Intel® C++ Compiler Classic Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Details of Intel® Advanced Vector Extensions Intrinsics
Intel® Advanced Vector Extensions (Intel® AVX) intrinsics map directly to Intel® AVX instructions and other enhanced 128-bit single-instruction multiple data processing (SIMD) instructions. Intel® AVX instructions are architecturally similar to extensions of the existing Intel® 64 architecture-based vector streaming SIMD portions of Intel® Streaming SIMD Extensions (Intel® SSE) instructions, and double-precision floating-point portions of Intel® Streaming SIMD Extensions 2 (Intel® SSE2) instructions. However, Intel® AVX introduces the following architectural enhancements:
- Support for 256-bit wide vectors and SIMD register set.
- Instruction syntax support three and four operand syntax, to improve instruction programming flexibility and efficiency for new instruction extensions.
- Enhancement of legacy 128-bit SIMD instruction extensions to support three-operand syntax and to simplify compiler vectorization of high-level language expressions.
- Instruction encoding format using a new prefix (referred to as VEX) to provide compact, efficient encoding for three-operand syntax, vector lengths, compaction of legacy SIMD prefixes and REX functionality.
- Intel® AVX data types allow packing of up to 32 elements in a register if bytes are used. The number of elements depends upon the element type: eight single-precision floating point types or four double-precision floating point types.
Intel® Advanced Vector Extensions Registers
Intel® AVX adds 16 registers (YMM0-YMM15), each 256 bits wide, aliased onto the 16 SIMD (XMM0-XMM15) registers. The Intel® AVX new instructions operate on the YMM registers. Intel® AVX extends certain existing instructions to operate on the YMM registers, defining a new way of encoding up to three sources and one destination in a single instruction.
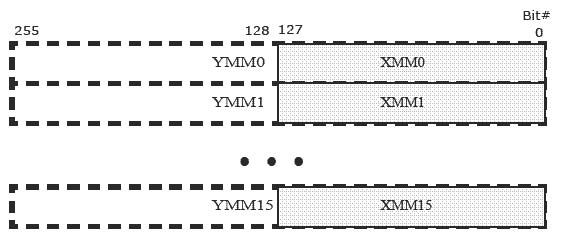
Because each of these registers can hold more than one data element, the processor can process more than one data element simultaneously. This processing capability is also known as single-instruction multiple data processing (SIMD).
For each computational and data manipulation instruction in the new extension sets, there is a corresponding C intrinsic that implements that instruction directly. This frees you from managing registers and assembly programming. Further, the compiler optimizes the instruction scheduling so that your executable runs faster.
Intel® Advanced Vector Extensions Types
The Intel® AVX intrinsic functions use three new C data types as operands, representing the new registers used as operands to the intrinsic functions. These are __m256, __m256d, and __m256i data types.
The __m256 data type is used to represent the contents of the extended SSE register, the YMM register, used by the Intel® AVX intrinsics. The __m256 data type can hold eight 32-bit floating-point values.
The __m256d data type can hold four 64-bit double precision floating-point values.
The __m256i data type can hold thirty-two 8-bit, sixteen 16-bit, eight 32-bit, or four 64-bit integer values.
The compiler aligns the __m256, __m256d, and __m256i local and global data to 32-byte boundaries on the stack. To align integer, float, or double arrays, use the __declspec(align) statement.
The Intel® AVX intrinsics also use Intel® SSE2 data types like __m128, __m128d, and __m128i for some operations. See Details of Intrinsics topic for more information.
VEX Prefix Instruction Encoding Support for Intel® AVX
Intel® AVX introduces a new prefix, referred to as VEX, in the Intel® 64 and IA-32 instruction encoding format. Instruction encoding using the VEX prefix provides several capabilities:
- direct encoding of a register operand within the VEX prefix.
- efficient encoding of instruction syntax operating on 128-bit and 256-bit register sets.
- compaction of REX prefix functionality.
- compaction of SIMD prefix functionality and escape byte encoding.
- providing relaxed memory alignment requirements for most VEX-encoded SIMD numeric and data processing instruction semantics with memory operand as compared to instructions encoded using SIMD prefixes.
The VEX prefix encoding applies to SIMD instructions operating on YMM registers, XMM registers, and in some cases with a general-purpose register as one of the operands. The VEX prefix is not supported for instructions operating on MMX™ or x87 registers.
It is recommended to use Intel® AVX intrinsics with option [Q]xAVX, because their corresponding instructions are encoded with the VEX-prefix. The [Q]xAVX option forces other packed instructions to be encoded with VEX too. As a result there are fewer performance stalls due to Intel® AVX to legacy Intel® SSE code transitions.
Naming and Usage Syntax
Most Intel® AVX intrinsic names use the following notational convention:
_mm256_<intrin_op>_<suffix>(<data type> <parameter1>, <data type> <parameter2>, <data type> <parameter3>)
The following table explains each item in the syntax.
| _mm256/_mm128 | Prefix representing the size of the result. Usually, this corresponds to the Intel® AVX vector register size of 256 bits, but certain comparison and conversion intrinsics yield a 128-bit result. |
| <intrin_op> | Indicates the basic operation of the intrinsic; for example, add for addition and sub for subtraction. |
| <suffix> | Denotes the type of data the instruction operates on. The first one or two letters of each suffix denote whether the data is packed (p), extended packed (ep), or scalar (s). The remaining letters and numbers denote the type, with notation as follows:
|
| <data type> | Parameter data types: __m256, __m256d, __m256i, __m128, __m128d, __m128i, const, int, etc. |
| <parameter1> | Represents a source vector register: m1/s1/a |
| <parameter2> | Represents another source vector register: m2/s2/b |
| <parameter3> | Represents an integer value: mask/select/offset The third parameter is an integer value whose bits represent a conditionality based on which the intrinsic performs an operation. |
Example Usage
extern __m256d _mm256_add_pd(__m256d m1, __m256d m2);where,
- add
- indicates that an addition operation must be performed
- pd
- indicates packed double-precision floating-point value
The packed values are represented in right-to-left order, with the lowest value used for scalar operations. Consider the following example operation:
double a[4] = {1.0, 2.0, 3.0, 4.0};
__m256d t = _mm256_load_pd(a);
The result is the following:
__m256d t = _mm256_set_pd(4.0, 3.0, 2.0, 1.0);
In other words, the YMM register that holds the value t appears as follows:

The " scalar " element is 1.0. Due to the nature of the instruction, some intrinsics require their arguments to be immediates (constant integer literals).