance suffered due to the amount of code rework required to get the same functionality on different architectures.
Breaking these barriers are the oneAPI open, standards-based, multiarchitecture, multi-vendor programming model and complementary Intel® oneAPI Toolkits, purpose-designed to the use the C++/SYCL* abstraction layer and performance library APIs that stay consistent across architectures.
Using oneAPI the software-development paradigm changes and targeting and maintaining multiple execution environments for a given workload becomes more easily achievable; the developer can reuse their code across different architectures while still taking advantage of CPU, GPU, and FPGA hardware acceleration.
To help accelerate both the development time and performance of cross-platform applications, Intel is enhancing and extending their performance libraries by integrating SYCL and oneAPI cross-platform, standards-based technology.
Anchored in the LLVM Project with the Intel® oneAPI DPC++/C++ Compiler—a cross-platform compiler implementing C++, SYCL, and OpenMP*—and its rich family of performance libraries, Intel® oneAPI products and the underlying oneAPI open industry specification, offer three major benefits to the development community:
- Elimination of proprietary lock-in
- Realization of all the hardware value in each platform
- Ability to develop highly performant code quickly and correctly
All of this is available with full integration into common, integrated development environments like Microsoft Visual Studio*, Microsoft VS Code*, and Eclipse*.
Figure 1: Intel® oneAPI DPC++/C++ Compiler integration into Microsoft* Visual Studio* 2022
The Cross-Architecture Imperative for Libraries
Let’s turn attention to HPC, IoT, and AI.
In the heterogeneous environment, these use cases are ramping up in popularity with more accelerators targeting them and their challenges. Developers need the ability to take advantage of this increasingly diverse hardware. What is unclear is the cost of not supporting code across environments. Without portability, even the best code can get left behind. Code that is locked into a single architecture won’t be able to tap into future hardware advances and, thus, lose relevance to more portable alternatives.
The real roadblock to cross-platform development has been the lack of a unified set of libraries that can abstract architecture differences, enabling developers to reuse their code across these diverse architectures. With the right set of libraries they can choose platforms for the performance, price, availability, and/or any other factor rather than resigning to thinking, “Well, this is what my current code runs on.”
oneAPI’s family of performance libraries provides the answer to enabling this freedom of choice. They provide API-based, cross-architectural programming for fast time-to-market while maintaining or exceeding the performance achieved using C++ or SYCL alone.
Intel® oneAPI DPC++ Library (oneDPL)
oneDPL is the foundation of this new, common, API-based approach to software development. It complements the Intel oneAPI DPC++ Compiler by providing high-productivity APIs based on familiar standards, including the following to maximize productivity and performance across CPUs, GPUs, and FPGAs:
- C++ Standard Template Library (STL), which is verified for SYCL kernels
- Parallel STL (PSTL) algorithms with implementation policies to run on SYCL device architecture
- Boost.Compute
- SYCL
To pick a specific target architecture, simply pass a device selector to a task intended for parallelized offload to a SYCL queue sycl::queue.
There is a range of predefined device selectors that can be used directly:
|
default_selector |
Selects device according to implementation-defined heuristic or host device if no device can be found |
|
gpu_selector |
Select a GPU |
|
accelerator_selector |
Select an accelerator |
|
cpu_selector |
Select a CPU device |
|
host_selector |
Select the host device |
Table 1: List of predefined SYCL device selectors
(New devices can be derived from these with the help of a device selector operator. Please check out the oneAPI and SYCL spec for details.)
Using the device selector is then as easy as the example below:
The best way to take advantage of this approach without code redesign, and to future-proof your engineering investment for upcoming software architecture changes, is to build your workload software stack on well-established, high-performance libraries that have a proven track record of adopting the most current technology advancements.
It is important to note that Intel has opened its vast library of APIs and contributed many of them to the cross-platform oneAPI specification. This has also enabled the development of oneAPI libraries for other, non-Intel processor architectures. Specifically, oneAPI Level Zero opens the underlying programming model to encompass 3rd party device vendors and open, developer community engagement.
Intel® oneAPI Threading Building Blocks (oneTBB)
oneTBB, just like oneDPL, is based on well -established C++ standard compliant classes incorporating the latest in Parallel STL, an implementation of C++ standard-library algorithms with support for parallel execution policies.
As such, it is part of the oneAPI ecosystem, coexisting with oneDPL and augmenting its capabilities with a flexible performance library that simplifies the work of adding parallelism to complex applications. With its ability to simplify the optimization of parallel code execution flow across cores and architectures, oneTBB is widely used across many compute-intense domains in industry and research—numeric weather prediction, oceanography, astrophysics, genetic engineering, seismic exploration, automation energy resource exploration, and socioeconomics.
Rather than breaking up a program into functional blocks and assigning a separate thread to each, oneTBB emphasizes data-parallel programming, enabling multiple threads to work on different parts of a collection. This scales well to larger numbers of processors by dividing the collection into smaller pieces—program performance increases as processors and accelerators are added.
This design principle allows the library to be seamlessly compatible with other threading packages, enabling straightforward integration with oneAPI as well as legacy code.
Intel® oneAPI Math Kernel Library (oneMKL)
Also part of oneAPI, oneMKL is the continuation of the Intel® Math Kernel Library, the most widely used math library in the industry since 20151 . It covers a wide range of functionality used in math, science, and data analytics including linear algebra, Fast Fourier Transform, vector random number generation, statistics, vector math, and complex geometry (Figure 2).
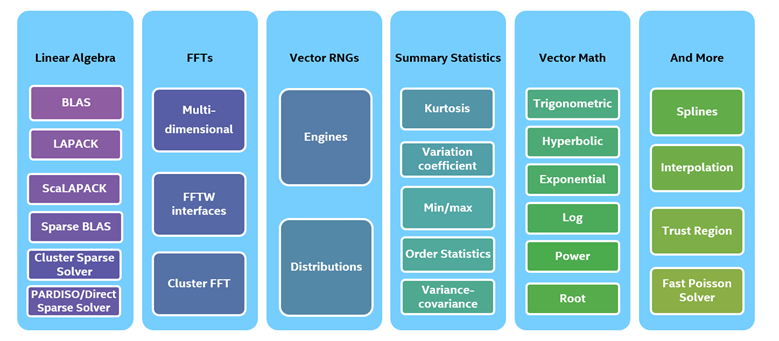
Figure 2: Intel® oneAPI Math Kernel Library Function Domains
Optimized for cross-architecture performance to enable complex math-processing routines that can be run on multiple architectures (CPUs, GPUs, etc.), oneMKL greatly simplifies the offloading of math functions to GPUs.
The new SYCL interfaces with optimizations for CPU and GPU architectures have been added for key functionality in the following major areas of computation:
- BLAS and LAPACK dense linear algebra routines
- Sparse BLAS sparse linear algebra routines
- Random number generators (RNG)
- Vector Mathematics (VM) routines for optimized mathematical operations on vectors
- Fast Fourier Transforms (FFTs)
In addition and in conjunction with SYCL interfaces, OpenMP offload can be used to run standard oneMKL computations on Intel® GPUs.
To take advantage of oneMKL together with the oneAPI SYCL interface, simply start by including both header files:
Then use the oneMKL library function calls exactly as before in the context of a given SYCL queue you define. No need to change anything beyond that to future-proof your library usage for upcoming GPUs and accelerators.
Detailed coding examples for API-based programming with oneMKL can be found inside the Intel® oneAPI Programming Guide and on GitHub.
Intel® Integrated Performance Primitives IPP
No overview of Intel’s comprehensive family of performance libraries is complete without Intel IPP, the extensive library of ready-to-use, highly optimized image, signal, and data-processing functions.
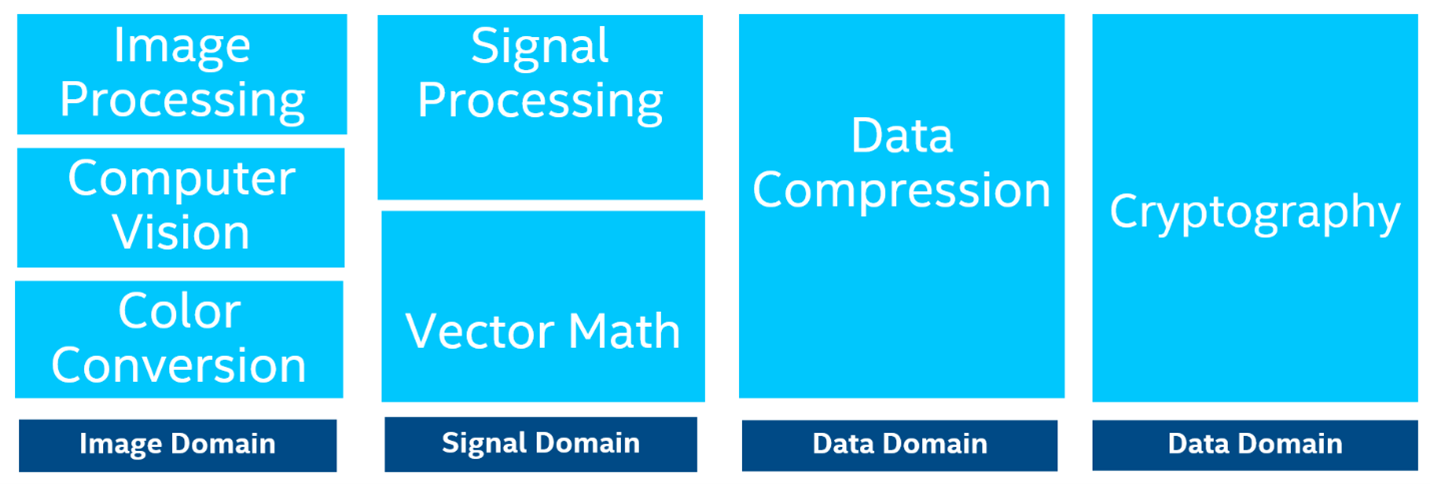
Figure 3: Intel® IPP Library Function Domains
Intel IPP is used for cloud and server applications, medical imaging, digital surveillance, biometric identification, wireless communications, and beyond.
Like the rest of Intel’s family of performance libraries, IPP maintains a stable API while also being constantly optimized and adapted for the latest architectural advances and improvements in parallel data and parallel execution flow.
Intel® oneAPI Video Processing Library (oneVPL)
Intel oneAPI not only is about open standards and freedom of choice when it comes to cross-architecture software development. It is also about getting the best performance out of the Intel GPUs in your system when it comes to media and video processing.
oneVPL is the successor to Intel® Media SDK (MSDK), and it takes you from integrated-graphics abstractions to media-feature unlocking on a much broader range of accelerators.
Here’s the short list of what it does:
- Provides backward-compatibility with the familiar MSDK core API
- Includes the same range of video codecs and filters as in the legacy toolkit
- Boosts media and video application performance with hardware-accelerated codecs and programmable graphics on Intel® processors
- Speeds the transition to higher frame rates and resolutions
- Improves video quality and innovate cloud graphics and media analytics
- For Intel® Core™ Gen12, Intel® Iris® Xe, and Intel® Arc series GPUs, oneVPL enables low latency synchronization and efficient zero-copy memory interop between oneVPL and system memory, Linux VA surfaces and buffers, DX9 surfaces, DX11 textures, and DX12 resources
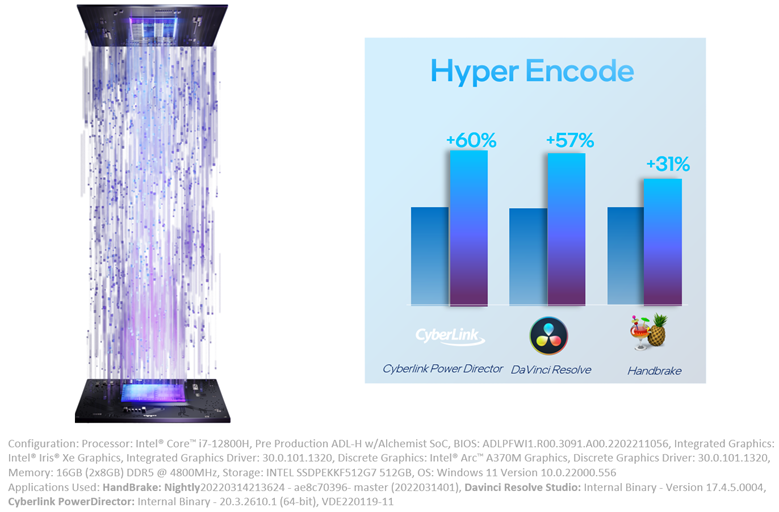
Figure 4: Hyper Encode with Intel® Deep Link Technology using oneVPL
Additionally, oneVPL’s use of Intel® Deep Link Technology speeds up encode significantly while taking advantage of the benefits of API based programming and thus reducing infrastructure and development costs.
Libraries for Heterogeneous Compute in AI
Beyond the family of highly performant libraries for cross-architectural compute, the oneAPI programming model spec also includes the following:
- Intel® oneAPI Deep Neural Network Library (oneDNN) is purpose-built for deep learning (DL) application and framework developers interested in improving application performance on Intel CPUs and GPUs. It continues to support features previously available including C and C++ interfaces, OpenMP, and oneTBB runtimes.
- Intel® oneAPI Collective Communications Library (oneCCL) helps optimize communication patterns to distribute deep learning model training across multiple nodes.
- Intel® Data Analytics Library (oneDAL) is a powerful library that provides highly optimized functionality and solvers to speed up the large dataset analytics algorithms underlying machine learning and deep learning applications.
These specification elements, along with their counterpart library implementations, provide the foundation for applying cross-architectural software development to AI and DL.
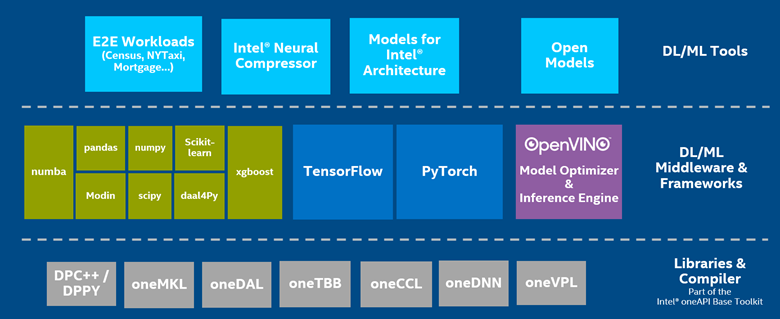
Figure 5: AI Software Stack and Intel® AI Analytics Toolkit
These additional capabilities in the Intel® AI Analytics Toolkit turn the Intel® oneAPI Base Toolkit from a comprehensive solution for cross-architectural software development into an AI training and inference toolkit powerhouse.
Open and Cross Platform Analysis and Debug Tools
The oneAPI libraries are part of the first comprehensive cross-platform solution that includes libraries, compilers, tools, performance analyzers, and debuggers.
For high-performance workloads that are designed to run on diverse heterogeneous platforms and are easy to maintain, they provide the glue of an API-based programming model that leads to an easily maintainable codebase.
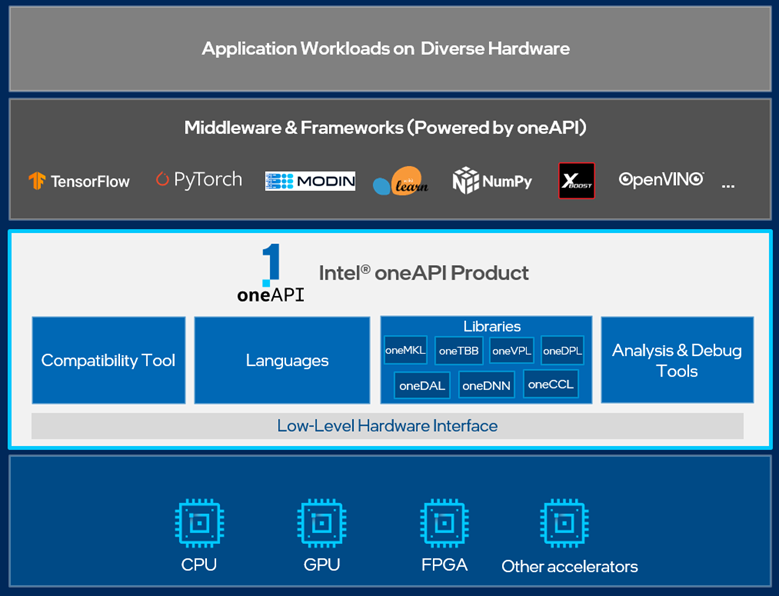
Figure 6: Intel® oneAPI Overview with Libraries
Applications that take advantage of the oneAPI programming model can execute on multiple target hardware platforms such as GPUs and FPGAs.
Just like parallel programming for homogeneous systems has become ubiquitous, we see parallel programming for heterogeneous systems on a similar path to being ubiquitous. Unlike multicore parallelism, heterogeneous programming will span compute capabilities from multiple vendors. Without a common, open, multivendor approach in libraries, compilers, and frameworks, this could threaten to fragment programming.
“We named this next generation of our popular tools to emphasize the oneAPI open approach to heterogeneous parallelism,” explains Reinders. “They remain [based on] the same quality product tools the industry has relied upon for decades, [while being] extended to support heterogeneous programming by embracing the oneAPI specification and SYCL standard.”
Just as Intel led the way with Intel® Parallel Studio, oneAPI takes parallelism a step further with highly optimized, multivendor libraries for math, neural networks, deep learning, rendering, and more. Each library’s standard primitives boost not just CPU code but expand into the world of multiple architecture for virtually all workloads and frameworks.
Does any developer really want three different sets of libraries, compilers, and debuggers?
Likely not.
oneAPI delivers efficiency because developers no longer need to waste time learning new tools simply because they have a heterogeneous environment.
The best part of all these new oneAPI tools? They are free to use and are supported by a multivendor organization to help ensure openness across architectures.
Get the Software
Take advantage of all the software in this article by downloading what you need (which might be all of them).
- Intel® oneAPI Base Toolkit, the foundational set of tools (15 and growing) including compilers, libraries, languages, frameworks, analysis & debuggers—for creating cross-architecture applications.
- Intel® AI Analytics Toolkit, helping developers achieve end-to-end performance for data science (AI/ML/DL) workloads.
Get Beta Access to New Intel® Technologies in the Cloud
If you would like to explore these tools in the cloud, sign up for an Intel® Tiber™ AI Cloud account—a free development sandbox with access to the latest Intel® hardware and oneAPI software.
Starting right now, approved developers and customers can get early access to Intel technologies—from a few months to a full year ahead of product availability—and try out, test, and evaluate them on Intel’s enhanced, cloud-based service platform.
The beta trial includes new and upcoming Intel compute and accelerator platforms such as:
- 4th Gen Intel® Xeon® Scalable Processors (Sapphire Rapids)
- Intel® Xeon 4th Gen® processor with high bandwidth memory (HBM)
- Intel® Data Center GPU codenamed Ponte Vecchio
- Intel® Data Center GPU Flex Series
- Intel® Xeon® D processors (Ice Lake D),
- Habana® Gaudi®2 Deep Learning accelerators
Registration and prequalification is required.
Visit Intel® Tiber™ AI Cloud to get started.
Conclusion
Tools and libraries to support building applications for heterogeneous environments are increasing in demand. Intel oneAPI tools and spec provides developers with a programming model to support code re-use across different architectures along with highly optimized libraries for common parallel workloads.
This ultimately improves both the efficiency of applications and the developer’s workflow. Developers can write code once, knowing that it can be run across different architectures depending on pricing, availability, and performance requirements.
Parallel programming is now ubiquitous in homogeneous systems, and the logical next step is to extend this to heterogeneous systems. This can only be achieved with tools like oneAPI that provide a layer of abstraction away from the complexities of different architectures.
See Related Content
On-Demand Webinars
- Launch Accelerated, Cross-platform AI Workloads in One Step
Watch - Compare CPU, GPU, and FPGA Benefits on Heterogeneous Workloads
Watch - Introduction to DPC++ Programming
Watch
Articles
- Expanding language and accelerator support in oneAPI
Read - More Productive and Performant C++ Programming with oneDPL
Read - Open DPC++ Extensions Complement SYCL* and C++
Read - Heterogeneous Processing Requires Data Parallelization
Read
Get the Software
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.