AN 1020: Using the FPGA AI Suite IP with High Bandwidth Memory on Stratix® 10 MX and Agilex™ 7 M-Series Devices
2.2.2. Memory Data Width Considerations
The other consideration is the 256-bit wide data path that is provided as an AXI4 bus by the HBM memory controllers. Two pseudo channels are exposed for each layer of the HBM memory, which are ideally used simultaneously to achieve highest possible bandwidth per HBM channel.
This 256-bit wide data path is only half of the 512-bit wide data path that the current FPGA AI Suite IP implementation expects and therefore is a limiting factor in terms of bandwidth.
From an implementation perspective, you have the following options to connect the 512-bit data width FPGA AI Suite IP instance to the 256-bit data width HBM pseudo channel AXI4 interface:
- Configure the FPGA AI Suite IP .arch file to use only a 256-bit wide data bus to external memory.
This configuration does not require any additional adaptation logic and is the easiest to implement, but this configuration also decreases the bandwidth to external memory compared to the original 512-bit wide data bus.
To use this option, change the ddr_data_bytes value in the .arch files from 64 to 32.
- Use a width adapter and create two subsequent 256-bit accesses to the HBM memory controller for each 512-bit read/write by the FPGA AI Suite IP.
This configuration decreases the read/write performance of the original 512-bit data path system to roughly half of the original performance.
The following figure shows an example in Platform Designer of both channel stitching and width adaptation along with the automatically-generated arbitration and width-adapatation logic.Figure 6. Channel Stitching and Width Adaptation 512-to-256 Bit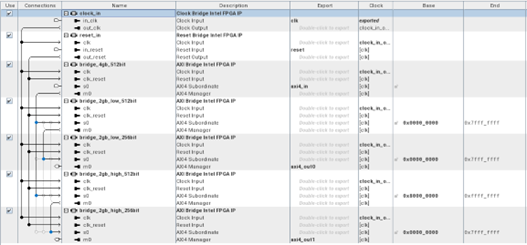
- Use a width adaptation and reordering buffer to divide the 512-bit read/write accesses of the FPGA AI Suite IP into 256-bit read/write accesses to both pseudo channels of the HBM memory controller channel.
This configuration ensures that one single HBM layer is fully utilized but requires you to create extra logic to not only do the width stitching but also to reorder the read data coming back from both HBM pseudo channels.
This configuration avoids the memory bandwidth loss of the other configurations.