Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Dequantize
General
Dequantize operation converts a quantized (u8 or s8) tensor to a f32 tensor. It supports both per-tensor and per-channel asymmetric linear de-quantization. Rounding mode is library-implementation defined.
For per-tensor de-quantization:

For per-channel de-quantization, taking channel axis = 1 as an example:
where 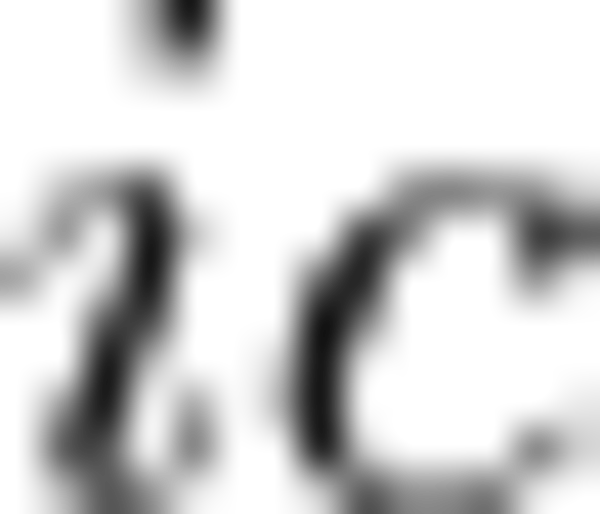 is the number of channels.
is the number of channels.
Operation attributes
Attribute Name |
Description |
Value Type |
Supported Values |
Required or Optional |
|---|---|---|---|---|
Specifies which de-quantization type is used. |
string |
per_tensor (default), per_channel |
Optional |
|
Specifies dimension on which per-channel de-quantization is applied. |
s64 |
A s64 value in the range of [-r, r-1] where r = rank(src), 1 by default |
Optional |
|
Scalings applied on the src data. |
f32 |
A f32 list (only contain one element if qtype is per_tensor ) |
Required |
|
Offset values that maps to float zero. |
s64 |
A s64 list (only contain one element if qtype is per_tensor ) |
Required |
Execution arguments
The inputs and outputs must be provided according to below index order when constructing an operation.
Inputs
Index |
Argument Name |
Required or Optional |
|---|---|---|
0 |
src |
Required |
Outputs
Index |
Argument Name |
Required or Optional |
|---|---|---|
0 |
dst |
Required |
Supported data types
Dequantize operation supports the following data type combinations.
Src |
Dst |
|---|---|
s8, u8 |
f32 |