Contributors
Vish Viswanathan, Karthik Kumar, Thomas Willhalm, Sri Sakthivelu, Sharanyan Srikanthan
Introduction
An important factor in determining application performance is the time required for the application to fetch data from the processor’s cache hierarchy and from the memory subsystem. In a multi-socket system where Non-Uniform Memory Access (NUMA) is enabled, local memory latencies and cross-socket memory latencies will vary significantly. Besides latency, bandwidth (b/w) also plays a big role in determining performance. So, measuring these latencies and b/w is important to establish a baseline for the system under test, and for performance analysis.
Intel® Memory Latency Checker (Intel® MLC) is a tool used to measure memory latencies and b/w, and how they change with increasing load on the system. It also provides several options for more fine-grained investigation where b/w and latencies from a specific set of cores to caches or memory can be measured as well.
New Features Added In This Release
- Minor bug fixes, removal of Windows MSR driver
Installation
Intel® MLC supports both Linux and Windows*
Linux
- Copy the mlc binary to any directory on your system
- Intel® MLC dynamically links to GNU C library (glibc/lpthread) and this library must be present on the system
- Root privileges are required to run this tool as the tool modifies the H/W prefetch control MSR to enable/disable prefetchers for latency and b/w measurements. Refer readme documentation on running without root privileges
- MSR driver (not part of the install package) should be loaded. This can typically be done with 'modprobe msr' command if it is not already included
Windows
- In prior releases a Windows driver was included to modify the h/w prefetcher settings. But from this release onwards, this driver will not available. Refer to readme file for more details.
Previous releases of MLC s/w provided two sets of binaries (mlc and mlc_avx512). mlc_avx512 was compiled with newer tool chain to support AVX512 instructions while mlc binary supported SSE2 and AVX2 instructions. With MLC v3.7 release onwards, only one binary is provided which supports SSE2, AVX2 and AVX512 instructions. By default AVX512 instructions won’t be used whether the processor supports it or not unless -Z argument is added explicitly to the command line.
HW Prefetcher Control
It is challenging to accurately measure memory latencies on modern Intel processors as they have sophisticated h/w prefetchers. Intel® MLC automatically disables these prefetchers while measuring the latencies and restores them to their previous state on completion. The prefetcher control is exposed through MSR (Disclosure of Hardware Prefetcher Control on Some Intel® Processors) and MSR access requires root level permission. So, Intel® MLC needs to be run as ‘root’ on Linux. If Intel® MLC can’t be run with root permissions, please consult the readme.pdf that can be found in the download package.
What Does the Tool Measure
When the tool is launched without any argument, it automatically identifies the system topology and measures the following four types of information. A screen shot is shown for each.
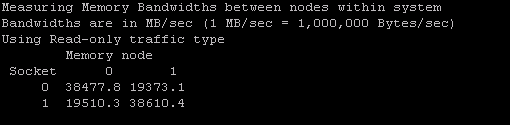
1. A matrix of idle memory latencies for requests originating from each of the sockets and addressed to each of the available sockets

2. Peak memory b/w measured (assuming all accesses are to local memory) for requests with varying amounts of reads and writes
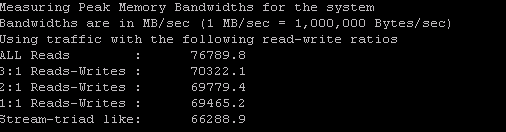
3. A matrix of memory b/w values for requests originating from each of the sockets and addressed to each of the available sockets
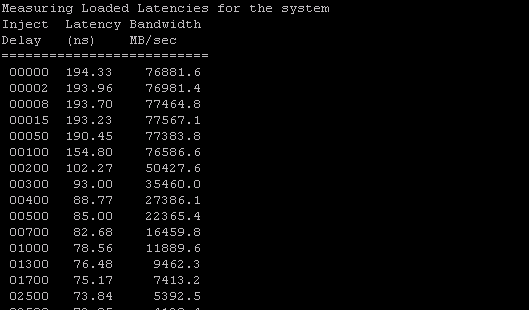
4. Latencies at different b/w points
It also measures cache-to-cache data transfer latencies.
Intel® MLC also provides command line arguments for fine grained control over latencies and b/w that are measured.
Here are some of the things that are possible with command line arguments:
- Measure latencies for requests addressed to a specific memory controller from a specific core
- Measure cache latencies
- Measure b/w from a subset of the cores/sockets
- Measure b/w for different read/write ratios
- Measure latencies for random address patterns instead of sequential
- Change stride size for latency measurements
- Measure cache-to-cache data transfer latencies
How Does It Work
One of the main features of Intel® MLC is measuring how latency changes as b/w demand increases. To facilitate this, it creates several threads where the number of threads matches the number of logical CPUs minus 1. These threads are used to generate the load (henceforth, these threads will be referred to as load-generation threads). The primary purpose of the load-generation threads is to generate as many memory references as possible. While the system is loaded like this, the remaining one CPU (that is not being used for load generation) runs a thread that is used to measure the latency. This thread is known as the latency thread and issues dependent reads. Basically, this thread traverses an array of pointers where each pointer is pointing to the next one, thereby creating a dependency in reads. The average time taken for each of these reads provides the latency. Depending on the load generated by the load-generation threads, this latency will vary. Every few seconds the load-generation threads automatically throttle the load generated by injecting delays, thus measuring the latency under various load conditions. Please refer to the readme file in the package that you download for more details.
Command Line Arguments
Launching Intel® MLC without any parameters measures several things as stated earlier. However, with command line arguments, each of the following specific actions can be performed in sequence:
mlc --latency_matrix
prints a matrix of local and cross-socket memory latencies
mlc --bandwidth_matrix
prints a matrix of local and cross-socket memory b/w
mlc --peak_injection_bandwidth
prints peak memory b/w (core generates requests at fastest possible rate) for various read-write ratios with all local accesses
mlc --max_bandwidth
prints maximum memory b/w (by automatically varying load injection rates) for various read-write ratios with all local accesses
mlc --idle_latency
prints the idle memory latency of the platform
mlc --loaded_latency
prints the loaded memory latency of the platform
mlc --c2c_latency
prints the cache-to-cache transfer latencies of the platform
mlc -e
do not modify prefetcher settings
mlc --memory_bandwidth_scan
prints memory bandwidth across entire memory for each 1 GB address range
There are more options for each of the commands above. Those are documented in the readme file in more detail and can be downloaded
Change Log
Version 1.0
- Initial release
Version 2.0
- Support for b/w and loaded latencies added
Version 2.1
- Launch 'spinner' threads on remote node for measuring better remote memory b/w
- Automatically disable numa balancing support (if present) to measure accurate remote memory latencies
Version 2.2
- Fixed a bug in topology detection where certain kernels were numbering the cpus differently. In those cases, consecutive cpu numbers were assigned to the same physical core (like cpus 0 and 1 are on physical core 0..)
Version 2.3
- Support for Windows O/S
- Support for single socket (E3 processor line)
- Support for turning off automatic prefetcher control
Version 3.0
- Support for client processors like Haswell and Skylake
- Allocate memory based on NUMA topology. This allows Intel® MLC to measure latencies on all the numa nodes on a processor like Haswell that supports Cluster-on-Die configuration where there are 4 numa nodes on a 2-socket system. We can also measure latencies to NUMA nodes which have only memory resources without any compute resources
- Support for measuring latencies and bandwidth to persistent memory
- Options to use 256-bit and 512-bit loads and stores in generating bandwidth traffic
- Support for measuring cache-to-cache data transfer latencies
- Control several parameters like read/write ratios, size of buffer allocated, numa node to allocate memory etc on a per-thread basis
Version 3.1
- Support for Skylake Server
Version 3.1a
- MLC failing on some guest VMs issue fixed
Version 3.3
- Several fixes for measuring latencies and b/w on Skylake server
Version 3.4
- Added support for multiple numa nodes on a socket on Windows server
- Several enhancements for measuring latencies and b/w on persistent memory
- Changed peak_bandwidth to peak_injection_bandwidth and added --max_bandwidth option to support automatically measure the best possible bandwidth
Version 3.5
- Fixed memory leak issues that caused MLC to fail on large systems (8-socket)
- Added option to flush cache lines to persistent memory
- Added option to only partially load/store cache line (loading only 16 bytes instead of entire 64 byte) to get best cache b/w
Version 3.6
- Better persistent memory support for Windows o/s
- Fix for numa nodes with no memory
- Fix for allocating more than 128 GB memory per thread in b/w tests
- Ability to specify -r -e in main invocation to deal with scenarios where prefetchers can't be turned off
Version 3.7
- Combined mlc and mlc_avx512 versions into one binary.
- Support for specifying where loaded latency thread can run besides the default cpu#0
- Automatically use random access for latency measurements if h/w prefetchers can't be controlled (due to permissions issue or running within a VM)
- Support for NUMA nodes with no CPU resources
Version 3.8
- Added support for 1 GB huge pages
- Fixed several issues with running MLC in VMs
- Improved CPU topology detection
Version 3.9
- Added support data integrity checks. Now, 100% reads can check the data against the expected values and report data corruption
- Fixes to report correct memory b/w if stores are included in the traffic for the next generation Intel Xeon processors
Version 3.9a
- Support for 3rd Generation Intel® Xeon® Scalable Processors
- New option --memory_bandwidth_scan (supported only on Linux) to be able to measure memory bandwidth over the entire address range in 1 GB chunks
Version 3.10
- Processor support: Added support for all the Intel processors expected to be released in the next 1-2 years
- Latency histogram: We have added a new feature to track the latency of each request and provide a histogram of latency distributions
- Specitom changes: With this release, MLC will automatically take care of reporting correct b/w for all read/write traffic mixes by not doing full 64-byte stores
- Linux CPU offlining : MLC will function properly even if CPUs are offlined on Linux
- Windows MSR driver: From this release onwards, MSR driver that is used to modify the prefetchers will not be used by default and only random accesses will be used to report latencies
Version 3.11
- Processor support: Added support for all the Intel processors expected to be released in the next 1-2 years
- Ability to measure bandwidth for 90% reads, 10% write traffic with -W19
Version 3.11a
- Processor support: Added support for Intel processors expected to be released in the next 1-2 years
- Minor bug fixes
Version 3.11b
- Minor bug fixes, Windows MSR driver removal
Version 3.12
- Minor bug fixes, Windows driver reintroduced to control prefetcher MSRs on Windows
Download
Both Linux and Windows versions of Intel® MLC are included in the download.