Tutorial: Analyze Common Performance Bottlenecks using Intel VTune Profiler in a C++ Sample Application - Windows* OS
Analyze Vectorization Efficiency
In this part, you analyze how well the application was vectorized after the compiler options were changed.
Once you recompile the application with the /O2 level enabled, run the Performance Snapshot analysis again to analyze vectorization efficiency.
Once the analysis is complete, see the Vectorization pane of the Summary window.
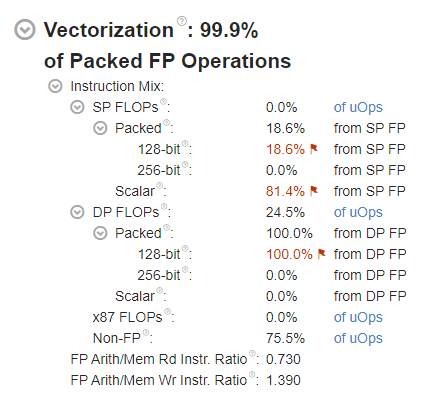
Observe these main indicators:
The overall Vectorization metric is equal to 99.9%, which indicates that the code was vectorized.
However, there are red flags next to the 128-bit Packed FLOPs metrics. Hover over the red flag icon or the metric value to get a description of the issue.

In this case, Intel® VTune™ Profiler indicates that a significant portion of floating-point instructions is executed with partial vector load.
Since the analysis was performed on a machine based on an Intel processor capable of using the AVX2 instruction set, the fact that all instructions were executed using only the 128-bit registers means that the 256-bit wide AVX2 registers were not utilized at all. Therefore, VTune Profiler flags the 100.0% utilization of 128-bit vector registers as an issue.
To understand what vector instruction set is actually used, run the HPC Performance Characterization analysis.
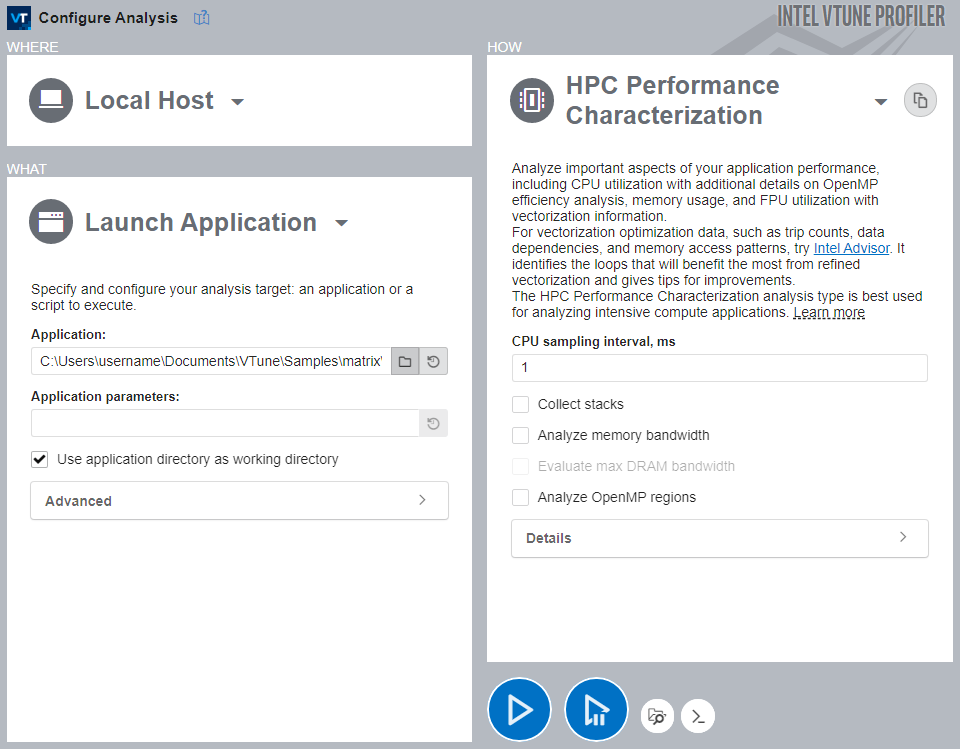
To run the analysis:
Click the HPC Performance Characterization analysis icon from the analysis tree.
Disable the Collect stacks, Analyze Memory bandwidth and Analyze OpenMP regions options as they are not required for vectorization analysis.
Click the Start button to run the analysis.
Once the data collection is complete, VTune Profiler opens the default Summary window of the HPC Performance Characterization Analysis.
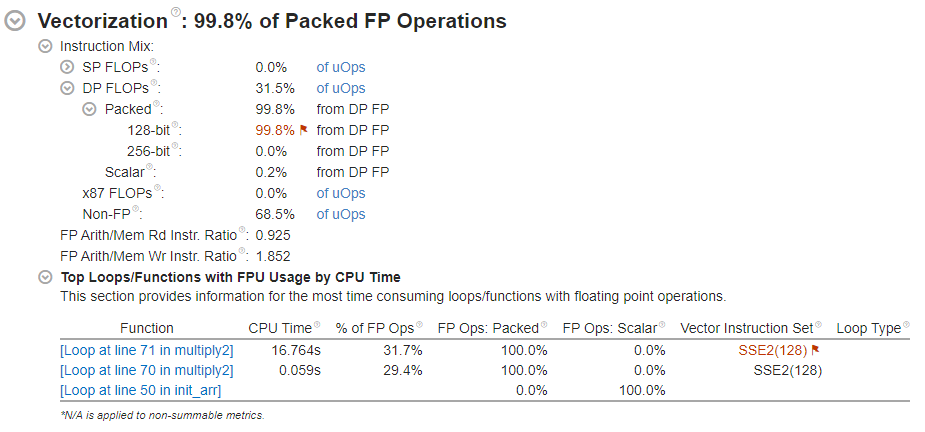
Focus on the Vectorization section of the Summary window.
Note that the main loop of the multiply2 function was vectorized using the older SSE2 instruction set, while compilation and analysis were performed on an AVX2-capable processor. Therefore, a portion of hardware resources remains underutilized.
Next step: Enable Platform-Appropriate Vectorization.