In this video, Intel Cloud Software Engineer Ben Olson demonstrates how to accelerate deep learning inference by applying default optimizations in TensorFlow* for Intel hardware and quantizing to INT8.
When deploying deep learning models, inference speed is usually measured in terms of latency or throughput, depending on your application’s requirements. Latency is how quickly you can get an answer, whereas throughput is how much data the model can process in a given amount of time. Both use cases benefit from accelerating the inference operations of the deep learning framework running on the target hardware.
Engineers from Intel and Google have collaborated to optimize TensorFlow* running on Intel hardware. This work is part of the Intel® oneAPI Deep Neural Network Library (oneDNN) and available to use as part of standard TensorFlow. The demo shows that in addition to importing standard TensorFlow, you only need to set one environment variable to turn on these optimizations:
export TF_ENABLE_ONEDNN_OPTS=1
Note that in TensorFlow 2.9, these optimizations are on by default and this setting is no longer needed.
The oneDNN optimizations also take advantage of instruction set features such as Intel® Advanced Vector Extensions 512 (Intel® AVX-512), and Intel® Advanced Matrix Extensions (Intel® AMX).
This demo shows deep learning inference in TensorFlow using a ResNet-50 model and a synthetic dataset running on an AWS m6i.32xlarge instance with an Intel® Xeon® Platinum 8375C CPU running at 2.90GHz and 512GiB of memory. This supports Intel AVX-512 VNNI instructions.
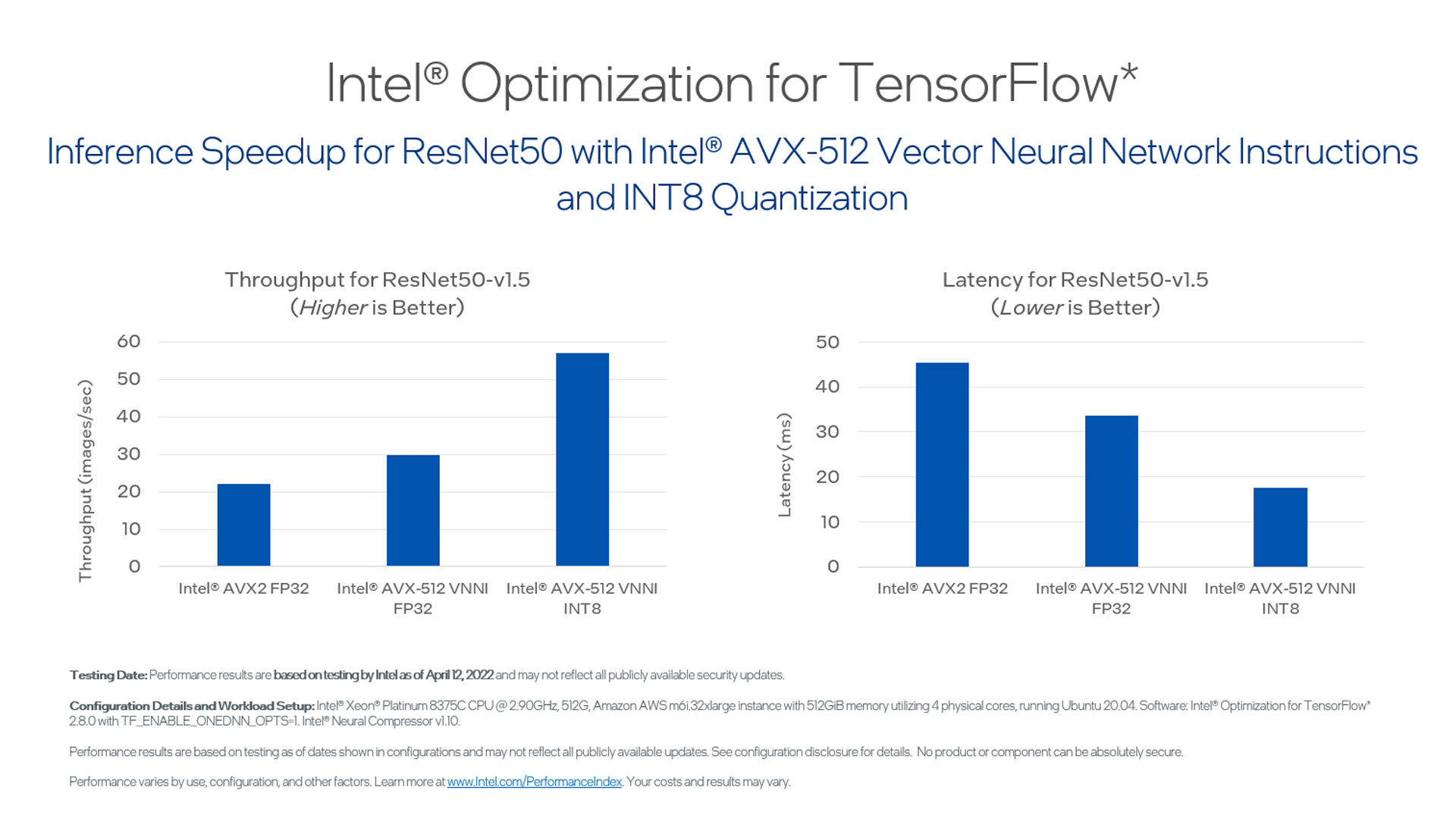
For optimizing latency, you typically use a batch size of 1 image per instance of the model and parallelize the model running across physical cores. For optimizing throughput, you would use much higher batch sizes so you need only load the weights once and can use all the available physical cores to parallelize as much as possible. Both use cases benefit from the oneDNN optimizations. The demo runs the model using the latency settings—batch size of 1 and 1 instance across 4 physical cores, both with and without the AVX-512 VNNI instructions. For this configuration, the AVX512-VNNI instructions sped up the demo throughput and latency by about 35%.
To further improve performance, you can quantize the model from 32-bit single-precision floating-point (FP32) to 8-bit integer (INT8). This not only reduces the size of the model and weights, but it also allows oneDNN to further parallelize computations using AVX-512 VNNI instructions. Since the AVX512 instruction set is single-instruction multiple-data (SIMD) with 512-bit registers, quantization can increase throughput of these registers from 16 FP32 values at-a-time to 64 INT8 values. Intel® AVX-512 VNNI further accelerates inference by taking advantage of INT8 quantization to combine three instructions into one.
The demo uses a script and a configuration file to perform quantization with Intel® Neural Compressor, but this step is not shown due to time constraints. You can try this step yourself along with other model compression techniques via the Intel Neural Compressor GitHub repository.
Quantizing to INT8 delivers an additional 2x speedup, resulting in an overall speedup of 2.6x versus the baseline of not using the AVX-512 VNNI instructions, as shown below:
While this demo focuses specifically on speeding up TensorFlow-based deep learning inference by taking advantage of the Intel AVX-512 VNNI instruction set, you can speed up your entire end-to-end AI workflow running on Intel hardware with Intel AI and machine learning development tools.
Get the Software
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.
Get It Now
See All Tools