Tricks to Improve Machine Learning Training Performance
Kirill Shvets, machine learning engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Gradient Boosting for Data Science
There are plenty of well-known gradient boosting frameworks that deliver accuracy and efficiency in real-world applications. They are regarded as a multipurpose tool to deal with many types of machine learning problems.
According to the Kaggle 2020 survey,1 61.4% of data scientists use gradient boosting (XGBoost, CatBoost, LightGBM) on a regular basis, and these frameworks are more commonly used than the various types of neural networks. Therefore, reducing the computational cost of gradient boosting is critical. Previous articles have already covered Intel optimizations to XGBoost training and model converters that speed up LightGBM and XGBoost inference with no loss in accuracy.
This article covers the CatBoost gradient boosting library. Compared to other libraries, CatBoost effectively handles categorical features and provides a larger variety of growing policies. For example, the Symmetric Tree policy reduces the variance of a trained model and significantly improves training time. CatBoost v0.25 introduces optimizations that accelerate training up to 4x compared to the previous release (Figure 1).
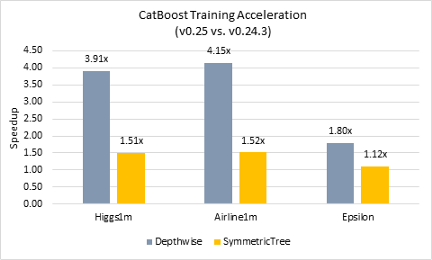
Figure 1. Relative speed up of CatBoost v0.25 over v0.24.3 for the Higgs1m and Airline1m datasets and the Epsilon dataset
Optimization Details
The training stage of gradient boosting is quite complex. There are many computational kernels that require specific optimizations to mitigate irregular memory access patterns, parallelize loops with dependencies, and eliminate branch misprediction. Some optimizations for memory-bound workloads (for example, using the smallest integer type, int8) were already implemented in earlier versions of CatBoost. However, there were still opportunities for enhancement, that is, using subtraction for histogram calculation, reducing threading overheads, and introducing a more effective default threading layer backend.
The Subtraction Trick
With the Depthwise growing policy, a tree is built level by level in each training iteration. This common approach can be parallelized efficiently over the feature columns and over node construction for nodes on the same tree level. Before training, CatBoost performs a quantization of feature columns to bins. The number of bins is controlled by the max_bin parameter. During training, CatBoost computes a histogram for each decision tree node. Histogram calculations consist of finding the sum of gradients and Hessians for each bin.
Histogram calculations are the most compute-intensive part of the training stage. However, a histogram’s additivity offers a solution to optimize the histogram calculation process. Because the histogram of a parent node is equal to the sum of the histograms of its child nodes, there is no need to compute the exact histogram for each node on the same level. Instead, it is possible to calculate the histogram for the smallest child of the parent node, and then compute the largest child’s histogram by subtracting the smallest child’s histogram from the previously saved parent’s histogram.
This algorithmic optimization was added to the main branch of the CatBoost GitHub repository. It significantly reduces the training time when the Depthwise growing policy is used (Table 1).
Table 1. The speedup in CatBoost training with the Depthwise policy going from v0.24.3 to v0.25
| CatBoost Performance (Depthwise Speedup |
Higgs1m | Airline1m | Epsilon |
| 2.37 | 3.14 | 1.53 |
Threading Layer Improvements
The performance improvements described in the previous section would not have been possible without threading fixes made by the CatBoost maintainers. Significant threading overhead was observed with Intel® VTune™ Profiler. Much of this overhead was eliminated by increasing the size of each task, but it did not solve the root cause of the issue.
We improved the threading layer by providing an alternative to the custom CatBoost threading layer back end: the Intel® oneAPI Threading Building Blocks (oneTBB) library. Integrating the mature, well-supported, and highly optimized oneTBB library into CatBoost resolved the threading overhead problem by providing more effective task scheduling and better nested threading (Table 2).
Table 2. The performance improvements in CatBoost training with the Symmetric Tree policy going from v0.24.3 to v0.25. Times are in seconds.
| CatBoost Performance (SymmetricTree) |
Higgs1m, s | Airline1m, s | Epsilon, s |
|---|---|---|---|
| Before oneTBB integration | 76.8 | 64.8 | 27.7 |
| After oneTBB integration | 50.9 | 42.8 | 24.8 |
| Speedup | 1.51 | 1.51 | 1.12 |
When using the Symmetric Tree policy, oneTBB integration improved performance up to 1.5x over the previous threading layer. The CatBoost maintainers report up to 2x speedups.2 When combined with the subtraction trick, the oneTBB threading layer improved the training performance for the Depthwise policy (1.65x speedup for Higgs1m, 1.32x speedup for Airline1m, and 1.17x speedup for Epsilon) and yielded total improvements of 3.9x for Higgs1m, 4.1x for Airline1m, and 1.8x for Epsilon.
As of CatBoost v0.25, oneTBB is the default threading layer.
Conclusions
If you’re using CatBoost to train machine learning models, be sure to use the latest version. Up to 4x speedup can be obtained from the optimizations in v0.25, and there’s still more that can be done to improve CatBoost performance. Further core scalability improvements, better memory bandwidth utilization, and vector instructions usage are just a few examples that we expect to be added in future releases.
Hardware and Software Configurations
Intel® Xeon® Platinum 8280L processor (2nd generation Intel® Xeon® processors): 2 sockets; 28 cores per socket; Hyper-threading (HT): on; Turbo: on; total memory of 384 GB (12 slots, 16 GB, 2933 MHz). CatBoost 0.24.3 (before optimizations), 0.25 (after optimizations); NumPy 1.15.1; scikit-learn* 0.24.1, oneTBB 2021.2.
Training Parameters
Higgs1m [1] and Airline1m [1]:
{iterations=1000, learning_rate=0.1, grow_policy=’Depthwise/SymmetricTree’, score_function=’L2′, border_count=256, scale_pos_weight=2, l2_leaf_reg=1,logging_level=’Silent’, depth=8}
Epsilon [2]:
{max_depth: 8, learning_rate: 0.1, reg_lambda: 0, iterations=500, grow_policy=’Depthwise/SymmetricTree’, logging_level=’Silent’}
References
The Airline1m and Higgs1m datasets are available in the Dmlc XGBoost Benchmark Repository.
The Epsilon dataset is available in the NVIDIA* Benchmark Repository.
______
You May Also Like
Intel® oneAPI Threading Building Blocks (oneTBB)
Simplify the task of adding parallelism to complex applications across diverse architectures. oneTBB is included as part of the Intel® oneAPI Base Toolkit.