Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
struct dnnl::primitive_attr
Overview
Primitive attributes. More…
#include <dnnl.hpp>
struct primitive_attr: public dnnl::handle
{
// construction
primitive_attr();
primitive_attr(dnnl_primitive_attr_t attr);
// methods
fpmath_mode get_fpmath_mode() const;
void set_fpmath_mode(fpmath_mode mode);
scratchpad_mode get_scratchpad_mode() const;
void set_scratchpad_mode(scratchpad_mode mode);
void set_scales_mask(int arg, int mask);
void set_zero_points_mask(int arg, int mask);
const post_ops get_post_ops() const;
void set_post_ops(const post_ops ops);
void set_rnn_data_qparams(float scale, float shift);
void get_rnn_data_qparams(float& scale, float& shift);
void set_rnn_weights_qparams(int mask, const std::vector<float>& scales);
void get_rnn_weights_qparams(int& mask, std::vector<float>& scales);
void set_rnn_weights_projection_qparams(
int mask,
const std::vector<float>& scales
);
void get_rnn_weights_projection_qparams(int& mask, std::vector<float>& scales);
};Inherited Members
public:
// methods
handle<T, traits>& operator = (const handle<T, traits>&);
handle<T, traits>& operator = (handle<T, traits>&&);
void reset(T t, bool weak = false);
T get(bool allow_empty = false) const;
operator T () const;
operator bool () const;
bool operator == (const handle<T, traits>& other) const;
bool operator != (const handle& other) const;Detailed Documentation
Primitive attributes.
See also:
Construction
primitive_attr()Constructs default (empty) primitive attributes.
primitive_attr(dnnl_primitive_attr_t attr)Creates primitive attributes from a C API dnnl_primitive_attr_t handle.
The resulting handle is not weak and the C handle will be destroyed during the destruction of the C++ object.
Parameters:
attr |
The C API primitive attributes. |
Methods
fpmath_mode get_fpmath_mode() constReturns the fpmath mode.
void set_fpmath_mode(fpmath_mode mode)Sets fpmath mode.
Parameters:
mode |
Specified fpmath mode. |
scratchpad_mode get_scratchpad_mode() constReturns the scratchpad mode.
void set_scratchpad_mode(scratchpad_mode mode)Sets scratchpad mode.
Parameters:
mode |
Specified scratchpad mode. |
void set_scales_mask(int arg, int mask)Sets scaling factors for primitive operations for a given memory argument.
The scaling factors must be passed at execution time as an argument with index DNNL_ARG_ATTR_SCALES | arg.
Parameters:
arg |
Parameter argument index as passed to the primitive::execute() call. |
mask |
Scaling factors correspondence mask that defines the correspondence between the tensor dimensions and the scales vector. The set i-th bit indicates that a dedicated scaling factor is used for each index along that dimension. Set the mask to 0 to use a common scaling factor for the whole output tensor. |
See also:
dnnl_primitive_attr_set_scales_mask
void set_zero_points_mask(int arg, int mask)Sets zero points for primitive operations for a given memory argument.
The zero points must be passed at execution time as an argument with index DNNL_ARG_ATTR_ZERO_POINTS | arg.
Parameters:
arg |
Parameter argument index as passed to the primitive::execute() call. |
mask |
Zero point correspondence mask that defines the correspondence between the tensor dimensions and the zero_points vector. The set i-th bit indicates that a dedicated zero point is used for each index along that dimension. Set the mask to 0 to use a common zero point for the whole output tensor. |
See also:
dnnl_primitive_attr_set_zero_points_mask
const post_ops get_post_ops() constReturns post-ops previously set via set_post_ops().
Returns:
Post-ops.
void set_post_ops(const post_ops ops)Sets post-ops.
Parameters:
ops |
Post-ops object to copy post-ops from. |
void set_rnn_data_qparams(float scale, float shift)Sets quantization scale and shift parameters for RNN data tensors.
For performance reasons, the low-precision configuration of the RNN primitives expect input activations to have the unsigned 8-bit integer data type. The scale and shift parameters are used to quantize floating-point data to unsigned integer and must be passed to the RNN primitive using attributes.
The quantization formula is scale * data + shift.
Example usage:
// RNN parameters
int l = 2, t = 2, mb = 32, sic = 32, slc = 32, dic = 32, dlc = 32;
// Activations quantization parameters
float scale = 63.f, shift = 64.f;
primitive_attr attr;
// Set scale and shift for int8 quantization of activation
attr.set_rnn_data_qparams(scale, shift);
// Create an RNN primitive descriptor.
vanilla_rnn_forward::primitive_desc rnn_d(
engine, /* arguments */, attr);Parameters:
scale |
The value to scale the data by. |
shift |
The value to shift the data by. |
void get_rnn_data_qparams(float& scale, float& shift)Returns the quantization scale and shift parameters for RNN data tensors.
Parameters:
scale |
The value to scale the data by. |
shift |
The value to shift the data by. |
void set_rnn_weights_qparams(int mask, const std::vector<float>& scales)Sets quantization scaling factors for RNN weights tensors.
The low-precision configuration of the RNN primitives expect input weights to use the signed 8-bit integer data type. The scaling factors are used to quantize floating-point data to signed integer and must be passed to RNN primitives using attributes.
Parameters:
mask |
Scaling factors correspondence mask that defines the correspondence between the output tensor dimensions and the scales vector. The set i-th bit indicates that a dedicated scaling factor should be used each index along that dimension. Set the mask to 0 to use a common scaling factor for the whole output tensor. |
scales |
Constant vector of output scaling factors. The following equality must hold: |
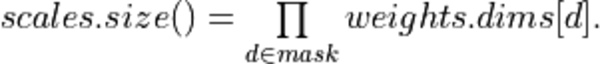 Violations can only be detected when the attributes are used to create a primitive descriptor.
Violations can only be detected when the attributes are used to create a primitive descriptor.void get_rnn_weights_qparams(int& mask, std::vector<float>& scales)Returns the quantization scaling factors for RNN projection weights tensors.
Parameters:
mask |
Scaling factors correspondence mask that defines the correspondence between the output tensor dimensions and the scales vector. The set i-th bit indicates that a dedicated scaling factor should be used each index along that dimension. Set the mask to 0 to use a common scaling factor for the whole output tensor. |
scales |
Constant vector of output scaling factors. The following equality must hold: |
void set_rnn_weights_projection_qparams(
int mask,
const std::vector<float>& scales
)Sets quantization scaling factors for RNN projection weights tensors.
passed to RNN primitives using attributes.
Parameters:
mask |
Scaling factors correspondence mask that defines the correspondence between the output tensor dimensions and the scales vector. The set i-th bit indicates that a dedicated scaling factor should be used each index along that dimension. Set the mask to 0 to use a common scaling factor for the whole output tensor. |
scales |
Constant vector of output scaling factors. The following equality must hold: |
void get_rnn_weights_projection_qparams(int& mask, std::vector<float>& scales)Returns the quantization scaling factors for RNN projection weights tensors.
Parameters:
mask |
Scaling factors correspondence mask that defines the correspondence between the output tensor dimensions and the scales vector. The set i-th bit indicates that a dedicated scaling factor should be used each index along that dimension. Set the mask to 0 to use a common scaling factor for the whole output tensor. |
scales |
Constant vector of output scaling factors. The following equality must hold: |