Tune MPI-Bound Code
To improve performance of the heart_demo application, it is necessary to change the communication pattern.
- Update the sample code.
- Review the changes in Intel® Trace Analyzer and Collector.
- Review the changes in Application Performance Snapshot.
- Check process and thread configuration performance.
Update the Sample Application
In the case of heart_demo, performance improvement can be achieved by applying the Cuthill-McKee algorithm for reordering a mesh before performing calculations. The corresponding code is already in the application source and the algorithm can be enabled by the -i option. To see the effect of this reordering, re-trace the application:
$ mpirun -genv VT_LOGFILE_FORMAT=SINGLESTF -genv VT_LOGFILE_NAME=heart_demo_improved.single.stf -trace -n 16 -ppn 2 -f hosts.txt ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 50 -i
$ traceanalyzer ./heart_demo_improved.single.stf &
Use the setting -genv VT_LOGFILE_NAME=heart_demo_improved.single.stf in the launch command to specify the name of the resulting trace file to distinguish it from the original one.
Review Changes in Intel® Trace Analyzer and Collector
The optimized communication patterns should appear similar to this in the Message Profile:

The communication matrix changed, becoming diagonal, and communication time between processes drastically improved.
Review Changes in Application Performance Snapshot
To see the impact on the overall application performance, analyze it with Application Performance Snapshot once again:
$ export MPS_STAT_DIR_POSTFIX=_second
$ mpirun -aps -n 16 -ppn 2 -f hosts.txt ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 50 -i
$ aps-report stat_second -O report_second.html
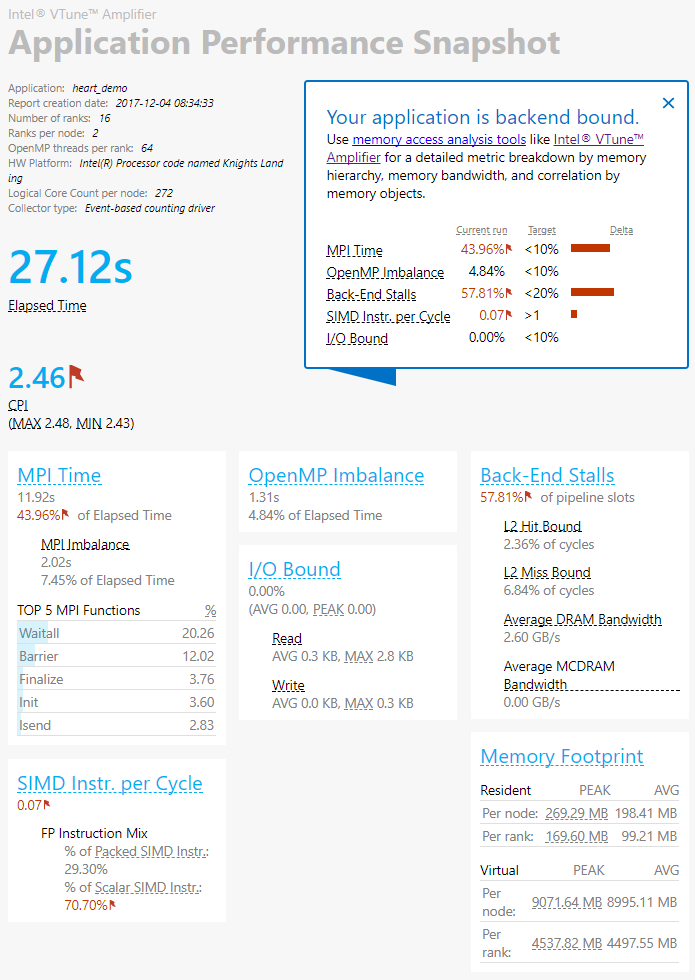
Application Performance Snapshot also indicates significant improvement in the application wallclock time (27.12 seconds vs 67.05 seconds) and MPI time (11.92 seconds vs 26.89 seconds). The results show that there is still significant MPI time, so it makes sense to examine the threading and vectorization aspects of the application.
Review Application Configuration Performance Changes
After optimizing the communication pattern it is worth checking the performance of the two best MPI/OpenMP* combinations once again:
# 2/64 $ cat > run_ppn2_omp64.sh export OMP_NUM_THREADS=64 mpirun -n 16 -ppn 2 -f hosts.txt ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 50 -i $ time ./run_ppn2_omp64.sh
# 32/4 $ cat > run_ppn32_omp4.sh export OMP_NUM_THREADS=4 mpirun -n 256 -ppn 32 -f hosts.txt ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 50 -i $ time ./run_ppn32_omp4.sh
After running the above steps, the following results were found:
Combination (MPI/OpenMP) |
Computation Time |
Elapsed Time |
|---|---|---|
2/64 |
19.43 |
35.66 |
32/4 |
15.92 |
45.65 |
After the communication improvements, the second combination performs calculations even faster than the first one, although the elapsed time is significantly higher. This is connected with the time costs for MPI environment deployment for a larger number of processes.
Better computation time of the second combination indicates that there is an improvement potential for the first combination as well. As the next step, use the Intel VTune Profiler to understand the nature of this behavior.
Key Take-Away
After completing an optimization, it is beneficial to check the performance of the best MPI process and OpenMP thread combinations again to see if there has been any change. Run the application without any analysis software to get an accurate elapsed time.