Speed Up AI Inference without Sacrificing Accuracy
Intel® Neural Compressor is an open source Python* library for model compression that reduces model size and accelerates deep learning inference on CPUs or GPUs.
The library also:
- Provides unified interfaces across deep learning frameworks for quantization, pruning, and knowledge distillation
- Supports automatic accuracy-driven tuning strategies to help you quickly find the best quantized model
- Uses weight pruning algorithms to generate pruned models using a predefined sparsity goal
- Supports knowledge distillation from the teacher model to the student model
Intel Neural Compressor provides APIs for frameworks including TensorFlow*, PyTorch*, MXNet*, and Open Neural Network Exchange (ONNX*) Runtime for greater interoperability across frameworks. This article focuses on the benefits of using the tool with a PyTorch model (see figure 1).
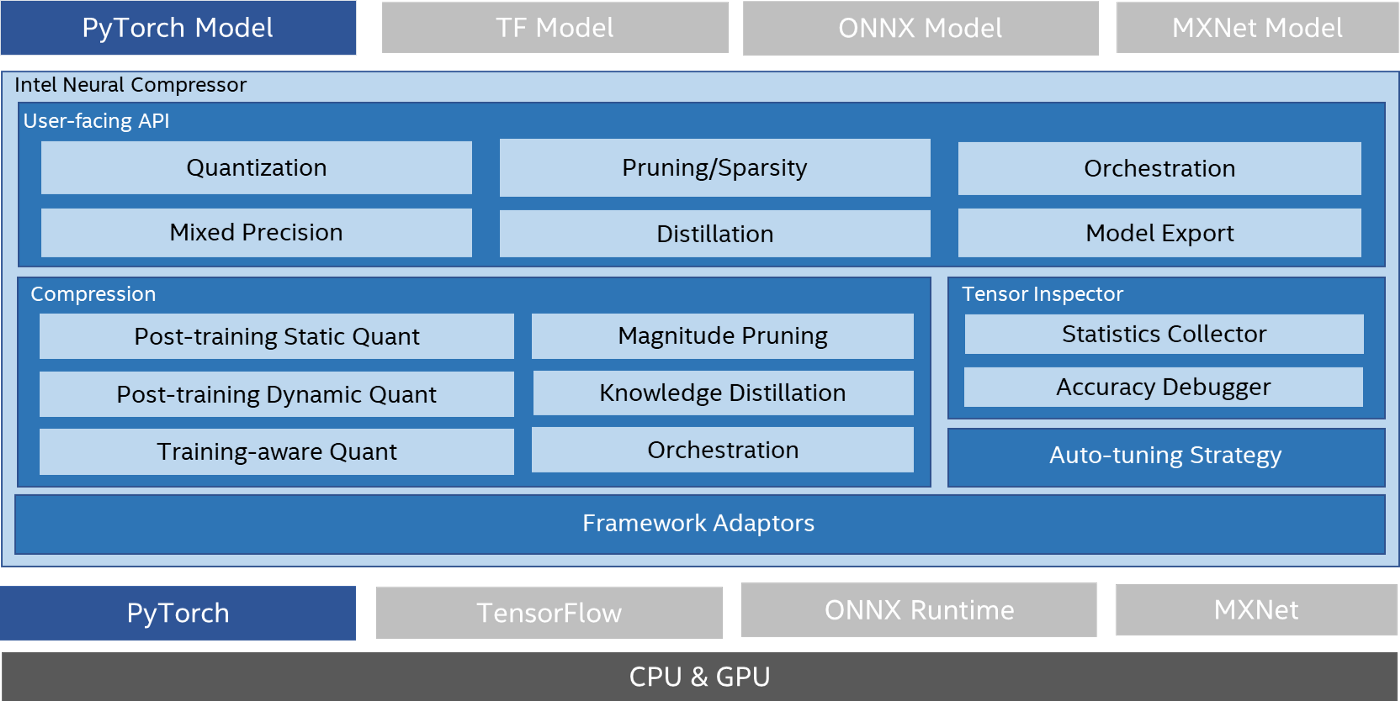
Figure 1. Intel Neural Compressor
How It Works
Intel Neural Compressor extends PyTorch quantization by providing advanced recipes for quantization, automatic mixed precision, and accuracy-aware tuning.
The tool takes a PyTorch model as input and yields an optimal model. Its quantization capability is built on the standard PyTorch quantization API and makes its own modifications to support fine-grained quantization granularity from the model level to the operator level. This approach gives better accuracy without the need for additional hand-tuning.
Automatic Mixed Precision
Intel Neural Compressor further extends the PyTorch automatic mixed-precision feature on 3rd generation Intel® Xeon® Scalable processors with support for int8 in addition to bfloat16 and FP32.
It first converts all quantizable operators from FP32 to int8. Then, it converts the remaining FP32 operators to bfloat16, if bfloat16 kernels are supported on PyTorch and accelerated by the underlying hardware (see figure 2).
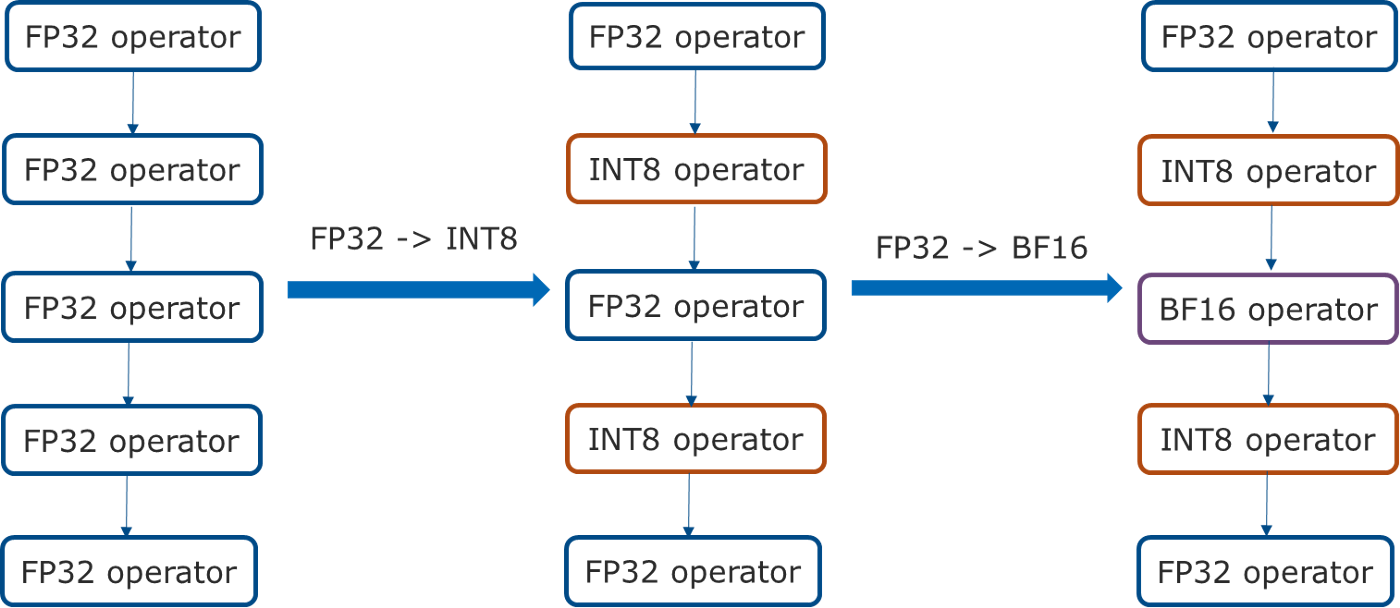
Figure 2. Automatic mixed precision
Automatic Accuracy-Aware Tuning
Intel Neural Compressor supports an automatic accuracy-aware tuning mechanism for better quantization productivity. It first queries the framework for quantization capabilities, including:
- Granularity (per_tensor or per_channel)
- Scheme (symmetric or asymmetric)
- Data type (u8 or s8)
- Calibration approach (min-max or KL divergence)
Then, it queries the supported data types for each operator. With these queried capabilities, the tool generates a tuning space of quantization configurations and starts tuning iterations.
For each set of quantization configurations, it performs calibration, quantization, and evaluation. Once the evaluation meets the accuracy goal, the tool stops the tuning process and produces a quantized model (see figure 3).
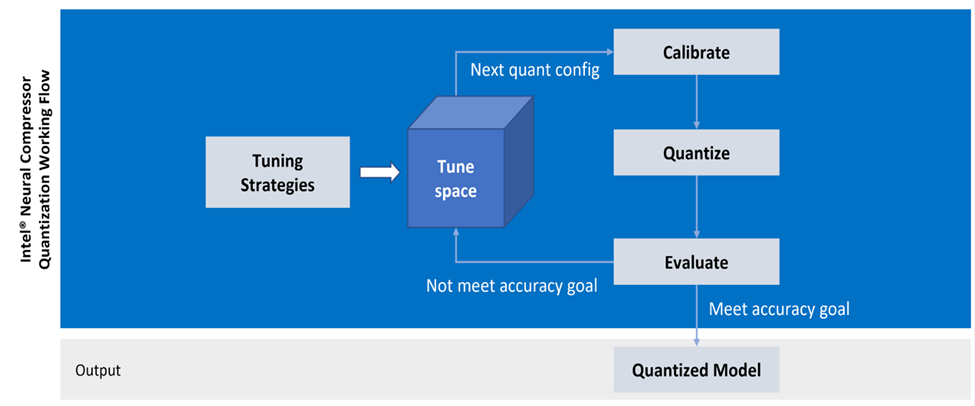
Figure 3. Example of automatic accuracy-aware tuning
Pruning
Pruning is mainly focused on unstructured and structured weight pruning and filter pruning:
- Unstructured pruning uses a magnitude algorithm to prune weights during training when their magnitude is below a predefined threshold.
- Structured pruning implements experimental tile-wise sparsity kernels to boost the performance of the sparsity model.
- Filter pruning implements a gradient-sensitivity algorithm that prunes the head, intermediate layers, and hidden states in the model according to the importance score calculated by the gradient.
Knowledge Transfer
Intel Neural Compressor implements a knowledge distillation algorithm to transfer knowledge from a large teacher model to a smaller student model without validity loss (see figure 4). The same input is fed to both models; the student model learns by comparing its results to both the teacher and the ground-truth label.
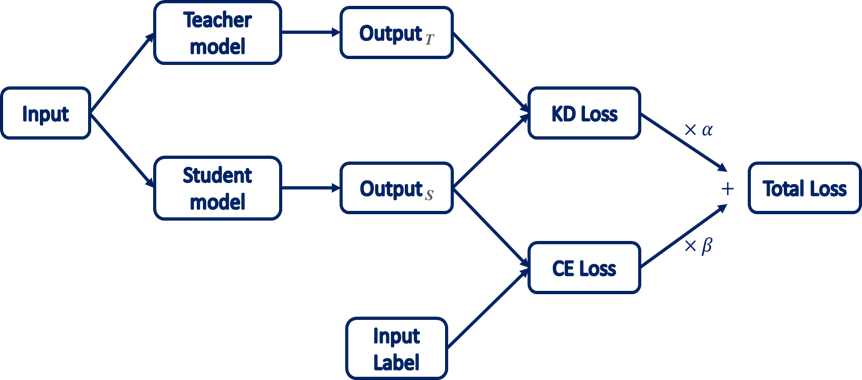
Figure 4. Knowledge distillation algorithm
How to Quantize: Code Example
The following example shows how to quantize a natural language processing (NLP) model using Intel Neural Compressor.
# config.yaml
model:
name: distilbert
framework: pytorch_fx
tuning:
accuracy_criterion:
relative: 0.01
# main.py
import torch
import numpy as np
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer
)
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
)
# Calibration dataloader
class CalibDataLoader(object):
def __init__(self):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.sequence = "Shanghai is a beautiful city!"
self.encoded_input = self.tokenizer(
self.sequence,
return_tensors='pt'
)
self.label = 1 # negative sentence: 0; positive sentence: 1
self.batch_size = 1
def __iter__(self):
yield self.encoded_input, self.label
# Evaluation function
def eval_func(model):
output = model(**calib_dataloader.encoded_input)
print("Output: ", output.logits.detach().numpy())
emotion_type = np.argmax(output.logits.detach().numpy())
return 1 if emotion_type == calib_dataloader.label else 0
# Enable quantization
from neural_compressor.experimental import Quantization
quantizer = Quantization('./config.yaml')
quantizer.model = model
quantizer.calib_dataloader = CalibDataLoader()
quantizer.eval_func = eval_func
q_model = quantizer.fit()
Note The generated mixed-precision model may vary depending on the capabilities of the low-precision kernels and the underlying hardware (for example, int8, bfloat16, or FP32 mixed-precision model on 3rd generation Intel Xeon Scalable pro.
Performance Results
Intel Neural Compressor has validated more than 400 examples with a performance speedup geomean of 2.2x on an Intel® Xeon® Platinum 8380 processor with minimal accuracy loss (table 1).
- See validated samples.
- See validated models.
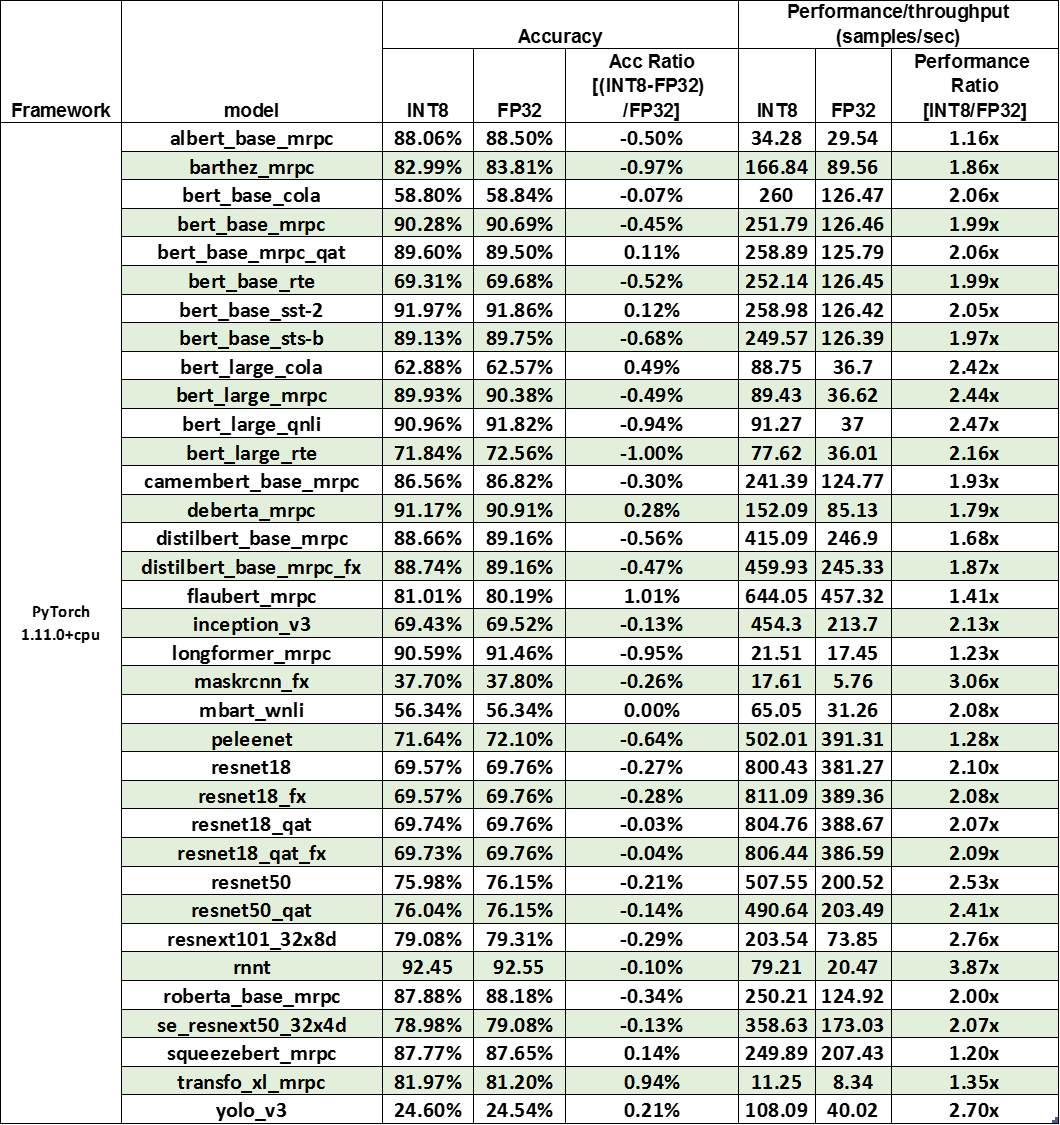
Table 1. Performance results for Intel Neural Compressor
Testing Date: Performance results are based on testing by Intel as of June 10, 2022, and may not reflect all publicly available security updates.
Configuration details and workload setup: 2S Intel Xeon Platinum 8380 CPU at 2.30 GHz, 40 core/80 thread, turbo boost on, hyperthreading on; memory: 256 GB (16x16 GB DDR4 3200 MT/s); storage: Intel® SSD *1; NIC: 2x Ethernet Controller 10 G X550T; BIOS: SE5C6200.86B.0022.D64.2105220049 (ucode:0xd0002b1); operating system: Ubuntu* 20.04.1 LTS; kernel: 5.4.0–42-generic; batch size: 1; core per instance: 4.
Try Intel® Neural Compressor
Intel Neural Compressor boosts productivity and minimizes accuracy loss with an autotuning mechanism and easy-to-use API for applying popular neural network compression techniques. The tool continues to evolve as we add compression recipes and combine techniques to produce optimal models.
- Download Intel Neural Compressor as part of AI Tools.
- Download the Intel Neural Compressor stand-alone version.
- Provide feedback and contributions in the GitHub* repository.
Acknowledgments
We would like to thank Xin He, Chang Wang, Wenxin Zhang, Penghui Cheng, and Suyue Chen for their contributions to Intel Neural Compressor. We also offer a special thanks to Eric Lin, Jianhui Li, and Jiong Gong for their technical discussions and insights, as well as collaborators from Meta* for their professional support and guidance. Finally, we would like to thank Wei Li, Andres Rodriguez, and Honesty Young for their great support.