Inefficient Synchronization
This recipe shows how to locate inefficient synchronization in your code by running the Advanced Hotspots analysis of the Intel® VTune™ Amplifier with the stack collection enabled.
DIRECTIONS:
Advanced Hotspots analysis was integrated into the generic Hotspots analysis starting with Intel VTune Amplifier 2019, and is available via the Hardware Event-Based Sampling collection mode.
Ingredients
This section lists the hardware and software tools used for the performance analysis scenario.
Application: sample.exe using OpenMP* runtime. The application is used as a demo and not available for download.
Performance analysis tools: Intel VTune Amplifier 2017: Advanced Hotspots analysis
NOTE:Starting with the 2020 release, Intel® VTune™ Amplifier has been renamed to Intel® VTune™ Profiler.
Most recipes in the Intel® VTune™ Profiler Performance Analysis Cookbook are flexible. You can apply them to different versions of Intel® VTune™ Profiler. In some cases, minor adjustments may be required.
Get the latest version of Intel® VTune™ Profiler:
From the Intel® VTune™ Profiler product page.
Download the latest standalone package from the Intel® oneAPI standalone components page.
Operating system: Microsoft* Windows* 8
CPU: Intel® microarchitecture code named Skylake
Run the Advanced Hotspots Analysis with Stacks
Launch the VTune Amplifier and configure your project for analysis:
Click the
 New Project button on the toolbar and specify a name for the new project, for example: sqlite.
New Project button on the toolbar and specify a name for the new project, for example: sqlite. In the Analysis Target window, select the local host target system type for the host-based analysis.
Select the Launch Application target type and specify an application for analysis on the right.
Click the Choose Analysis button on the right, select Algorithm Analysis > Advanced Hotspots and select the Hotspots and stacks option.
Click Start.
VTune Amplifier launches the application, collects data, finalizes the data collection result resolving symbol information, which is required for successful source analysis.
Locate Synchronization on the Timeline
Open the data collected during the analysis in the Hardware Events viewpoint:
|
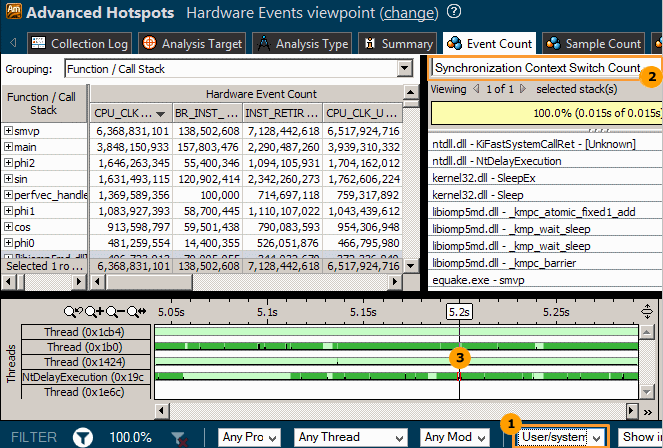
Select the User/system functions call stack mode to display both user and system functions in the Call Stack pane. |
|
In the Call Stack pane, select the Synchronization Context Switch Count type from the drop-down menu to see a call stack for the synchronization context switch selected in the Timeline pane. |
|
Locate a frequent synchronization on the timeline and hover over a context switch to view details in the tooltip. For example, in the Advanced Hotspots result above, the NtDelayExecution thread has the largest number of context switches caused by synchronization. When you select a context switch on the timeline, the Call Stack pane is updated to show a call sequence at which a preceding thread execution quantum was interrupted. |



Analyze an Average Wait Metric
Click the (change) link to open the Hotspots viewpoint:
|
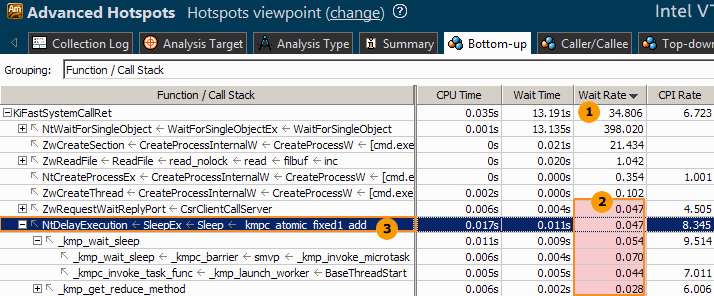
Analyze the Wait Rate metric data, that is average wait time (in milliseconds) per synchronization context switch. This metric helps you identify ineffective frequent synchronizations as well as power consumption issues. |
|
VTune Profiler interprets low Wait Rate metric values (under 1ms) as performance issues and highlights them in pink. These values may signal an increased contention between threads and inefficient use of system API. |
|
Identify a synchronization stack with short Wait time and high CPU time (half the time of all system calls) and double-click it to explore the source code of the hotspot function. |
Analyze Synchronization Context Switches
Click the (change) link to open to the Hardware Events viewpoint. By default, the Event Count grid is sorted by the Clockticks event. Identify the hottest functions that took the most CPU time (in clockticks) to execute and had the most frequent synchronization.
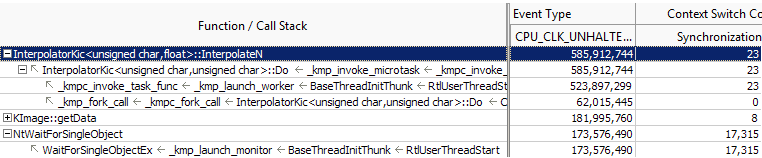
In this sample OpenMP* application, the VTune Amplifier identifies the InterpolateN function as a primary computation hotspot called from an OpenMP region. You can also see a major contention on the WaitForSingleObject inside the OpenMP runtime that results in ~ 30% of performance loss (Clockticks of the wait function / Clockticks of the hotspot function).
Double-click the InterpolateN function to view the source code and identify a cause of ineffective synchronization.
for(i = 0; i < block_no; i++)
{
#pragma omp parallel for
for(j = 0; j < lines_in_block; j++)
{
/// do processing
} /// implicit barrier causing contention and overhead
}Code analysis for the sample application discovers excessive OpenMP barriers added to process a picture by blocks of lines and parallelize each block separately. To resolve this issue, use the nowait clause or apply parallel_for to the entire picture and use dynamic work scheduling.
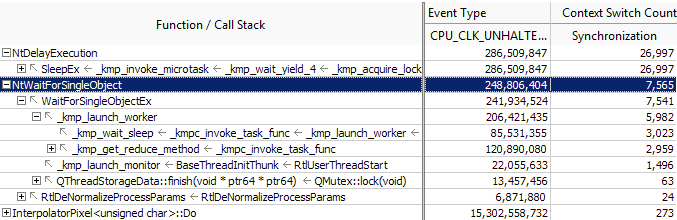
For the optimized result, the relative cost of contention on Sleep() is low (26,997).
Using a single parallel_for and dynamic work scheduling for the WaitForSingleObject function helped decrease the contention and negative performance impact down to ~1%.
The second optimized result also discovers another highly contended function Sleep() (Synchronization Context Switches metric equal to 26,997). But if you check its execution time, it is within 2% of the top hotspot (not shown), which makes it less important. But this function may become an issue when running the application on a greater number of processors.
The initial (pre-optimized) sample data collection session represented above was taken on a limited time interval. The optimized version represents a full application run.