Executive Summary
Intel uses a tick-tock model associated with its generation of processors. The new generation, the Intel® Xeon® processor Scalable family (formerly code-named Skylake-SP), is a “tock” based on 14nm process technology. Major architecture changes take place on a “tock,” while minor architecture changes and a die shrink occur on a “tick.”
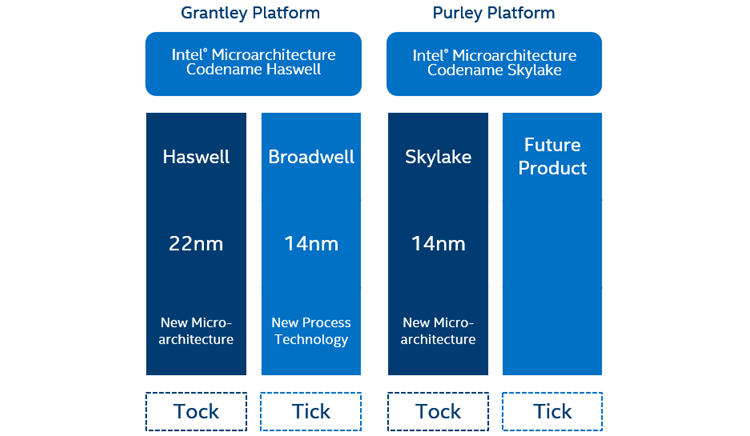
Figure 1. Tick-Tock model.
Intel Xeon processor Scalable family on the Purley platform is a new microarchitecture with many additional features compared to the previous-generation Intel® Xeon® processor E5-2600 v4 product family (formerly Broadwell microarchitecture). These features include increased processor cores, increased memory bandwidth, non-inclusive cache, Intel® Advanced Vector Extensions 512 (Intel® AVX-512), Intel® Memory Protection Extensions (Intel® MPX), Intel® Ultra Path Interconnect (Intel® UPI), and sub-NUMA clusters.
In previous generations two and four socket processor families were segregated into different product lines. One of the big changes with the Intel Xeon processor Scalable family is that it includes all the processor models associated with this new generation. The processors from Intel Xeon processor Scalable family are scalable from a two-socket configuration to an eight-socket configuration. They are Intel’s platform of choice for the most scalable and reliable performance with the greatest variety of features and integrations designed to meet the needs of the widest variety of workloads.
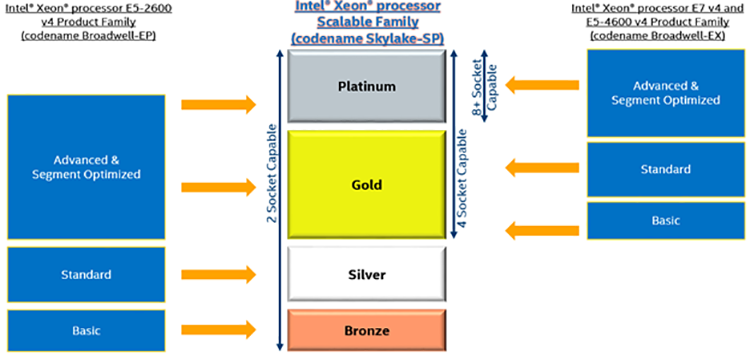
Figure 2. New branding for processor models.
A two-socket Intel Xeon processor Scalable family configuration can be found within all the levels of bronze through platinum, while a four-socket configuration will only be found at the gold through platinum levels, and the eight-socket configuration will only be found at the platinum level. The bronze level has the least amount of features and as you move towards platinum more features are added. All available features are available across the entire range of processor socket count (two through eight) at the platinum level.
Introduction
This paper discusses the new features and enhancements available in Intel Xeon processor Scalable family and what developers need to do to take advantage of them.
Intel® Xeon® processor Scalable family Microarchitecture Overview
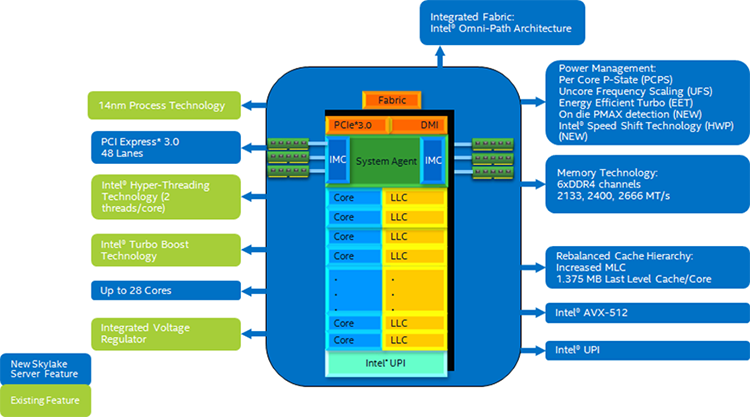
Figure 3. Block Diagram of the Intel® Xeon® processor Scalable family microarchitecture.
The Intel Xeon processor Scalable family on the Purley platform provides up to 28 cores, which bring additional computing power to the table compared to the 22 cores of its predecessor. Additional improvements include a non-inclusive last-level cache, a larger 1MB L2 cache, faster 2666 MHz DDR4 memory, an increase to six memory channels per CPU, new memory protection features, Intel® Speed Shift Technology, on-die PMAX detection, integrated Fabric via Cornelis Networks, Internet Wide Area RDMA Protocol (iWARP)*, Intel® Virtual RAID on CPU (Intel® VROC), and more.
Table 1. Generational comparison of the Intel Xeon processor Scalable family to the Intel® Xeon® processor E5-2600 and E7-4600 product families.

Intel Xeon processor Scalable family feature overview
The rest of this paper discusses the performance improvements, new capabilities, security enhancements, and virtualization enhancements in the Intel Xeon processor Scalable family.
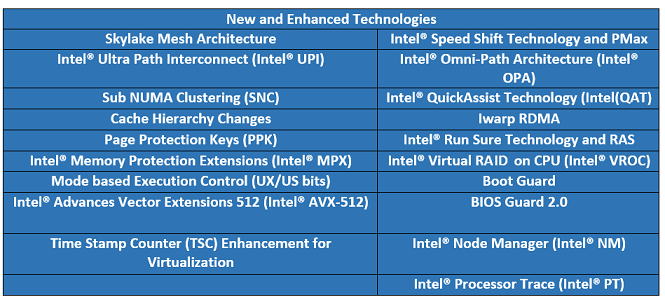
Table 2. New features and technologies of the Intel Xeon processor Scalable family.
Skylake Mesh Architecture
On the previous generations of Intel® Xeon® processor families (formerly Haswell and Broadwell) on the Grantley platform, the processors, the cores, last-level cache (LLC), memory controller, IO controller and inter-socket Intel® QuickPath Interconnect (Intel® QPI) ports are connected together using a ring architecture, which has been in place for the last several generations of Intel® multi-core CPUs. As the number of cores on the CPU increased with each generation, the access latency increased and available bandwidth per core diminished. This trend was mitigated by dividing the chip into two halves and introducing a second ring to reduce distances and to add additional bandwidth.
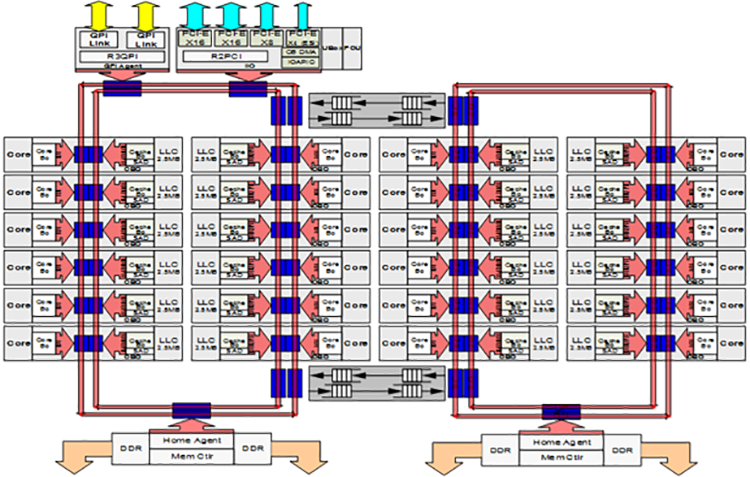
Figure 4. Intel® Xeon® processor E5-2600 product family (formerly Broadwell-EP) on Grantley platform ring architecture.
With additional cores per processor and much higher memory and I/O bandwidth in the Intel® Xeon® processor Scalable family, the additional demands on the on-chip interconnect could become a performance limiter with the ring-based architecture. Therefore, the Intel Xeon processor Scalable family introduces a mesh architecture to mitigate the increased latencies and bandwidth constraints associated with previous ring-based architecture. The Intel Xeon processor Scalable family also integrates the caching agent, the home agent, and the IO subsystem on the mesh interconnect in a modular and distributed way to remove bottlenecks in accessing these functions. Each core and LLC slice has a combined Caching and Home Agent (CHA), which provides scalability of resources across the mesh for Intel® Ultra Path Interconnect (Intel® UPI) cache coherency functionality without any hotspots.
The Intel Xeon processor Scalable family mesh architecture encompasses an array of vertical and horizontal communication paths allowing traversal from one core to another through a shortest path (hop on vertical path to correct row, and hop across horizontal path to correct column). The CHA located at each of the LLC slices maps addresses being accessed to specific LLC bank, memory controller, or IO subsystem, and provides the routing information required to reach its destination using the mesh interconnect.
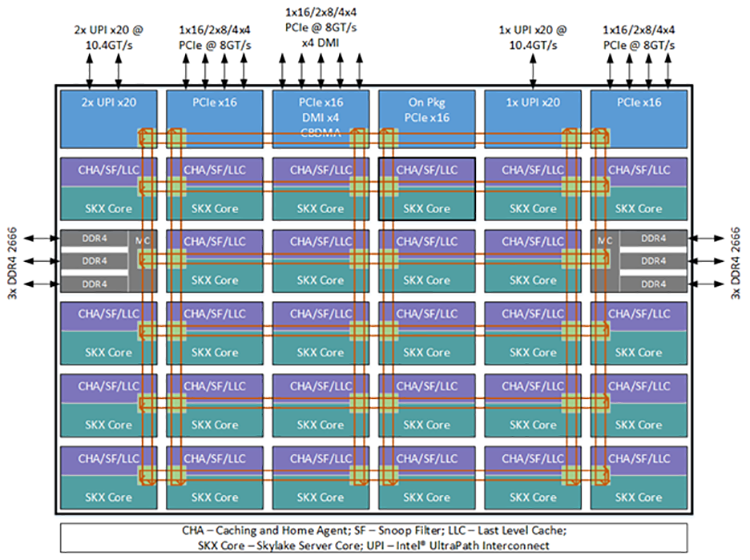
Figure 5. Intel Xeon processor Scalable family mesh architecture.
In addition to the improvements expected in the overall core-to-cache and core-to-memory latency, we also expect to see improvements in latency for IO initiated accesses. In the previous generation of processors, in order to access data in LLC, memory or IO, a core or IO would need to go around the ring and arbitrate through the switch between the rings if the source and targets are not on the same ring. In Intel Xeon processor Scalable family, a core or IO can access the data in LLC, memory, or IO through the shortest path over the mesh.
Intel® Ultra Path Interconnect (Intel® UPI)
The previous generation of Intel® Xeon® processors utilized Intel QPI, which has been replaced on the Intel Xeon processor Scalable family with Intel UPI. Intel UPI is a coherent interconnect for scalable systems containing multiple processors in a single shared address space. Intel Xeon processors that support Intel UPI, provide either two or three Intel UPI links for connecting to other Intel Xeon processors and do so using a high-speed, low-latency path to the other CPU sockets. Intel UPI uses a directory-based home snoop coherency protocol, which provides an operational speed of up to 10.4 GT/s, improves power efficiency through an L0p state low-power state, provides improved data transfer efficiency over the link using a new packetization format, and has improvements at the protocol layer such as no preallocation to remove scalability limits with Intel QPI.
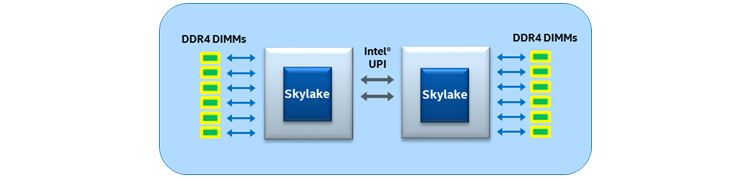
Figure 6. Typical two- socket configuration.
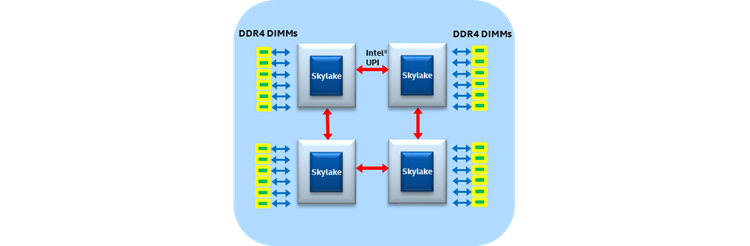
Figure 7. Typical four-socket ring configuration.
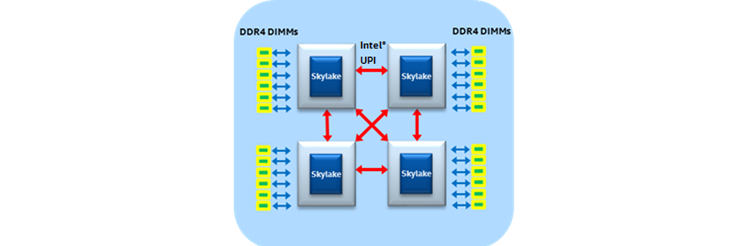
Figure 8. Typical four-socket crossbar configuration.
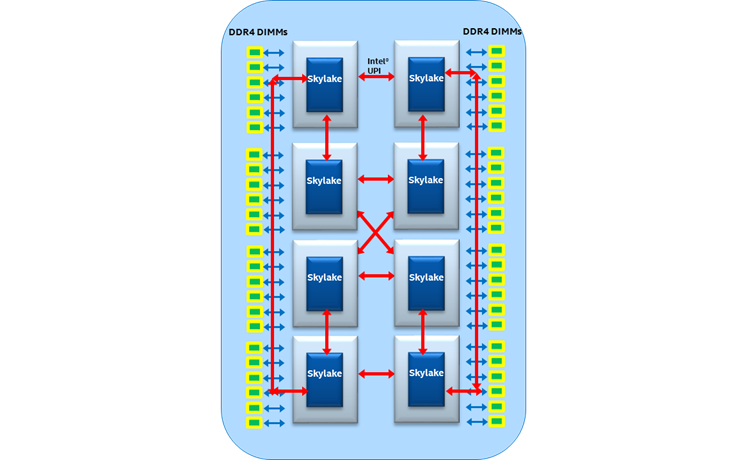
Figure 9. Typical eight-socket configuration.
Intel® Ultra Path Interconnect Caching and Home Agent
Previous implementations of Intel Xeon processors provided a distributed Intel QPI caching agent located with each core and a centralized Intel QPI home agent located with each memory controller. Intel Xeon processor Scalable family processors implement a combined CHA that is distributed and located with each core and LLC bank, and thus provides resources that scale with the number of cores and LLC banks. CHA is responsible for tracking of requests from the core and responding to snoops from local and remote agents as well as resolution of coherency across multiple processors.
Intel UPI removes the requirement on preallocation of resources at the home agent, which allows the home agent to be implemented in a distributed manner. The distributed home agents are still logically a single Intel UPI agent that is address-interleaved across different CHAs, so the number of visible Intel UPI nodes is always one, irrespective of the number of cores, memory controllers used, or the sub-NUMA clustering mode. Each CHA implements a slice of the aggregated CHA functionality responsible for a portion of the address space mapped to that slice.
Sub-NUMA Clustering
A sub-NUMA cluster (SNC) is similar to a cluster-on-die (COD) feature that was introduced with Haswell, though there are some differences between the two. An SNC creates two localization domains within a processor by mapping addresses from one of the local memory controllers in one half of the LLC slices closer to that memory controller and addresses mapped to the other memory controller into the LLC slices in the other half. Through this address-mapping mechanism, processes running on cores on one of the SNC domains using memory from the memory controller in the same SNC domain observe lower LLC and memory latency compared to latency on accesses mapped to locations outside of the same SNC domain.
Unlike a COD mechanism where a cache line could have copies in the LLC of each cluster, SNC has a unique location for every address in the LLC, and it is never duplicated within the LLC banks. Also, localization of addresses within the LLC for each SNC domain applies only to addresses mapped to the memory controllers in the same socket. All addresses mapped to memory on remote sockets are uniformly distributed across all LLC banks independent of the SNC mode. Therefore even in the SNC mode, the entire LLC capacity on the socket is available to each core, and the LLC capacity reported through the CPUID is not affected by the SNC mode.
Figure 10 represents a two-cluster configuration that consists of SNC Domain 0 and 1 in addition to their associated core, LLC, and memory controllers. Each SNC domain contains half of the processors on the socket, half of the LLC banks, and one of the memory controllers with three DDR4 channels. The affinity of cores, LLC, and memory within a domain are expressed using the usual NUMA affinity parameters to the OS, which can take SNC domains into account in scheduling tasks and allocating memory to a process for optimal performance.
SNC requires that memory is not interleaved in a fine-grain manner across memory controllers. In addition, SNC mode has to be enabled by BIOS to expose two SNC domains per socket and set up resource affinity and latency parameters for use with NUMA primitives.
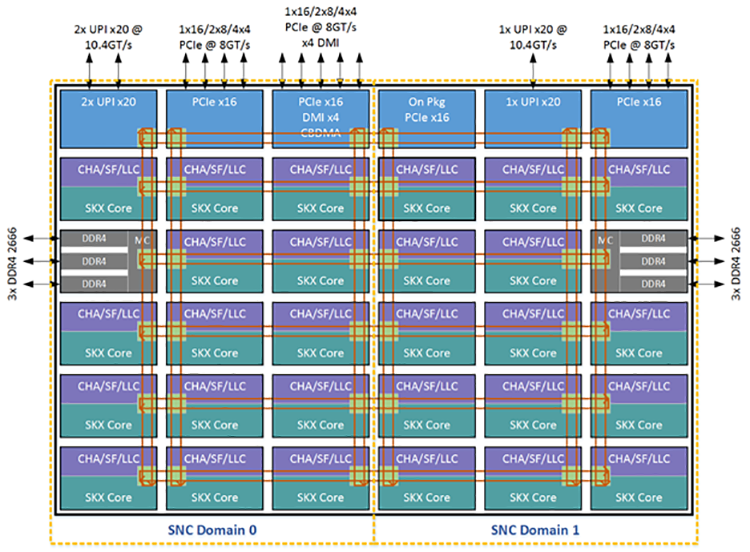
Figure 10. Sub-NUMA cluster domains.
Directory-Based Coherency
Unlike the prior generation of Intel Xeon processors that supported four different snoop modes (no-snoop, early snoop, home snoop, and directory), the Intel Xeon processor Scalable family of processors only supports the directory mode. With the change in cache hierarchy to a non-inclusive LLC, the snoop resolution latency can be longer depending on where in the cache hierarchy a cache line is located. Also, with much higher memory bandwidth, the inter-socket Intel UPI bandwidth is a much more precious resource and could become a bottleneck in system performance if unnecessary snoops are sent to remote sockets. As a result, the optimization trade-offs for various snoop modes are different in Intel Xeon processor Scalable family compared to previous Intel Xeon processors, and therefore the complexity of supporting multiple snoop modes is not beneficial.
The Intel Xeon processor Scalable family carries forward some of the coherency optimizations from prior generations and introduces some new ones to reduce the effective memory latency. For example, some of the directory caching optimizations such as IO directory cache and HitME cache are still supported and further enhanced on the Intel Xeon processor Scalable family. The opportunistic broadcast feature is also supported, but it is used only with writes to local memory to avoid memory access due to directory lookup.
For IO directory cache (IODC), the Intel Xeon processor Scalable family provides an eight-entry directory cache per CHA to the cache directory state of IO writes from remote sockets. IO writes usually require multiple transactions to invalidate a cache line from all caching agents followed by a writeback to put updated data in memory or home sockets LLC. With the directory information stored in memory, multiple accesses may be required to retrieve and update directory state. IODC reduces accesses to memory to complete IO writes by keeping the directory information cached in the IODC structure.
HitME cache is another capability in the CHA that caches directory information for speeding up cache-to-cache transfer. With the distributed home agent architecture of the CHA, the HitME cache resources scale with number of CHAs.
Opportunistic Snoop Broadcast (OSB) is another feature carried over from previous generations into the Intel Xeon processor Scalable family. OSB broadcasts snoops when the Intel UPI link is lightly loaded, thus avoiding a directory lookup from memory and reducing memory bandwidth. In the Intel Xeon processor Scalable family, OSB is used only for local InvItoE (generated due to full-line writes from the core or IO) requests since data read is not required for this operation. Avoiding directory lookup has a direct impact on saving memory bandwidth.
Cache Hierarchy Changes
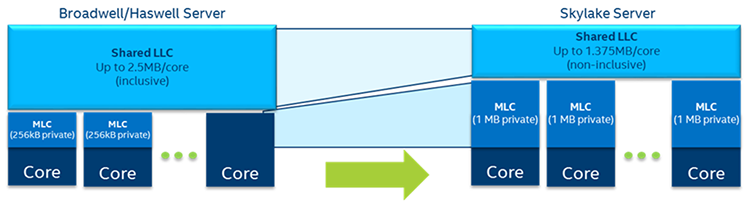
Figure 11. Generational cache comparison.
In the previous generation the mid-level cache was 256 KB per core and the last level cache was a shared inclusive cache with 2.5 MB per core. In the Intel Xeon processor Scalable family, the cache hierarchy has changed to provide a larger MLC of 1 MB per core and a smaller shared non-inclusive 1.375 MB LLC per core. A larger MLC increases the hit rate into the MLC resulting in lower effective memory latency and also lowers demand on the mesh interconnect and LLC. The shift to a non-inclusive cache for the LLC allows for more effective utilization of the overall cache on the chip versus an inclusive cache.
If the core on the Intel Xeon processor Scalable family has a miss on all the levels of the cache, it fetches the line from memory and puts it directly into MLC of the requesting core, rather than putting a copy into both the MLC and LLC as was done on the previous generation. When the cache line is evicted from the MLC, it is placed into the LLC if it is expected to be reused.
Due to the non-inclusive nature of LLC, the absence of a cache line in LLC does not indicate that the line is not present in private caches of any of the cores. Therefore, a snoop filter is used to keep track of the location of cache lines in the L1 or MLC of cores when it is not allocated in the LLC. On the previous-generation CPUs, the shared LLC itself took care of this task.
Even with the changed cache hierarchy in Intel Xeon processor Scalable family, the effective cache available per core is roughly the same as the previous generation for a usage scenario where different applications are running on different cores. Because of the non-inclusive nature of LLC, the effective cache capacity for an application running on a single core is a combination of MLC cache size and a portion of LLC cache size. For other usage scenarios, such as multithreaded applications running across multiple cores with some shared code and data, or a scenario where only a subset of the cores on the socket are used, the effective cache capacity seen by the applications may seem different than previous-generation CPUs. In some cases, application developers may need to adapt their code to optimize it with the changed cache hierarchy on the Intel Xeon processor Scalable family of processors.
Page Protection Keys
Because of stray writes, memory corruption is an issue with complex multithreaded applications. For example, not every part of the code in a database application needs to have the same level of privilege. The log writer should have write privileges to the log buffer, but it should have only read privileges on other pages. Similarly, in an application with producer and consumer threads for some critical data structures, producer threads can be given additional rights over consumer threads on specific pages.
The page-based memory protection mechanism can be used to harden applications. However, page table changes are costly for performance since these changes require Translation Lookaside Buffer (TLB) shoot downs and subsequent TLB misses. Protection keys provide a user-level, page-granular way to grant and revoke access permission without changing page tables.
Protection keys provide 16 domains for user pages and use bits 62:59 of the page table leaf nodes (for example, PTE) to identify the protection domain (PKEY). Each protection domain has two permission bits in a new thread-private register called PKRU. On a memory access, the page table lookup is used to determine the protection domain (PKEY) of the access, and the corresponding protection domain-specific permission is determined from PKRU register content to see if access and write permission is granted. An access is allowed only if both protection keys and legacy page permissions allow the access. Protection keys violations are reported as page faults with a new page fault error code bit. Protection keys have no effect on supervisor pages, but supervisor accesses to user pages are subject to the same checks as user accesses.
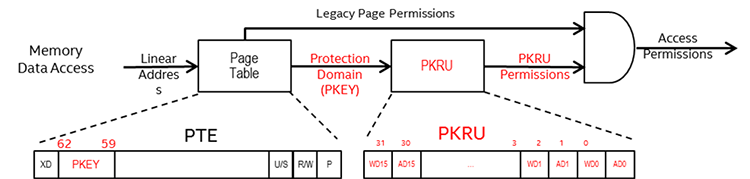
Figure 12. Diagram of memory data access with protection key.
In order to benefit from protection keys, support is required from the virtual machine manager, OS, and complier. Utilizing this feature does not cause a performance impact because it is an extension of the memory management architecture.
Intel® Memory Protection Extensions (Intel® MPX)
C/C++ pointer arithmetic is a convenient language construct often used to step through an array of data structures. If an iterative write operation does not take into consideration the bounds of the destination, adjacent memory locations may get corrupted. Such unintended modification of adjacent data is referred as a buffer overflow. Buffer overflows have been known to be exploited, causing denial-of-service (DoS) attacks and system crashes. Similarly, uncontrolled reads could reveal cryptographic keys and passwords. More sinister attacks, which do not immediately draw the attention of the user or system administrator, alter the code execution path such as modifying the return address in the stack frame to execute malicious code or script.
Intel’s Execute Disable Bit and similar hardware features from other vendors have blocked buffer overflow attacks that redirected the execution to malicious code stored as data. Intel® MPX technology consists of new Intel® architecture instructions and registers that compilers can use to check the bounds of a pointer at runtime before it is used. This new hardware technology is supported by the compiler.
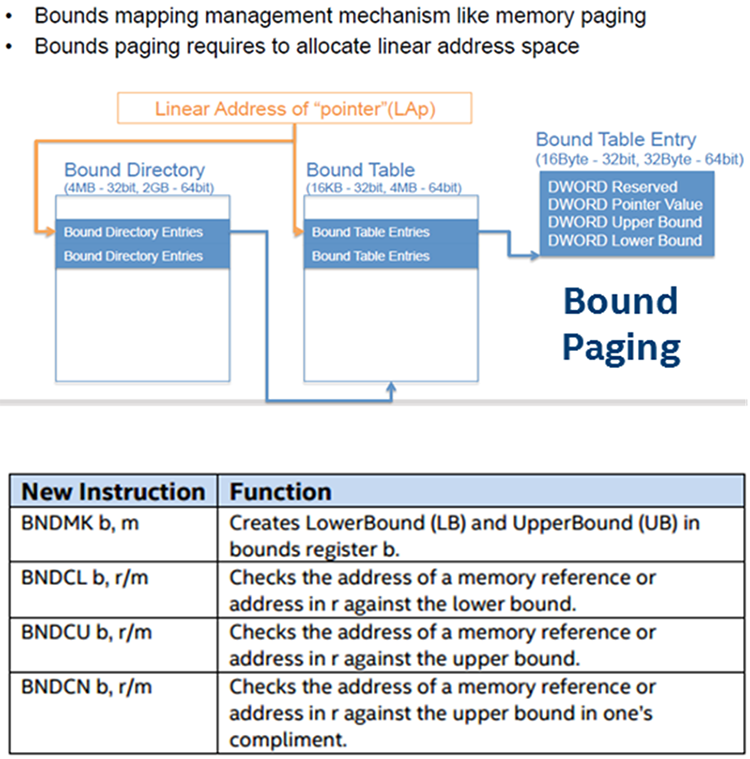
Figure 13. New Intel® Memory Protection Extensions instructions and example of their effect on memory.
For additional information see Intel® Memory Protection Extensions Enabling Guide.
Mode-Based Execute (MBE) Control
MBE provides finer grain control on execute permissions to help protect the integrity of the system code from malicious changes. It provides additional refinement within the Extended Page Tables (EPT) by turning the Execute Enable (X) permission bit into two options:
- XU for user pages
- XS for supervisor pages
The CPU selects one or the other based on permission of the guest page and maintains an invariant for every page that does not allow it to be writable and supervisor-executable at the same time. A benefit of this feature is that a hypervisor can more reliably verify and enforce the integrity of kernel-level code. The value of the XU/XS bits is delivered through the hypervisor, so hypervisor support is necessary.
Intel® Advanced Vector Extensions 512 (Intel® AVX-512)
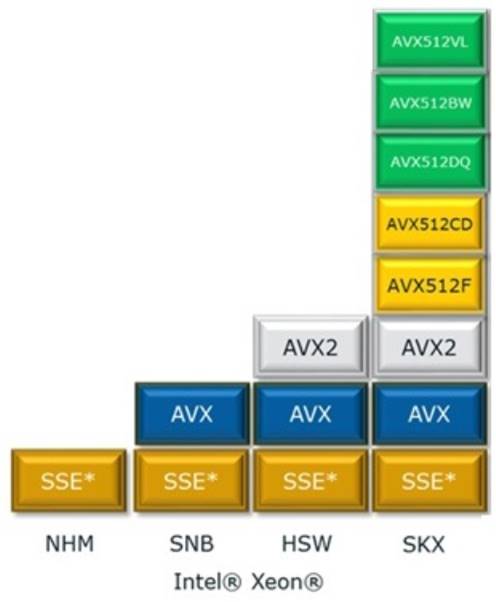
Figure 14. Generational overview of Intel® Advanced Vector Extensions technology.
The Intel Xeon processor Scalable family introduces new Intel AVX-512 instruction groups (AVX512BW and AVX512DQ) as well as a new capability (AVX512VL) to expand the benefits of the technology. The AVX512DQ instruction group is focused on new additions for benefiting high-performance computing (HPC) workloads such as oil and gas, seismic modeling, financial services industry, molecular dynamics, ray tracing, double-precision matrix multiplication, fast Fourier transform and convolutions, and RSA cryptography. The AVX512BW instruction group supports Byte/Word operations, which can benefit some enterprise applications, media applications, as well as HPC. AVX512VL is not an instruction group but a feature that is associated with vector length orthogonality.
Broadwell, the previous processor generation, has up to two floating point FMAs (Fused Multiple Add) per core and this has not changed with the Intel Xeon processor Scalable family. However the Intel Xeon processor Scalable family doubles the number of elements that can be processed compared to Broadwell as the FMAs on the Intel Xeon processor Scalable family of processors have been expanded from 256 bits to 512 bits.

Figure 15. Generation feature comparison of Intel® Advanced Vector Extensions technology.
Intel AVX-512 instructions offer the highest degree of support to software developers by including an unprecedented level of richness in the design of the instructions. This includes 512-bit operations on packed floating-point data or packed integer data, embedded rounding controls (override global settings), embedded broadcast, embedded floating-point fault suppression, embedded memory fault suppression, additional gather/scatter support, high-speed math instructions, and compact representation of large displacement value. The following sections cover some of the details of the new features of Intel AVX-512.
AVX512DQ
The doubleword and quadword instructions, indicated by the AVX512DQ CPUID flag enhance integer and floating-point operations, consisting of additional instructions that operate on 512-bit vectors whose elements are 16 32-bit elements or 8 64-bit elements. Some of these instructions provide new functionality such as the conversion of floating point numbers to 64-bit integers. Other instructions promote existing instructions such as with the vxorps instruction to use 512-bit registers.
AVX512BW
The byte and word instructions, indicated by the AVX512BW CPUID flag, enhance integer operations, extending write-masking and zero-masking to support smaller element sizes. The original Intel AVX-512 Foundation instructions supported such masking with vector element sizes of 32 or 64 bits, because a 512-bit vector register could hold at most 16 32-bit elements, so a write mask size of 16 bits was sufficient.
An instruction indicated by an AVX512BW CPUID flag requires a write mask size of up to 64 bits because a 512-bit vector register can hold 64 8-bit elements or 32 16-bit elements. Two new mask types (_mmask32 and _mmask64) along with additional maskable intrinsics have been introduced to support this operation.
AVX512VL
An additional orthogonal capability known as Vector Length Extensions provide for most Intel AVX-512 instructions to operate on 128 or 256 bits, instead of only 512. Vector Length Extensions can currently be applied to most Foundation Instructions and the Conflict Detection Instructions, as well as the new Byte, Word, Doubleword, and Quadword instructions. These Intel AVX-512 Vector Length Extensions are indicated by the AVX512VL CPUID flag. The use of Vector Length Extensions extends most Intel AVX-512 operations to also operate on XMM (128-bit, SSE) registers and YMM (256-bit, AVX) registers. The use of Vector Length Extensions allows the capabilities of EVEX encodings, including the use of mask registers and access to registers 16..31, to be applied to XMM and YMM registers instead of only to ZMM registers.
Mask Registers
In previous generations of Intel® Advanced Vector Extensions and Intel® Advanced Vector Extensions 2, the ability to mask bits was limited to load and store operations. In Intel AVX-512 this feature has been greatly expanded with eight new opmask registers used for conditional execution and efficient merging of destination operands. The width of each opmask register is 64-bits, and they are identified as k0–k7. Seven of the eight opmask registers (k1–k7) can be used in conjunction with EVEX-encoded Intel AVX-512 Foundation Instructions to provide conditional processing, such as with vectorized remainders that only partially fill the register. While the Opmask register k0 is typically treated as a “no mask” when unconditional processing of all data elements is desired. Additionally, the opmask registers are also used as vector flags/element level vector sources to introduce novel SIMD functionality as seen in new instructions such as VCOMPRESSPS. Support for the 512-bit SIMD registers and the opmask registers is managed by the operating system using XSAVE/XRSTOR/XSAVEOPT instructions. (see Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 2B, and Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A).
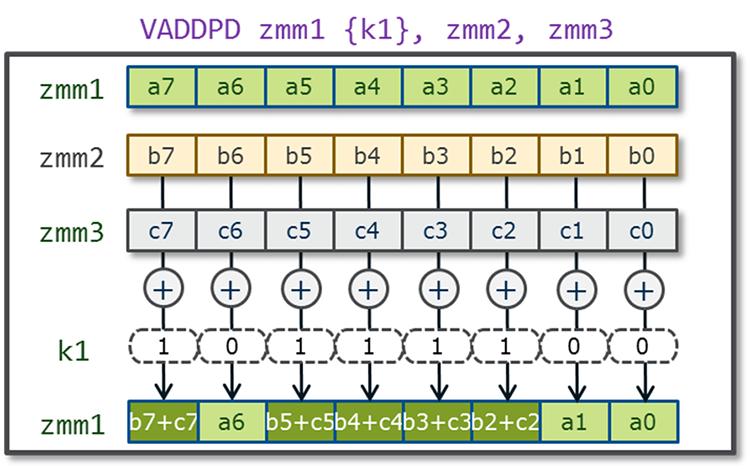
Figure 16. Example of opmask register k1.
Embedded Rounding
Embedded Rounding provides additional support for math calculations by allowing the floating point rounding mode to be explicitly specified for an individual operation, without having to modify the rounding controls in the MXCSR control register. In previous SIMD instruction extensions, rounding control is generally specified in the MXCSR control register, with a handful of instructions providing per-instruction rounding override via encoding fields within the imm8 operand. Intel AVX-512 offers a more flexible encoding attribute to override MXCSR-based rounding control for floating-pointing instruction with rounding semantic. This rounding attribute embedded in the EVEX prefix is called Static (per instruction) Rounding Mode or Rounding Mode override. Static rounding also implies exception suppression (SAE) as if all floating point exceptions are disabled, and no status flags are set. Static rounding enables better accuracy control in intermediate steps for division and square root operations for extra precision, while the default MXCSR rounding mode is used in the last step. It can also help in cases where precision is needed the least significant bit such as in range reduction for trigonometric functions.
Embedded Broadcast
Embedded broadcast provides a bit-field to encode data broadcast for some load-op instructions such as instructions that load data from memory and perform some computational or data movement operation. A source element from memory can be broadcasted (repeated) across all elements of the effective source operand, without requiring an extra instruction. This is useful when we want to reuse the same scalar operand for all operations in a vector instruction. Embedded broadcast is only enabled on instructions with an element size of 32 or 64 bits and not on byte and word instructions.
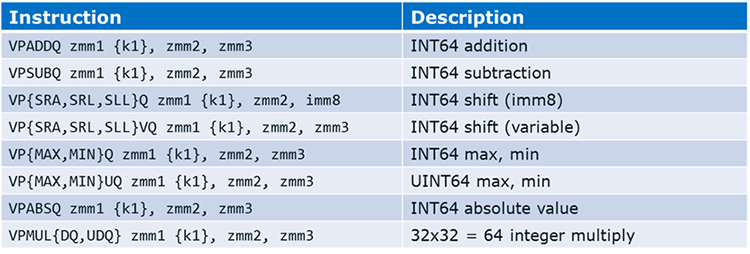
Quadword Integer Arithmetic
Quadword integer arithmetic removes the need for expensive software emulation sequences. These instructions include gather/scatter with D/Qword indices, and instructions that can partially execute, where k-reg mask is used as a completion mask.
Table 3. Quadword integer arithmetic instructions.
Math Support
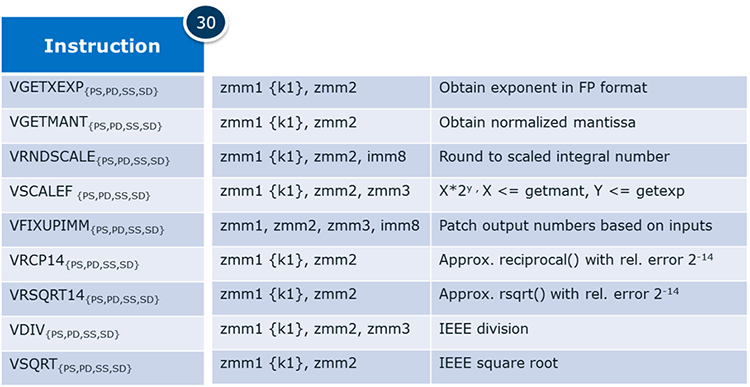
Math Support is designed to aid with math library writing and to benefit financial applications. Data types that are available include PS, PD, SS, and SS. IEEE division/square root formats, DP transcendental primitives, and new transcendental support instructions are also included.
Table 4. Math support instructions.
New Permutation Primitives
Intel AVX-512 introduces new permutation primitives such as 2-source shuffles with 16/32-entry table lookups with transcendental support, matrix transpose, and a variable VALIGN emulation.
Table 5. 2-Source shuffles instructions.

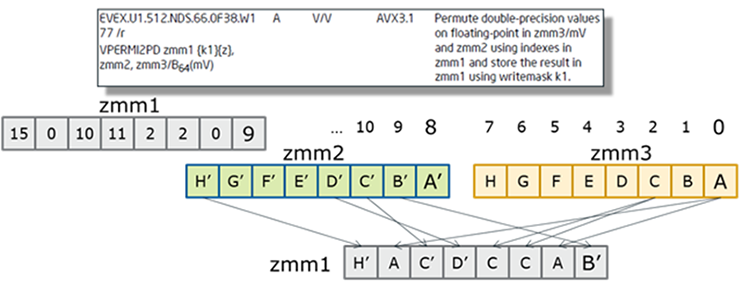
Figure 17. Example of a 2-source shuffles operation.
Expand and Compress
Expand and Compress allows vectorization of conditional loops. Similar to FORTRAN pack/unpack intrinsic it also provides memory fault suppression, can be faster than using gather/scatter, and also has opposite operation capability for compress. The figure below shows an example of an expand operation.
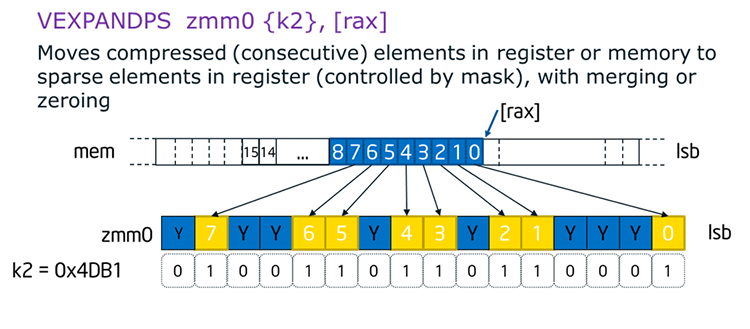
Figure 18. Expand instruction and diagram.
Bit Manipulation
Intel AVX-512 provides support for bit manipulation operations on mask and vector operands including Vector rotate. These operations can be used to manipulate mask registers and they have some application with cryptography algorithms.
Table 6. Bit manipulation instructions.
Universal Ternary Logical Operation
A universal ternary logical operation is another feature of Intel AVX-512 that provides a way to mimic an FPGA cell. The VPTERNLOGD and VPTERNLOGQ instructions operate on dword and qword elements and take three-bit vectors of the respective input data elements to form a set of 32/64 indices, where each 3-bit value provides an index into an 8-bit lookup table represented by the imm8 byte of the instruction. The 256 possible values of the imm8 byte is constructed as a 16x16 Boolean logic table, which can be filled with simple or compound Boolean logic expressions.
Conflict Detection Instructions
Intel AVX-512 introduces new conflict detection instructions. This includes the VPCONFLICT instruction along with a subset of supporting instructions. The VPCONFLICT instruction allows for detection of elements with previous conflicts in a vector of indexes. It can generate a mask with a subset of elements that are guaranteed to be conflict free. The computation loop can be re-executed with the remaining elements until all the indexes have been operated on.
Table 7. Conflict detection instructions.

VPCONFLICT{D,Q} zmm1{k1}{z}, zmm2/B(mV), For every element in ZMM2, compare it against everybody and generate a mask identifying the matches, but ignoring elements to the left of the current one, that is “newer.”
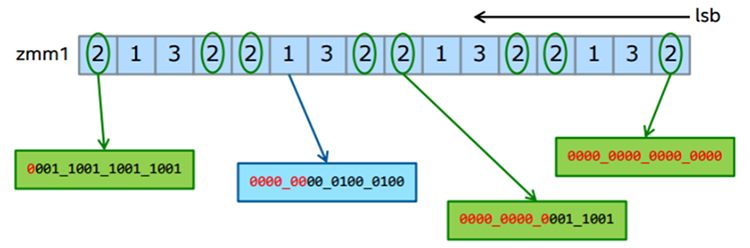
Figure 19. Diagram of mask generation for VPCONFLICT.
In order to benefit from CDI, use Intel compilers version 16.0 in Intel® C++ Composer XE 2016 which will recognize potential run-time conflicts and generate VPCONFLICT loops automatically
Transcendental Support
Additional 512-bit instruction extensions have been provided to accelerate certain transcendental mathematic computations and can be found in the instructions VEXP2PD, VEXP2PS, VRCP28xx, and VRSQRT28xx, also known as Intel AVX-512 Exponential and Reciprocal instructions. These can benefit some finance applications.
Compiler Support
Intel AVX-512 optimizations are included in Intel compilers version 16.0 in Intel C++ Composer XE 2016 and the GNU* Compiler Collection (GCC) 5.0 (NASM 2.11.08 and binutils 2.25). Table 8 summarizes compiler arguments for optimization on the Intel Xeon processor Scalable family microarchitecture with Intel AVX-512.
Table 8. Summary of Intel Xeon processor Scalable family compiler optimizations.

For more information see Intel® Architecture Instruction Set Extensions Programming Reference
Time Stamp Counter (TSC) Enhancement for Virtualization
The Intel Xeon processor Scalable family introduces a new TSC scaling feature to assist with migration of a virtual machine across different systems. In previous Intel Xeon processors, the TSC of a VM cannot automatically adjust itself to compensate for a processor frequency difference as it migrates from one platform to another. The Intel Xeon processor Scalable family enhances TSC virtualization support by adding a scaling feature in addition to the offsetting feature available in prior-generation CPUs. For more details on this feature see Intel® 64 SDM (search for “TSC Scaling”, e.g., Vol 3A – Sec 24.6.5, Sec 25.3, Sec 36.5.2.6).
Intel® Speed Shift Technology
Broadwell introduced Hardware Power Management (HWPM), a new optional processor power management feature in the hardware that liberates the OS from making decisions about processor frequency. HWPM allows the platform to provide information on all available constraints, allowing the hardware to choose optimal operating point. Operating independently, the hardware uses information that is not available to software and is able to make a more optimized decision in regard to the p-states and c-states. The Intel Xeon processor Scalable family on the Purley platform expands on this feature by providing a broader range of states that it can affect as well as a finer level of granularity and microarchitecture observability via the Package Control Unit (PCU). On Broadwell the HWPM was autonomous also known as Out-of-Band (OOB) mode and oblivious to the operating system, the Intel Xeon processor Scalable family allows for this as well but also offers the option for a collaboration between the HWPM and the operating system, known as native mode. The operating system can directly control the tuning of the performance and power profile when and where it is desired, while elsewhere the PCU can take autonomous control in the absence of constraints placed by the operating system. In native mode The Intel Xeon processor Scalable family is able to optimize frequency control for legacy operating systems, while providing new usage models for modern operating systems. The end user can set these options within the BIOS; see your OEM BIOS guide for more information. Modern operating systems that provide full integration with native mode include Linux* starting with kernel 4.10 and Windows Server* 2016.
PMax Detection
A processor implemented detection circuit provides faster detection and response to PMax level load events. Previously PMax detection circuits resided in either the power supply unit (PSU) or on the system board, while the new detection circuit on the Intel Xeon processor Scalable family resides primarily on the processor side. In general, the PMax detection circuit provided with the Intel Xeon processor Scalable family allows for faster PMax detection and response time as compared to the prior-generation PMax detection methods. PMax detection allows for the processor to be throttled back when it detects that power limits are being hit. This can assist with PMax spikes associated with virus applications while in turbo mode, prior to the PSU reacting. A faster response time due to PMax load events potentially allows for possible power cost savings. The end user can set PMax detection within the BIOS; see your OEM BIOS guide for more information.
Cornelis Networks
Cornelis Networks, an element of Intel® Scalable System Framework, delivers the performance for tomorrow’s high performance computing (HPC) workloads and the ability to scale to tens of thousands of nodes—and eventually more—at a price competitive with today’s fabrics. The Cornelis* OPA 100 Series product line is an end-to-end solution of PCIe* adapters, silicon, switches, cables, and management software. As the successor to Intel® True Scale Fabric, this optimized HPC fabric is built upon a combination of enhanced IP and Intel® technology.
For software applications, Cornelis OPA will maintain consistency and compatibility with existing Intel True Scale Fabric and InfiniBand* APIs by working through the open source OpenFabrics Alliance (OFA) software stack on leading Linux distribution releases. Intel True Scale Fabric customers will be able to migrate to Cornelis OPA through an upgrade program.
The Intel Xeon processor Scalable family on the Purley platform supports Cornelis OPA in one of two forms: through the use of an Cornelis Omni-Path Host Fabric Interface 100 Series add-in card or through a specific processor model line (SKL-F) found within the Intel Xeon processor Scalable family that has a Host Fabric Interface integrated into the processor. The fabric integration on the processor has its own dedicated pathways on the motherboard and doesn’t impact the PCIe lanes available for add-in cards. The architecture is able to provide up to 100 Gb/s per processor socket.
Intel is working with the open source community to provide all host components with changes being pushed upstream in conjunction with Delta Package releases. OSVs are working in conjunction with Intel to incorporate into future OS distributions. While existing Message Passing Interface (MPI) programs and MPI libraries for Intel True Scale Fabric that use PSM will work as-is with Cornelis Omni-Path Host Fabric Interface without recompiling, although recompiling can expose additional benefit.
For software support Intel Download Center and complier support can be found in Intel® Parallel Studio XE 2017
Intel QuickAssist Technology
Intel® QuickAssist Technology (Intel® QAT) accelerates and compresses cryptographic workloads by offloading the data to hardware capable of optimizing those functions. This makes it easier for developers to integrate built-in cryptographic accelerators into network, storage, and security applications. In the case of the Intel Xeon processor Scalable family on the Purley platform, Intel QAT is integrated into the hardware of the Intel® C620 series chipset (formerly Lewisburg) on the Purley platform and offers outstanding capabilities including 100 Gbs Crypto, 100Gbs Compression, 100kops RSA, and 2k Decrypt. Segments that can benefit from the technology include the following:
- Server: secure browsing, email, search, big-data analytics (Hadoop), secure multi-tenancy, IPsec, SSL/TLS, OpenSSL
- Networking: firewall, IDS/IPS, VPN, secure routing, Web proxy, WAN optimization (IP Comp), 3G/4G authentication
- Storage: real-time data compression, static data compression, secure storage.
Supported Algorithms include the following:
- Cipher Algorithms: Null, ARC4, AES (key sizes 128,192, 256), DES, 3DES, Kasumi, Snow3G, and ZUC
- Hash/Authentication Algorithms Supported: MD5, SHA1, SHA-2 (output sizes 224,256,384,512), SHA-3 (output size 256 only), Advanced Encryption Standard (key sizes 128, 192, 256), Kasumi, Snow 3G, and ZUC
- Authentication Encryption (AEAD) Algorithm: AES (key sizes 128, 192, 256)
- Public Key Cryptography Algorithms: RSA, DSA, Diffie-Hellman (DH), Large Number Arithmetic, ECDSA, ECDH, EC, SM2 and EC25519
ZUC and SHA-3 are new algorithms that have been included in the third generation of Intel QuickAssist Technology found on the Intel® C620 series chipset.
Intel® Key Protection Technology (Intel® KPT) is a new supplemental feature of Intel QAT that can be found on the Intel Xeon processor Scalable family on the Purley platform with the Intel® C620 series chipset. Intel KPT has been developed to help secure cryptographic keys from platform level software and hardware attacks when the key is stored and used on the platform. This new feature focuses on protecting keys during runtime usage and is embodied within tools, techniques, and the API framework.
For a more detailed overview see Intel® QuickAssist Technology for Storage, Server, Networking and Cloud-Based Deployments. Programming and optimization guides can be found on the 01 Intel Open Source website.
Internet Wide Area RDMA Protocol (iWARP)
iWarp is a technology that allows network traffic managed by the NIC to bypass the kernel, which thus reduces the impact on the processor due to the absence of network-related interrupts. This is accomplished by the NICs communicating with each other via queue pairs to deliver traffic directly into the application user space. Large storage blocks and virtual machine migration tend to place more burden on the CPU due to the network traffic. This is where iWARP can be of benefit. Through the use of the queue pairs it is already known where the data needs to go and thus it is able to be placed directly into the application user space. This eliminates extra data copies between the kernel space and the user space that would normally occur without iWARP.
For more information see an information video on Accelerating Ethernet with iWARP Technology
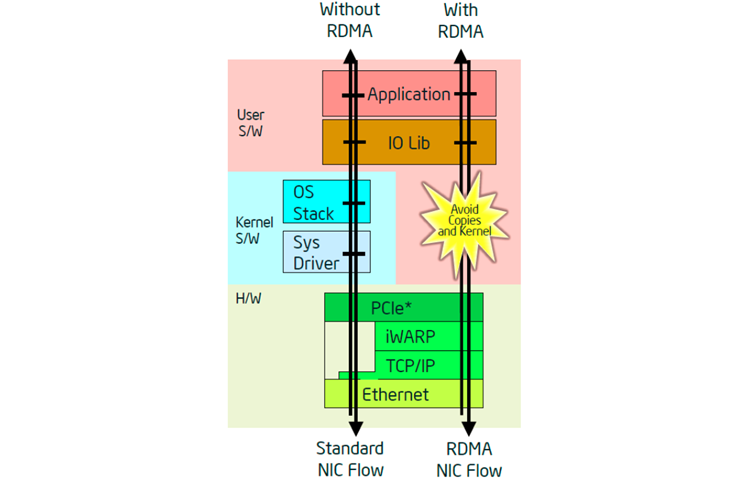
Figure 20. iWARP comparison block diagram.
The Purley platform has an Integrated Intel Ethernet Connection X722 with up to 4x10 GbE/1 Gb connections that provide iWARP support. This new feature can benefit various segments including network function virtualization and software-defined infrastructure. It can also be combined with the Data Plane Development Kit to provide additional benefits with packet forwarding.
iWARP uses VERB APIs to talk to each other instead of traditional sockets. For Linux* OFA OFED provides VERB APIs, while Windows* uses Network Direct APIs. Contact your Linux distribution to see if it supports OFED verbs, while on Windows support is provided starting with Windows Server 2012 R2 or newer.
New and Enhanced RAS Features
The Intel Xeon processor Scalable family on the Purley platform provides several new features as well as enhancements of some existing features associated with the RAS (Reliability, Availability, and Serviceability) and Intel® Run Sure Technology. Two levels of support are provided with the Intel Xeon processor Scalable family: Standard RAS and Advanced RAS. Advanced RAS includes all of the Standard RAS features along with additional features.
In previous generations there could be limitations in RAS features based on the processor socket count (2–8). This has changed and all of the RAS features are available on a two-socket version of the platform or greater depending on the level (bronze through platinum) of the processors. Listed below is a summary of the new and enhanced RAS features from the previous generation.
Table 9. RAS feature summary table.

Intel® Virtual RAID on CPU (Intel® VROC)
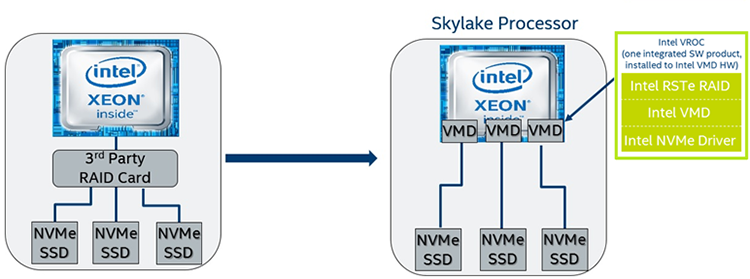
Figure 21. Intel® VROC replaces third-party raid cards.
Intel VROC is a software solution that integrates with a new hardware technology called Intel® Volume Management Device (Intel® VMD) to provide a compelling hybrid RAID solution for NVMe* (Non-Volatile Memory Express*) solid-state drives (SSDs). The CPU has onboard capabilities that work more closely with the chipset to provide quick access to the directly attached NVMe SSDs on the PCIe lanes of the platform. The major features that help to make this possible are Intel® Rapid Storage Technology enterprise (Intel® RSTe) version 5.0, Intel VMD, and the Intel provided NVMe driver.
Intel RSTe is a driver and application package that allows for administration of the RAID features. It has been updated (version 5.0) on the Purley platform to take advantage of all of the new features. The NVMe driver allows restrictions that might have been placed on it by an operating system to be bypassed. This means that features like hot insert could be available even if the OS doesn’t provide it, and the driver can also provide support for third-party vendor NVMe non-Intel SSDs.
Intel VMD is a new technology introduced with the Intel Xeon processor Scalable family primarily to improve the management of high-speed SSDs. Previously SSDs were attached to a SATA or other interface types and managing them through software was acceptable. When we move toward directly attaching the SSDs to a PCIe interface in order to improve bandwidth, software management of those SSDs adds more delays. Intel VMD uses hardware to mitigate these management issues rather than completely relying on software.
Some of the major RAID features provided by Intel VROC include the protected write-back cache, isolated storage devices from the OS (error handling), and protection of RAID 5 data from a RAID write hole issue through the use of software logging, which can eliminate the need for a battery backup unit. Direct attached NVMe RAID volumes are RAID bootable, have Hot Insert and Surprise Removal capability, provide LED management options, 4K native NVMe SSD support, and multiple management options including remote access from a webpage, interaction at the UEFI level for pre-OS tasks, and a GUI interface at the OS level.
Boot Guard
Boot Guard adds another level of protection to the Purley platform by performing a cryptographic Root of Trust for Measurement (RTM) of the early firmware platform storage device such as the trusted platform module or Intel® Platform Trust Technology (Intel® PTT). It can also cryptographically verify early firmware using OEM-provided policies. Unlike Intel® Trusted Execution Technology (Intel® TXT), Boot Guard doesn’t have any software requirements; it is enabled at the factory, and it cannot be disabled. Boot Guard operates independently of Intel® TXT but it is also compatible with it. Boot Guard reduces the chance of malware exploiting the hardware or software components.
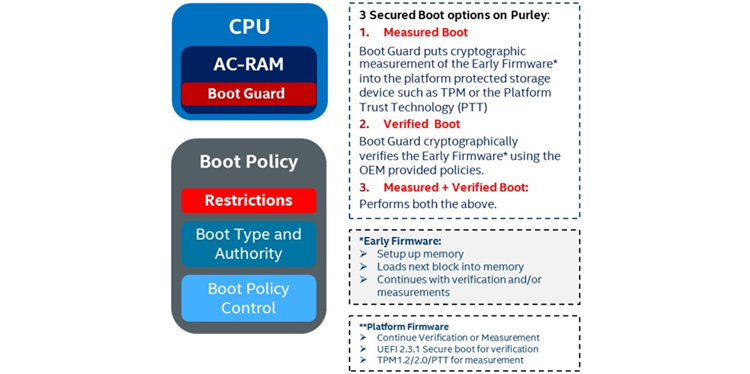
Figure 22. Boot Guard secure boot options.
BIOS Guard 2.0
BIOS Guard is an augmentation of existing chipset-based BIOS flash protection capabilities. The Purley platform adds the fault tolerant boot block update capability. The BIOS flash is segregated into a protected and unprotected regions. Purley bypasses the top-swap feature and flash range register locks/protections, for explicitly enabled signed scripts, to facilitate the fault-tolerant boot block update. This feature protects the BIOS flash from modification without the platform manufacturer’s authorization, as well as during BIOS updates. It can also help defend the platform from low-level DOS attacks.
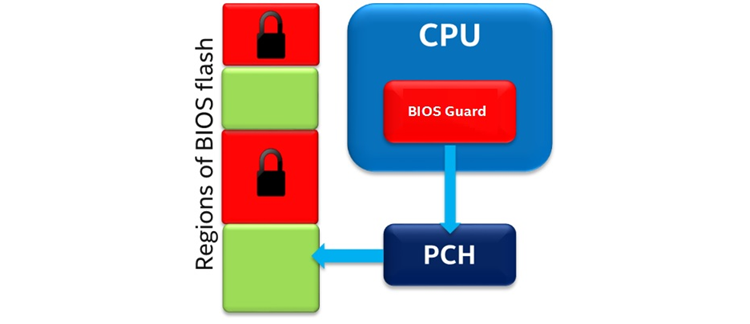
Figure 23. BIOS Guard 2.0 block diagram.
Intel® Processor Trace
Intel® Processor Trace (Intel® PT) is an exciting feature with improved support on the Intel Xeon processor Scalable family that can be enormously helpful in debugging, because it exposes an accurate and detailed trace of activity with triggering and filtering capabilities to help with isolating the tracing that matters.
Intel PT provides the context around all kinds of events. Performance profilers can use Intel PT to discover the root causes of “response-time” issues—performance issues that affect the quality of execution, if not the overall runtime.
Further, the complete tracing provided by Intel PT enables a much deeper view into execution than has previously been commonly available; for example, loop behavior, from entry and exit down to specific back-edges and loop tripcounts, is easy to extract and report.
Debuggers can use Intel PT to reconstruct the code flow that led to the current location, whether this is a crash site, a breakpoint, a watchpoint, or simply the instruction following a function call we just stepped over. They may even allow navigating in the recorded execution history via reverse stepping commands.
Another important use case is debugging stack corruptions. When the call stack has been corrupted, normal frame unwinding usually fails or may not produce reliable results. Intel PT can be used to reconstruct the stack back trace based on actual CALL and RET instructions.
Operating systems could include Intel PT into core files. This would allow debuggers to not only inspect the program state at the time of the crash, but also to reconstruct the control flow that led to the crash. It is also possible to extend this to the whole system to debug kernel panics and other system hangs. Intel PT can trace globally so that when an OS crash occurs, the trace can be saved as part of an OS crash dump mechanism and then used later to reconstruct the failure.
Intel PT can also help to narrow down data races in multi-threaded operating systems and user program code. It can log the execution of all threads with a rough time indication. While it is not precise enough to detect data races automatically, it can give enough information to aid in the analysis.
To utilize Intel PT you need Intel® VTune™ Amplifier version 2017.
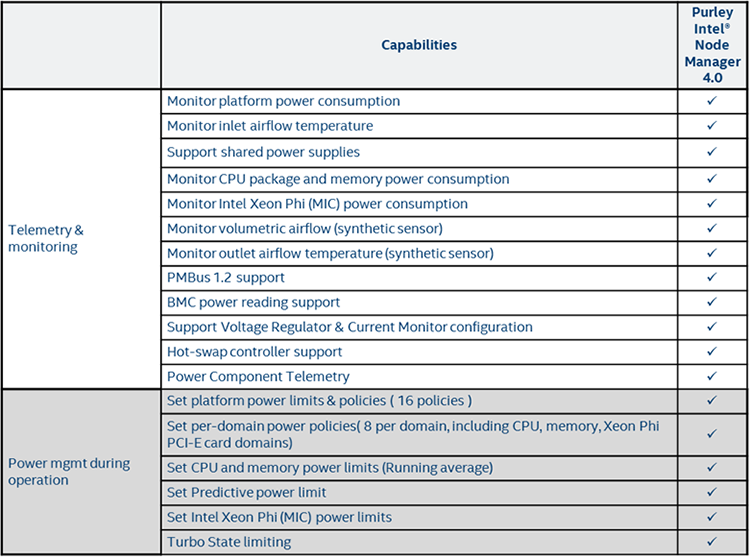
Intel® Node Manager
Intel® Node Manager (Intel® NM) is a core set of power management features that provide a smart way to optimize and manage power, cooling, and compute resources in the data center. This server management technology extends component instrumentation to the platform level and can be used to make the most of every watt consumed in the data center. First, Intel NM reports vital platform information, such as power, temperature, and resource utilization using standards-based, out-of-band communications. Second, it provides fine-grained controls, such as helping with reduction of overall power consumption or maximizing rack loading, to limit platform power in compliance with IT policy. This feature can be found across Intel’s product segments, including the Intel Xeon processor Scalable family, providing consistency within the data center.
The Intel Xeon processor Scalable family on the Purley platform includes the fourth generation of Intel NM, which extends control and reporting to a finer level of granularity than on the previous generation. To use this feature you must enable the BMC LAN and the associated BMC user configuration at the BIOS level, which should be available under the server management menu. The Programmer’s Reference Kit is simple to use and requires no additional external libraries to compile or run. All that is needed is a C/C++ compiler and to then run the configuration and compilation scripts.
Table 10. Intel Node Manager fourth-generation features
The Author: David Mulnix is a software engineer and has been with Intel Corporation for over 20 years. His areas of focus has included software automation, server power, and performance analysis, and he has contributed to the development support of the Server Efficiency Rating ToolTM.
Contributors: Akhilesh Kumar and Elmoustapha Ould-ahmed-vall
Resources
Intel® 64 and IA-32 Architectures Software Developer’s Manual (SDM)
Intel® Architecture Instruction Set Extensions Programming Reference
Intel® Resource Director Technology (Intel® RDT)
Optimize Resource Utilization with Intel® Resource Director Technology
Intel® Memory Protection Extensions Enabling Guide
Intel® Scalable System Framework
Processor tracing by James Reinders
How to set up Intel® Node Manager
Intel® Performance Counter Monitor (Intel® PCM) a better way to measure CPU utilization