Steve Hikida, vice president and general manager of Compiler Engineering at Intel, and James Brodman, principal engineer of Compiler Engineering at Intel discuss the future of compilers.
Collectively, Steve and James have over 40 years of experience and influence in the realm (and art) of compiler technology. I was fortunate enough to sit down with both of them as a follow-up to their Innovation 2022 session (Next Generation Compiler Technology) to get their perspectives on how these fundamental tools of software development have evolved and where they're going next.
Compilers Make a Comeback
Don Badie: What's causing the renewed interest in compilers now?
Steve Hikida: In the last five years there's been a dramatic increase in complexity and diversity of modern hardware. To punctuate this, Intel recently launched the Intel® Max Series product family with two leading-edge products for HPC and AI: Sapphire Rapids and Ponte Vecchio.†
Many compilers are tailored to specific workloads and hardware platforms. To fully embrace the increased complexity and diversity of hardware and software frameworks used, it's important that compiler technology become more open, flexible, and transparent.
By the way, did you know that 2022 is Fortran's 65th birthday? Well, it's its commercial birthday, anyway—IBM* released it commercially in 1957. It's a language now, but it began its life as a "code interpreter," so it was essentially the precedent for the modern compiler.
† Author's note: Respectively, these are the Intel® Xeon® CPU Max Series and Intel® Data Center CPU Max Series.
Intel's Move to LLVM*
Don: You talked about more intelligence being added into compilers beyond updates that add performance and capture new language capabilities. Can you discuss an example?
Steve: Today's compilers have many optimization techniques. In the case of Intel's highly advanced compilers, there are many hundreds of optimizations. To achieve the ultimate performance, the challenges are which transformation to run in the optimization pipeline and how to tune those transformations via heuristics.
With millions of permutations, this is a daunting challenge. Choosing the right optimizations and heuristics for compiler transformations is often a game of best guesses, which leads to not optimal optimizations. This is where AI and machine learning can help identify the best choices for a specific source code. For example, AI can help identify the ideal heuristic and set of optimizations.
Another area that AI can help with is security. Today's security specialists use application security scanning tools to help identify security vulnerabilities within source code; this is a separate additional step to software development. As compilers adopt technologies like MLIR (multilevel intermediate representation), more information about the source language can be preserved, allowing security intelligence to automatically identify and remediate vulnerabilities during compile time.
Figure 1. Discussion on Intel's motivation for embracing LLVM*
Optimize a Parallel Simulation Platform
Don: You mentioned Intel's adoption of LLVM and move away from proprietary technology. You also talked about the benefits of modularization and other drivers, but two that caught my attention are the 12% to 18% faster compile times and, on some workloads, up to 65% faster binary performance. Are those typical gains? Under what circumstances?
Steve: Often we see organizations running on older compiler technology, as upgrading can be an afterthought. For instance, we just published a case study with Alibaba Cloud* and DP Technology. [Alibaba is a leader in cloud computing and AI; DP Technology* is a pioneer in AI and molecular simulation algorithms.] DP needed to run LAMMPS [Large-scale Atomic/Molecular Massively Parallel Simulator] workloads, which are particularly challenging due to their complex simulations and changing dynamics.
They chose Alibaba Cloud's Elastic High-Performance Computing [E-HPC], a cloud-native, full-stack, high-performance computing PaaS platform in China. DP originally compiled its LAAMPS workload on GCC* 10.2. Using the Intel® oneAPI DPC++/C++ Compiler and Intel® MPI library, they were able to improve performance by 16.2%. And that's just by recompiling with our latest compiler and adding a more optimized library.
After fine-tuning the process and thread combinations, they improved performance roughly 45.2% compared to GCC and MPICH.
You can see the results in Figure 2. Tencent* saw even higher gains, but I'll let James talk about that. Versus older, installed-base compiler technology, I would say that substantial gains are somewhat common, especially when both are compared on newer hardware where we've optimized for our latest compute capabilities.

Figure 2. A step-by-step performance improvement comparison of DP's LAMMPS workload running on Alibaba E-HPC (see the following configuration details).
Ready for Intel® Max Series Products
Don: When we talk about accelerator support, it's really timely this comes up with the launch of Intel® Max® Series product family and specifically the Intel® Data Center GPU Max Series. What are some of the things your team has done differently in the latest LLVM version of the compiler to support the Intel Max Series product family?
Steve: Intel® Max Series processors are outstanding accelerators for high-performance computing and AI workloads. We enabled many new compiler and runtime optimizations to achieve leadership performance for HPC and AI applications.
Prefetching, async offloading, atomic-free reduction support, optimal share-local memory, explicit SIMD, ND-range parallel execution, and native fast math are just a few examples.
All these capabilities will take advantage of the latest architecture and instruction-set advances like Intel® Xe Matrix Extensions.
We also enabled "standard"—meaning all middle-end—LLVM optimizations without loop optimizations such as in-lining, SROA [scalar replacement of aggregates], and GVN [global value numbering].
Offload onto FPGA
Don: Beyond GPUs, you also mentioned support for FPGAs. Since FPGAs have their own software stack [Open FPGA Stack], what support do Intel® oneAPI compilers offer there? And is this just a different route to program for Intel FPGAs or a better one?
Steve: Actually, it's a more approachable route to FPGA programming, particularly where the developers may not have experience with FPGAs. FPGAs are a great computing choice for select workloads in places like financial services.
A good example is covered in a joint story with Creative Solutions Space [CSS]. We talk about FPGAs having significant potential to lower overhead in financial services for tasks like Monte Carlo simulation and asset valuation. CSS chose Intel oneAPI DPC++/C++ Compiler running on the Intel® Tiber™ Developer Cloud for trial development of an FPGA solution.
This eliminated set up and configuration time and required no capital outlay on equipment like development tools and hardware. This allowed developers with no prior FPGA experience to write a functional proof-of-concept for a Monte Carlo acceleration library in a matter of days versus months, drastically shortening their time to market.
So an integrated compiler can save a lot of time for heterogeneous computing when moving to new platforms.
The Importance of an Open Ecosystem
Don: You said that openness was probably the most important factor, embracing community influence and contributions. What are some of the things Intel has been influenced by from community requests or contributions?
Steve: Actively participating and contributing with the open source communities like Clang*, LLVM, and SYCL* is very important to Intel. The communities have directly influenced and guided our technical roadmaps.
For example, identifying which new language features, compiler options, and optimizations are important to the community. They ensure we are focused on helping software developers be productive and maximize the exploitation of their systems.
Contributing back is equally important. Intel is among the top contributors to the Clang and SYCL communities.
James Brodman on Compiler Optimizations, SYCL*, and MySQL
Don: James, you talked about getting better performance: Up to 60% performance improvement over GCC or Open Source LLVM and up to 25% faster than classic Intel® C++ Compilers (figure 3). What are the most impactful things we do that contribute to this improvement?
James: The biggest source of "secret sauce" in Intel's compilers has always been our loop transformations and optimizations to enable vectorization. Loops are a fundamental building block of every program, doing the same operations over and over. So any way of more efficiently executing them can yield large dividends.
Our compilers must perform advanced analysis of the input code to determine that any optimizations we want to do are safe or, put another way, wouldn't result in an incorrect program. Vectorization goes together with optimizing loops since one way to get significant speedups is to execute multiple loop iterations in parallel by using SIMD vector instructions like Intel® Advanced Vector Extensions 512 (Intel® AVX-512).
The advanced analysis done in Intel compilers lets us vectorize more loops and codes that other compilers would not, and this is a big source of the performance gain over other compilers.
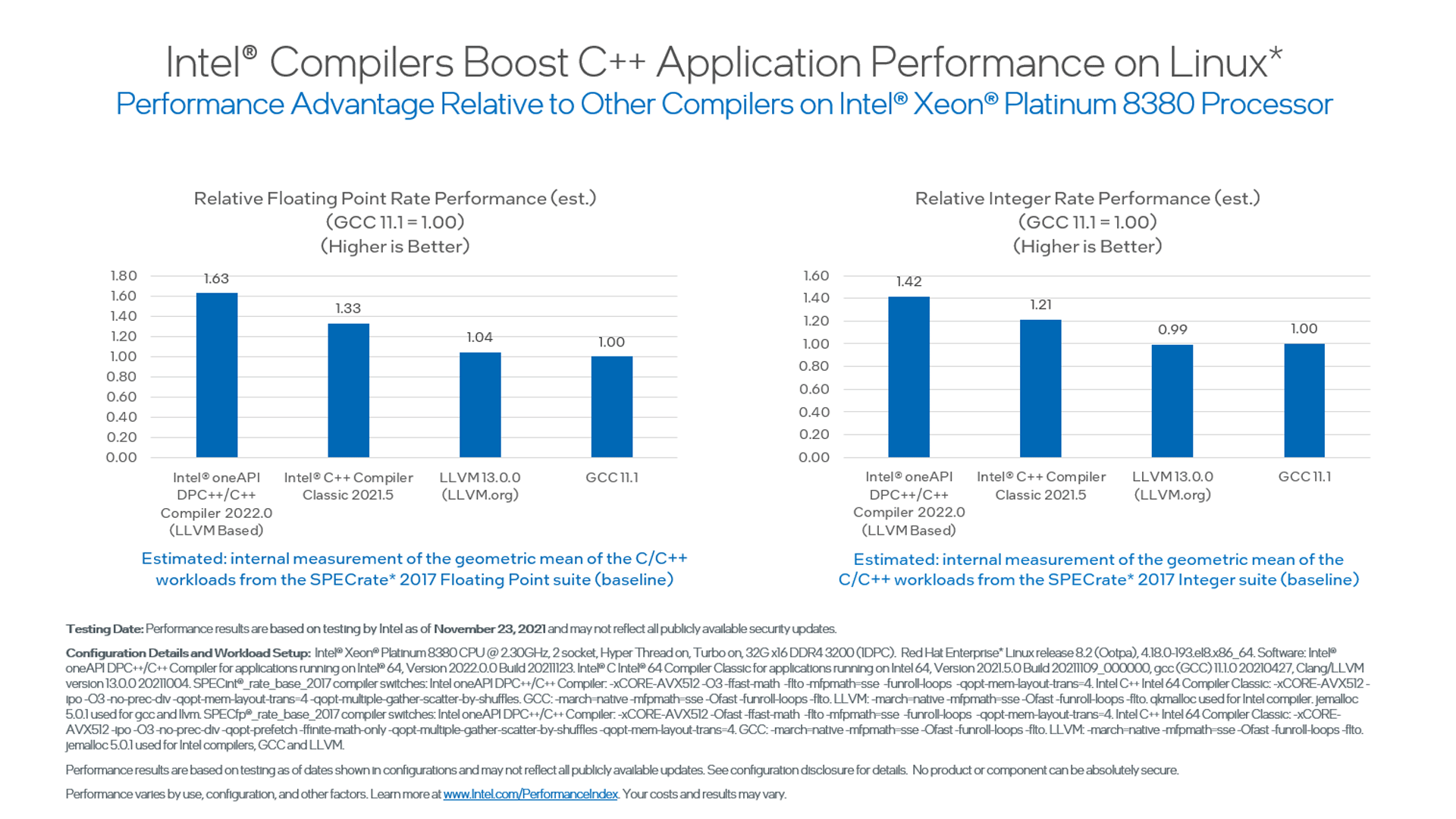
Figure 3. Intel DPC++/C++ Compiler performance comparisons
A great example is the improvement Tencent* experienced with its TencentDB for MySQL* database hosting service. Their service originally deployed with code compiled on GCC 10.2.0. After upgrading to our latest C++ compiler and using LTO and PGO optimization techniques, they were able to improve their performance an incredible 85% over its original, GCC compiled version. You can see the benchmarks below in figure 4.
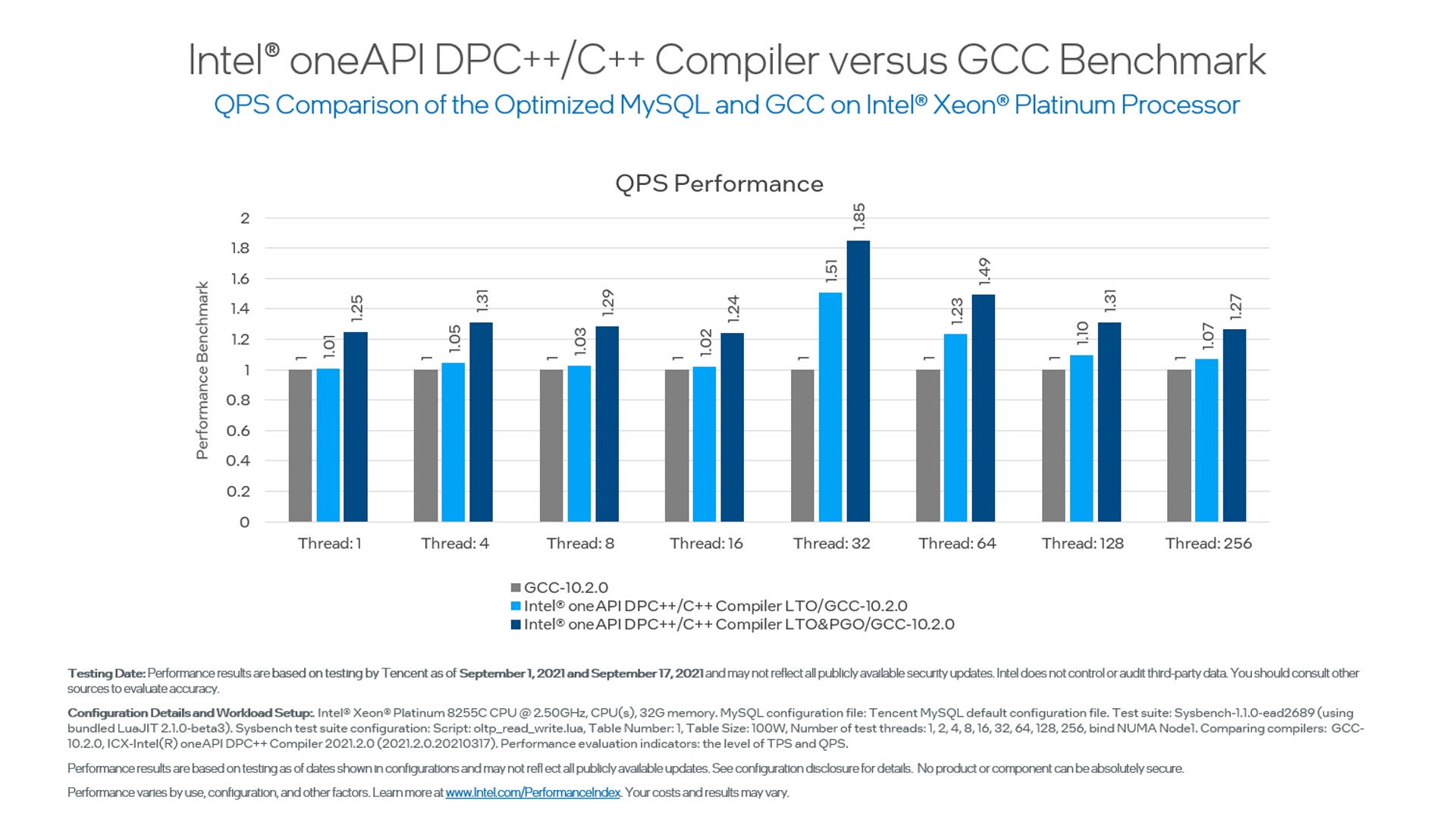
Figure 4. Tencent QPS comparison of optimized MySQL and GCC. The data source is from a Tencent internal evaluation.
Performance Optimization Methods
Don: You talked about optimization reports that can provide information on things like vectorization and details on things we can change in our code to get better performance. What are some tips you would offer on the most likely issues we see come up on these reports?
James: The optimization report is a great compile-time tool for finding potential performance hiccups in code. Examples can include unaligned memory accesses or nonlinear memory accesses. When code is vectorized, data is moved into and out of vector registers.
The compiler can generate more efficient code if the address of a load or store is a multiple of the vector register size. If the optimization report shows a large number of unaligned vector loads and stores, the programmer can modify the original code to change the allocation of arrays to be aligned to the vector register size. For example:
- 32 bytes for Intel® Advanced Vector Extensions 2 (Intel® AVX2)
- 64 bytes for Intel AVX-512
Nonlinear memory accesses can lead to a similar speed bump: If different loop iterations access the elements of an array one after another, the compiler can generate a vector load or store instruction. However, if successive iterations access arbitrary elements of an array, the compiler may have to generate what are called gather or scatter instructions, and these are much more expensive than vector loads or stores. In this case, the programmer can try things like reordering loops or even changing data structure layouts to ones that are more amenable to vectorization. Transforming arrays of structures to structures of arrays is a common transformation one may do.
Optimization Reports & Intel® VTune™ Profiler
Don: When do you think it's worthwhile to move from just an optimization report to a more robust analyzer like the Intel® VTune™ Profiler? Is that always worthwhile, or is the optimization report sometimes enough?
James: The optimization report is a great source of static information about your program; that is, the things that the compiler always knows about your program when it compiles your code.
Intel® VTune™ Profiler is a great tool for looking at dynamic information about your program while it executes. The compiler can't always tell how big an array is or what values data may have that could affect which branch in code is taken. When you need to examine the performance of your program based on this dynamic information, Intel VTune Profiler is absolutely the right tool for the job. I’d say they're complementary to each other.
Don: For a new developer, where would you start?
James: The first and best place to start is using Intel Tune Profiler to look for hot spots in your code. You can look at the performance report that will highlight those time-consuming portions. Step one is to know where to put the effort. There's definitely an 80/20 rule in programming, where 20% of the code can be responsible for 80% of the program performance.
Don: You talked about things like IVDEP and RESTRICT that can provide the compiler guidance to augment auto-vectorization with user-guided techniques. For those of us who are new to parallel programming, where should we start with user-guided vectorization?
James: The thing to keep in mind about vectorization (and all optimizations, really) is that the compiler cannot break your code. Any transformation it does must be legal and not break the program's expressed semantics. This means that compilers must be conservative when performing optimizations.
One example is that if a function takes two pointers, the compiler will assume that the pointers may alias each other; that is, they may point to the same location (or part of the same location) in memory. If the pointers really do overlap, vectorization would not be safe because a vector instruction could overwrite a value before it had been correctly read.
However, much of the time the programmer knows that two pointers don't alias or overlap at all. In these circumstances, the programmer can give the compiler a hint. These hints can come in different forms.
One example is #pragma ivdep. This pragma tells the compiler to ignore all assumed vector dependencies. It's a blunt hammer, but it gets the job done. Another is the restrict keyword, which is more of a scalpel; when the programmer annotates a pointer with restrict, it tells the compiler that this pointer does not alias with any other pointer. The more information you give the compiler, the better job it can do for you.
Don: You discussed a focus on prototyping new features that will be useful for new versions of SYCL. Are there any particular challenges Intel is working on addressing here?
James: There are several things in the works.
First, we've been working on defining a graph API for SYCL. Graph APIs can be very useful for reducing the runtime overhead in a program when offloading to the GPU. In particular, instead of submitting a well-known sequence of kernels one at a time, we can give a bigger chunk of work to the lower-level GPU runtime at once, saving us several round trips from the application into the runtime and back.
We are also working on improving support when working with images in SYCL, adding conditional feature use on supported devices, adding device global variables, and making improvements to local memory and group algorithm handling. Fundamentally, we want to make simple things simple to express while extracting all the performance a device can deliver.
Figure 5. SYCL–Supporting an open industry standard for accelerated computing support
Adopt Multi-Level Intermediate Representation (MLIR) for Compilers
Don: When and how do you see MLIR showing up in mainstream compilers in general?
James: I think we're already seeing it show up in newer domain-specific compilers for things like machine learning.
Newer projects like Flang are also using MLIR, but Flang is still in its early days compared to Clang. The challenge with adopting MLIR into existing projects is figuring out how the architecture needs to adapt to best use it. The Clang C/C++ front end was designed around the LLVM compiler back end. Clang generates LLVM IR from its AST [Abstract Syntax Tree].
To adopt MLIR, Clang needs to figure out what dialects of MLIR need to sit between the AST and LLVM IR. Earlier this year, engineers from Meta proposed a start to these discussions on the Clang mailing list, but this is an ongoing effort that will require the input and collaboration of the entire Clang community over a few years.
Additional Resources
Technical Articles and Blogs
- Tencent Gains Up to 85% Performance Boost for MySQL Using Intel® Tools
- Get to Know Intel's LLVM-Based oneAPI Compilers
- SIMD vectorization in LLVM and GCC for Intel CPUs and GPUs
On-Demand Webinars
- Get Started with the Latest LLVM-based Compilers from Intel
- Floating-Point Math and Intel Compilers
- Intel® oneAPI DPC+/C+ Compiler Pragmas & Intrinsics
Get the Software
Test out Intel compilers for yourself today by getting them as part of the Intel® oneAPI Base Toolkit.