Get Up to 36x Faster Inference Using Intel® oneAPI Data Analytics Library
Igor Rukhovich, machine learning intern, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Gradient boosting on decision trees is one of the most accurate and efficient machine learning algorithms for classification and regression. There are many implementations of gradient boosting, but the most popular are the XGBoost and LightGBM frameworks. This article shows how to improve the prediction speed of XGBoost or LightGBM models up to 36x with Intel® oneAPI Data Analytics Library (oneDAL).
Gradient Boosting
Many people use XGBoost and LightGBM gradient boosting to solve various real-world problems, conduct research, and compete in Kaggle* competitions. Although these frameworks give good performance out of the box, their prediction speed can still be improved. Considering that prediction is the most important stage of the machine learning workflow, performance improvements can be beneficial.
A previous article showed that oneDAL performs gradient boosting inference several times faster than its competitors: Fast Gradient Boosting Tree Inference. This performance benefit is now available in XGBoost and LightGBM.
Model Converters
All gradient boosting implementations perform similar operations, and therefore have similar data storage. In theory, this facilitates the conversion of trained models from one machine learning framework to another. Model converters in oneDAL are designed to help you transfer a trained model from XGBoost or LightGBM to oneDAL with just a single line of code. Model converters from other frameworks will soon be available.
These examples show how to convert XGBoost and LightGBM models to oneDAL. First, get the latest version of daal4py for Python* 3.6 and higher:

Convert an XGBoost model to oneDAL:

Convert a LightGBM model to oneDAL:

Note that there is temporary limitation on the use of missing values (NaN) during training and prediction. Inference quality might be lower if the data has missing values.
This example shows how to save and load a model from oneDAL:

By default, oneDAL only returns labels for predicted elements. If you need the probabilities as well, you must explicitly ask for them:

Performance Comparison
The performance advantage of oneDAL over XGBoost and LightGBM is demonstrated using the following off-the-shelf datasets:
- Mortgage (45 features, nine million observations)
- Airline (691 features, one-hot encoding, one million observations)
- Higgs (28 features, one million observations)
- MSRank (136 features, three million observations)
The models were trained in XGBoost and LightGBM, then converted to daal4py. To compare performance of stock XGBoost and LightGBM with daal4py acceleration, the prediction times for both original and converted models were measured. Figure 1 shows that daal4py is up to 36x faster than XGBoost (24x faster on average) and up to 15.5x faster than LightGBM (14.5x faster on average). Prediction quality remains the same (as measured by mean squared error for regression and accuracy and logistic loss for classification).
oneDAL uses the Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instruction set to maximize gradient boosting performance on Intel® Xeon® processors. The most commonly used inference operations, such as comparison and random memory access, can be effectively implemented using the vpgatherd{d,q} and vcmpp{s,d} instructions in Intel AVX-512. Performance also depends on the storage efficiency and memory bandwidth. For tree structures, oneDAL uses smart locking of data in memory to achieve temporary cache localization (that is, the state when a subset of trees and a block of observations are stored in L1 data cache). This action satisfies most of the memory accesses immediately at the L1 level with the highest memory bandwidth.
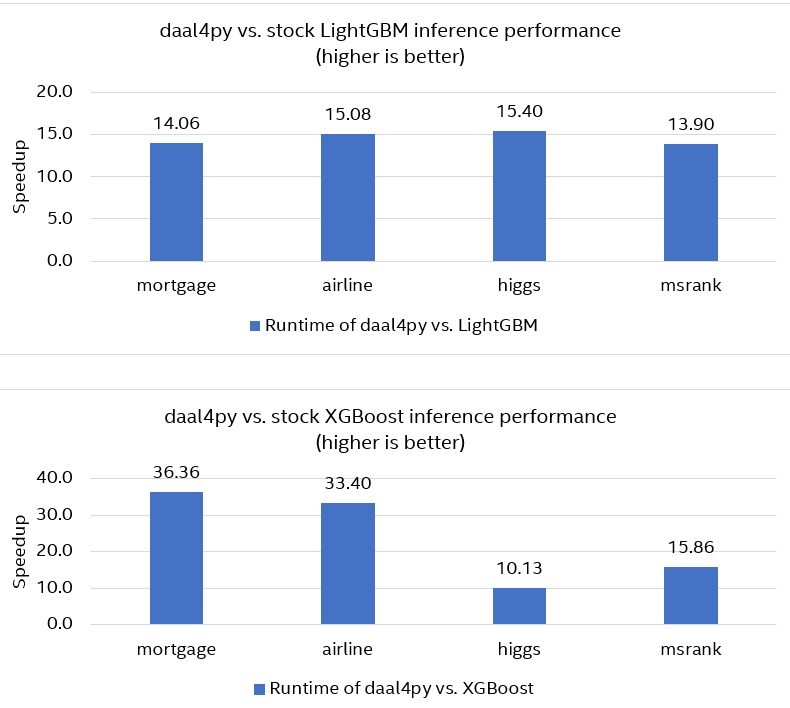
Figure 1. Performance of stock XGBoost and LightGBM with daal4py acceleration
Conclusion
Many applications use XGBoost and LightGBM for gradient boosting and the model converters provide an easy way to accelerate inference using oneDAL. The model converters allow XGBoost and LightGBM users to:
- Use their existing model training code without changes
- Perform inference up to 36x faster with minimal code changes and no loss of quality
Hardware and Software Configuration
Intel® Xeon® Platinum 8275CL processor (2nd generation Intel® Xeon® Scalable processors): 2 sockets, 24 cores per socket
Hyperthreading: On
Turbo: On
Operating System: Ubuntu* 18.04.4 LTS (Bionic Beaver), total memory of 192 GB (12 slots, 16 GB, 2933 MHz)
Software: XGBoost 1.2.1, LightGBM 3.0.0, daal4py version 2020 update 3, Python 3.7.9, NumPy 1.19.2, pandas 1.1.3, and scikit-learn* 0.23.2
Training Parameters: XGBoost and LightGBM
______
You May Also Like
Accelerate Linear Models for Machine Learning
Intel® oneAPI Data Analytics Library (oneDAL)
Deploy high-performing data science on CPUs and GPUs using high-speed algorithms. oneDAL is included as part of the Intel® oneAPI Base Toolkit