oneAPI greatly simplifies development on heterogeneous accelerators. With a code once, run anywhere approach, the APIs offer a powerful way to develop code. ArrayFire is a GPU library that already offers a vast collection of useful functions for many computational domains. It shares the philosophy oneAPI brings to the software development world. In this article, we’ll be exploring how to integrate the oneAPI Deep Neural Network (oneDNN) library and the SYCL-based Data Parallel C++ (DPC++) programming language into existing codebases. Our goal is to allow the programmer to take advantage of oneAPI to avoid the code rewriting often required when migrating to a new programming model.
Interoperability with SYCL
oneAPI is the combination of DPC++ and libraries to simplify cross-architecture parallel programming. The libraries are tightly integrated with the DPC++ language. They both provide a variety of methods for interoperability with the underlying OpenCL implementation. The base language provides three main methods of interoperability with OpenCL that cover most use-cases (Figure 1). The flow of interoperability functions can be from existing code to SYCL or vice versa, specifically:
- Using existing OpenCL kernels within DPC++ code by creating a kernel object from the kernel string
- Extracting OpenCL objects from existing SYCL objects
- Creating SYCL objects from existing OpenCL objects
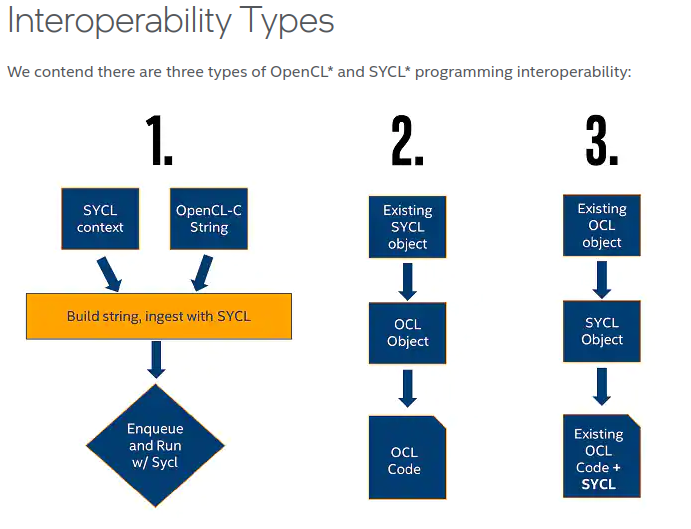
Figure 1. SYCL interoperability with OpenCL
Let’s consider how the existing ArrayFire codebase could be integrated with these interoperability options. In the first case, we could directly reuse the raw ArrayFire kernels (Figure 1, left):
queue q{gpu_selector()}; // Create command queue targeting GPU
program p(q.get_context()); // Create program from the same context as q
// Compile OpenCL vecAdd kernel, which is expressed as a C++ Raw String as indicated by R”
p.build_with_source(R"( __kernel void existingArrayFireVecAdd(__global int *a, __global int *b, __global int *c)
{
int i = get_global_id(0);
c[i] = a[i] + b[i];
} )");
// buffers here ...
q.submit([&](handler& h) {
// accessors here...
// Set buffers as arguments to the kernel
h.set_args(A, B, C);
// Launch vecAdd kernel from the p program object across N elements.
h.parallel_for(range<1> (N), p.get_kernel("vecAdd"));
});
In reality, ArrayFire kernels rely on more complicated data structures than simple buffers so reusing kernels in this manner isn’t as trivial as copy-pasting the CL string. We’ll need to handle the data exchange using one of the other two methods.
The second method (Figure 1, middle) of extracting OpenCL components from SYCL objects is based on the simple convention of using the .get() method on existing SYCL objects. Each call on a SYCL object will return the corresponding underlying OpenCL object. For example, cl::sycl::queue::get() will return an OpenCL cl_command_queue.
The third method (Figure 1, right) takes existing OpenCL objects and uses them to create SYCL objects. This can be done using the SYCL object’s constructors, such as sycl::queue::queue(cl_command_queue,…). In these cases, the constructors will also retain the OpenCL instance to increase the reference count of the OpenCL resource during construction and will release the instance during the destruction of the SYCL object.
Interoperability with oneAPI Libraries
Similar interoperability conventions exist within the oneAPI libraries. Some of the libraries, like oneMKL, directly rely on the DPC++ interoperability. Their functions can accept unified shared memory (USM) pointers. Others, like oneDNN, which we will be using in our example, provide similar .get() and constructor() mechanisms.
oneDNN has similar, yet slightly different data structures from DPC++. The sycl::device and sycl::context are combined into a single dnnl::engine object, and the dnnl::stream replaces the sycl::queue. Despite these differences, the mechanism for OpenCL interoperability remains the same. OpenCL objects can be obtained with getter functions while new oneDNN objects can be created from existing OpenCL objects through their constructors. oneDNN also provides an explicit interoperability header with the same functionality.
oneDNN is flexible in terms of its supported runtime backend. It can use either the OpenCL runtime or the DPC++ runtime for CPU and GPU engines to interact with the hardware. Developers may need to use oneDNN with other code that uses either OpenCL or DPC++. For that purpose, the library provides API extensions to interoperate with the corresponding underlying objects. Depending on the target, the interoperability API is defined in either the dnnl_ocl.hpp or dnnl_sycl.hpp header. For our usecase, we’re interested in supplementing the capabilities of oneDNN’s inference engine with the existing preprocessing capabilities offered by the ArrayFire library. For now, this will be done through the OpenCL interoperability functions.
ArrayFire and oneDNN: The Details
The motivating example we’ll be using to explore the details of OpenCL interop with oneDNN is based on the cnn_inference_f32.cpp sample. This example sets up an AlexNet network using oneDNN for inference. Our goal is to use ArrayFire’s many OpenCL image processing functions to preprocess the user input images before feeding the data to the existing inference engine. The full workflow involves the following steps:
- Include the relevant interoperability headers
- Create a GPU engine while sharing the cl_context with ArrayFire
- Create a GPU command queue via the OpenCL interoperability interface
- Perform preprocessing and data preparation with ArrayFire
- Create a GPU memory descriptor/object
- Access GPU memory via OpenCL interoperability interface for input
- Create oneDNN primitives/descriptors/memory to build the network
- Execute the network as usual with oneDNN
- Release GPU memory
The first additions we need to make to the file include the interoperability headers for both ArrayFire and oneDNN. The OpenCL headers are included as well.
#include "oneapi/dnnl/dnnl.hpp" // oneDNN header
#include "oneapi/dnnl/dnnl_ocl.hpp" // oneDNN OpenCL interop header
#include <CL/cl.h> // OpenCL header
#include <arrayfire.h> // ArrayFire header
#include <af/opencl.h> // ArrayFire OpenCL interop header
Next, we’ll grab the OpenCL context and queue from ArrayFire to share with oneDNN:
cl_device_id af_device_id = afcl::getDeviceId();
cl_context af_context = afcl::getContext();
cl_command_queue af_queue = afcl::getQueue();
The OpenCL objects will be used to create the corresponding oneDNN objects. This will use the interoperability functions defined in the interop header. These functions reside in the additional ocl_interop namespace. Remember that this will retain the objects throughout the lifetime of the oneDNN scope:
dnnl::engine eng = dnnl::ocl_interop::make_engine(af_device_id, af_context);
dnnl::stream s = dnnl::ocl_interop::make_stream(eng, af_queue);
Then we can load and preprocess our images reusing the ArrayFire library’s accelerated GPU functions:
// create empty array within same context as oneDNN
af::array images = af::constant(0.f, h, w, 3, batch);
images = read_images(directory);
images = af::resize(images, 227, 227) / 255.f; // resize to alexnet input size
// and normalize [0-1]
images = af::reorder(images, 3, 2, 0, 1); // hwcn -> nchw
... // additional preprocessing
oneDNN finally requires the dnnl::memory object. This isn’t raw memory, but rather some memory together with additional metadata such as a dnnl::descriptor. oneDNN supports both buffer and USM memory models. Buffering is the default. To construct a oneDNN memory object with interop support, we will use the following interop function:
ocl::interop make_memory(
const memory::desc& memory_desc, // descriptor describing memory shape and layout
const engine& aengine, // our interop engine
memory_kind kind, // buffer or USM
void* handle = DNNL_MEMORY_ALLOCATE // handle to underlying storage
)
Here, the descriptors follow those of the sample where we expect the input to AlexNet to be a 227 x 227 NCHW image. The engine is just our execution engine that we have been sharing between ArrayFire and oneDNN. The memory kind should specify if we’re using the USM or buffer interface. If we chose to pass in a handle pointer, it should then proceed to match the type of memory we pass in. If the handle is a USM pointer or an OpenCL buffer, the oneDNN library doesn’t own the buffer and the user is responsible for managing the memory. With the special DNNL_MEMORY_ALLOCATE value, the library will allocate a new buffer on the user’s behalf.
oneDNN supports both buffer and USM memory models, so replacing the engines and queues with objects shared with ArrayFire will result in incompatible memory creation modes. During the creation of the dnnl::memory object, the following error can occur:
oneDNN error caught:
Status: invalid_arguments
Message: could not create a memory object
Instead of the default method of dnnl::memory creation, the interoperability functions must be used instead, as follows:
cl_mem *src_mem = images.device<cl_mem>(); // get cl_mem from arrayfire
dnnl::memory user_src_memory = ocl_interop::make_memory( // interop mem function
{{conv1_src_tz}, dt::f32, tag::nchw}, // create descriptor
eng, // specify engine
ocl_interop::memory_kind::buffer, // specify memory type
*src_mem); // pass cl_mem handle
This applies all instances of default dnnl::memory allocation. The interoperability functions to specify the ocl_interop::memory_kind::buffer must be used:
ocl_interop::make_memory(descriptor, engine, ocl_interop::memory_kind::buffer);
Finally, after all weights are loaded, the inference primitives can be created and called as usual. After the network has run, we should free the resources that we are responsible for:
// additional alexnet network setup
// loading of weights following cnn_inference_f32.cpp
...
// execute all primitive steps for full inference using our inputs
for (size_t i = 0; i < net.size(); ++i) {
net.at(i).execute(s, net_args.at(i));
}
s.wait(); // wait until stream finishes writing to memory
images.unlock(); // return memory ownership to arrayfire to free resources
We want to make sure we’re running oneDNN with the OpenCL runtime rather than the DPC++ runtime. This can be achieved by specifying the SYCL_DEVICE_FILTER=opencl environment variable. A modified, working cnn_inference_f32.cpp for reference can be found in this gist.
Conclusion
oneAPI provides all the tools required to integrate existing OpenCL codebases with the new heterogeneous programming approach. The underlying OpenCL objects can be shared in either direction with DPC++. oneAPI’s libraries have their own methods to handle the interoperability tasks. With minor code changes, whole OpenCL libraries can be reused rather than rewritten. oneAPI saves future development time by avoiding redevelopment efforts of already useful code.