Deep learning AI models have grown immensely in the last decade, and along with this rapid growth is an explosion in compute resource requirements. Every larger model requires more computational resources and more movement of bits, both in and out of various memory hierarchies and across systems.
Sustainable AI and Why Deep Learning Optimizations Matter To Me
In January 2020, Wired published this piece, AI Can Do Great Things – If It Doesn’t Burn the Planet. More recently, MIT Technology Review penned an article, These Simple Changes Can Make AI Research More Energy Efficient, about how the Allen Institute for AI, Microsoft, Hugging Face, and several universities partnered to understand how to reduce emissions by running workloads based on when renewable energy is available. I’ve spent some time thinking about sustainable AI and discussed a few software/hardware alternatives to traditional, deep learning neural networks in a previous article on AI Emerging Technologies to Watch. Although I didn’t frame that article around sustainability, all of those technologies have a chance to solve similar problems as deep learning models in specific domains, while significantly reducing the amount of compute power used to arrive at those solutions.
The wonderful thing about optimization of models is that it not only increases performance but also reduces cost and the amount of energy used. By leveraging some of the techniques below, we get the wonderful intersection of solving interesting problems faster, cheaper, and in a more sustainable way.
Common Deep Learning Optimizations
Knowledge Distillation
As the name suggests, the goal of knowledge distillation is to take functionality from one model and move it into another. By leveraging a model that is already a working solution to a problem, we can create a similar, less complex model that can perform the same task. Obviously, the smaller model must perform with similar accuracy to be a successful distillation. In many recent publications on the topic, a teacher/student analogy is used to describe how knowledge distillation learning models work. There are three different ways that the larger teacher model is used to help train the smaller student model: response-, feature-, and relation-based knowledge (Figure 1).
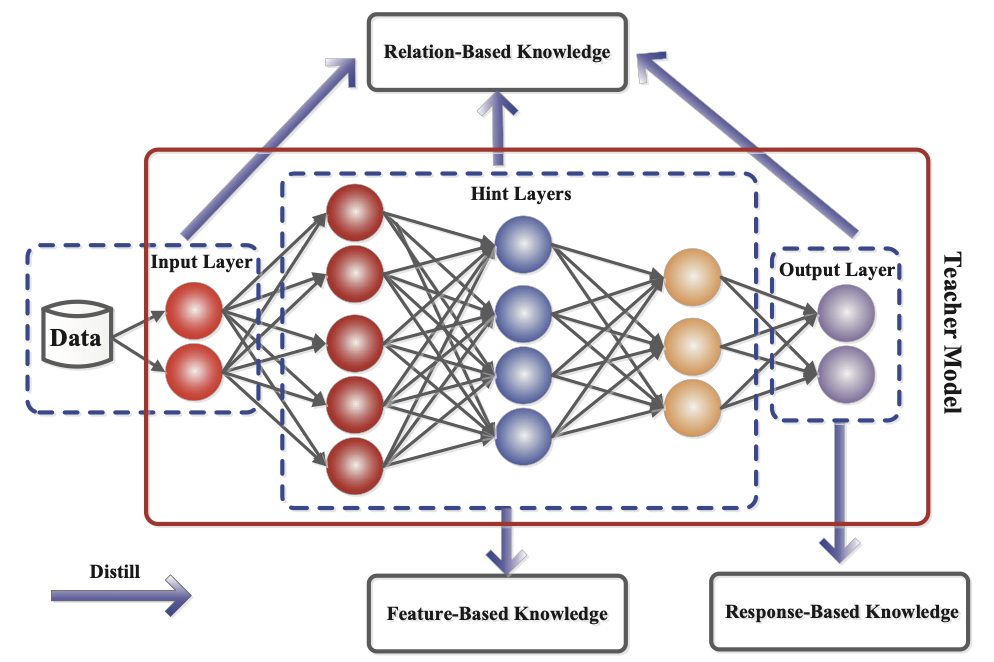
Figure 1. Where does our knowledge come from?
(Source: Knowledge Distillation: A Survey)
Response-based knowledge helps train the student model by looking at the output of the teacher model. This is probably the most common-sense way to create a smaller model. We take the larger model output and try to get the same output behavior on our smaller model based on the same or similar input.
Feature-based knowledge helps train the student model by attempting to have the intermediate layers mimic the behavior of the teacher model. This can be difficult because it is not always easy to capture the intermediate feature activations of the model. However, a variety of work has been done in this area to capture the behavior of the intermediate features, which has made such feature-based knowledge distillation possible.
Relation-based knowledge transfer is based on the idea that in the teacher network, the outputs of significantly different parts of the network may work together to help drive the output. This is a little less intuitive to define an algorithm to help train, but the basic idea is to take various groups of nodes, commonly known as feature maps, and train the student nodes to provide similar output as the feature maps in the parent.
Through a combination of these three techniques, it has been shown that some very large models can be migrated to smaller representations. Probably the most well-known of these is DistilBERT, which is able to keep “97% of its language understanding versus BERT while having a 40% smaller model and being 60% faster.”
Quantization
Perhaps the most well-known type of deep learning optimization is quantization. Quantization involves taking a model trained using higher precision number formats, like 32- or 64-bit floating point representations, and reproducing the functionality with a neural network that uses lower precision number formats, typically an 8-bit integer (INT8). There are a few approaches to quantization. One can perform quantization after the initial model is trained. The subsequent INT8 model can then be computed by scaling the weights within the original model to generate a new model. This has the benefit of being able to run against existing models that you are trying to optimize after fine-tuning them. Another option is to include quantization techniques as part of the initial training process. This process often creates an INT8 model with greater accuracy versus the post-trained, computed INT8 model method, but at the cost of upfront complexity when creating your model training system.
In both of these cases, the result of using an INT8 representation provides significant savings in terms of model size, which translates into lower memory and compute requirements. Often this can be done with little or no loss of accuracy as documented on the official TensorFlow Quantization Aware Training site.
Making Optimizations Easier
As one might imagine, these simple descriptions of how to create smaller, but still efficient, models require a variety of complex real-world solutions to properly execute them. There are a significant number of research papers devoted to these topics, and a significant amount of research has gone into approaches that can generalize these solutions. Both TensorFlow* and PyTorch* provide some quantization APIs to simplify the quantization process. Keras has a nice TensorFlow example at Knowledge Distillation. For PyTorch, there’s a nice Introduction to PyTorch Model Compression Through Teacher-Student Knowledge Distillation, although the example code is a little bit older.
As you can imagine, combining these techniques to generate an optimized model is not always a straightforward task. To help provide a simplified workflow for model optimization, Intel recently released the Intel® Neural Compressor as part of the Intel® AI Analytics Toolkit. This open-source, Python library for CPU and GPU deployment simplifies and automates a significant amount of the setup and process around performing these optimizations. Because it supports TensorFlow, PyTorch, MXNet*, and ONNX, this library should be able to help quickly migrate many larger models into smaller, more optimized models that require fewer hardware resources.
Editor’s note: For more information on how you can leverage this library in PyTorch, check out “PyTorch Inference Acceleration with Intel Neural Compressor” in this issue of The Parallel Universe.
There are other alternatives as well, depending on your use-case and what frameworks you are already using. For example, if you happen to be using something like OpenVINO™, you can leverage the framework’s associated solutions: Neural Network Compression Framework and Post-training Optimization Tool. Obviously, your best option is to use a tool that is tied to whatever framework or SDKs you are already using.
Conclusion
Deep learning models are a vital component of solutions across a large number of industries. As this trend continues, model compression and optimization are critical to reducing the size of models to enable them to run faster and more efficiently than before. These techniques provide a scalar reduction in the amount of energy used but, at their core, the end solution is still a neural network. As a community, it is both an incredible challenge and an imperative that we find more ways to reduce energy usage while simultaneously driving innovation. Looking to the future, I am hopeful to see if and how the paradigms shift to enable us to continue to leverage AI, but with an exponential reduction in compute and energy usage.
See Related Content
Technical Articles
- PyTorch Inference Acceleration with Intel Neural Compressor
- Accelerating PyTorch with Intel Extension for PyTorch
- Optimizing End-to-End Artificial Intelligence Pipelines
- PyTorch Inference Acceleration with Intel® Neural Compressor
- How to Accelerate TensorFlow on Intel® Hardware
Blogs
On-Demand Webinars & Workshops
- Optimize Data Science & Machine Learning Pipelines
- Accelerate AI Workloads with Intel® Optimization for PyTorch
- Accelerate AI Inference without Sacrificing Accuracy
Get the Software
Intel® AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now
See All Tools