1.4. Performance
The read latency shown in the following table is estimated based on 10M08, 10M16 and 10M25 User Flash Memory devices that have five cycles random read and is compared between a normal Nios II instruction master and flash accelerator interface.
| Nios II Instruction Interface | Random Access | Sequential Access |
|---|---|---|
| Normal | 5 | 5 |
| Flash Accelerator | 5 | 1 |
For a normal instruction master, fetching sequential addresses from the Max 10 On-Chip Flash IP is considered a random access because it does not take advantage of the burst read feature of the Flash IP by default. Enabling the optional burstcount signal at the Instruction Master does not improve the sequential access because the wrap burst of 8 from the instruction Master will be translated to equivalent incremental burst of 2 or 4 at the Flash IP. The most optimum setup is to ensure that both the master and slave have the same burst count size.
The flash accelerator has a cache line size that can be configured to match the corresponding Max 10 on-chip flash burst size. It is recommended that the flash accelerator line size is configured according to the Max 10 device family line sizes listed below for better performance.
| Max 10 Device | Cache Line Size (bits) |
|---|---|
| 10M08 | 64 |
| 10M16 | 128 |
| 10M25 | 128 |
| 10M50 | 128 |
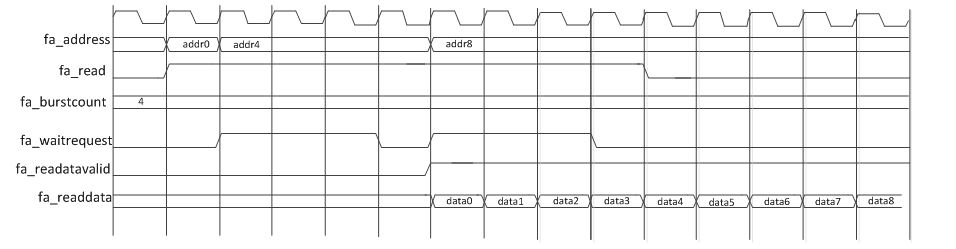
The flash accelerator also has pre-fetch feature that allows the sequential cache line to be filled to take advantage of the wait states. The timing diagrams for reads at flash accelerator is shown in the following figure:
Figure 2. Timing diagram for Flash Accelerator for 10M16/10M25