Code Generation, Interprocedural Optimization, and Floating-Point Precision
Mayank Tiwari, cloud software engineer,
and Rama Malladi, graphics performance engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
The compiler reports generated by the Intel® C, Intel® C++, and Intel® Fortran Compilers provide useful information for optimizing code. Previous articles in The Parallel Universe (see issues 41 and 42) discuss compiler reports for loop transformations and vectorization. This article covers code generation optimizations, interprocedural optimization (IPO), inlining, data alignment, OpenMP* and auto-parallelization, and floating-point precision reports. These reports highlight the code generation performed by the compiler and help to get better performance by making “last mile” code changes and optimizations.
Generate Optimization Reports
For the Intel C and Intel C++ Compiler on Linux* and macOS*, the -qopt-report[=n] option requests an optimization report. Use the /Qopt-report[:n] option on Windows*.) The n is optional and indicates the level of detail in the report: 0 (no report) through 5 (detailed report). This article discusses reports generated using -qopt-report=5 (detailed report).
Code Generation
The code generation optimizations section of the compiler report can help to determine the number of hardware registers available, used, and spills, fills. The simple C++ vector addition shown in Figure 1 gives the compiler optimization report shown in Figure 2. It shows detailed register usage for the input arguments, global and local variables, register spills, and stack usage.

Figure 1. Simple C++ vector addition
Registers are the closest memory to the arithmetic-logic units (ALUs) in a CPU, so reads and writes to registers are fast. For best performance, programmers should ensure that most of the variables in a routine can be accommodated in these registers. However, the number of registers is limited, so the compiler attempts to generate code for optimal allocation of these registers.
If a routine uses more variables than available registers, some variables may need to be stored and reloaded from the stack. This is known as register spilling. Sometimes it is unavoidable, but you can optimize register use by applying loop optimizations like loop fission when possible. If the compiler optimization report indicates a significant number of spills, this is referred to as a high register pressure performance issue. Recommended optimizations for register pressure include avoiding loop unrolling, loop fission, and having the compiler generate scalar plus vector code.
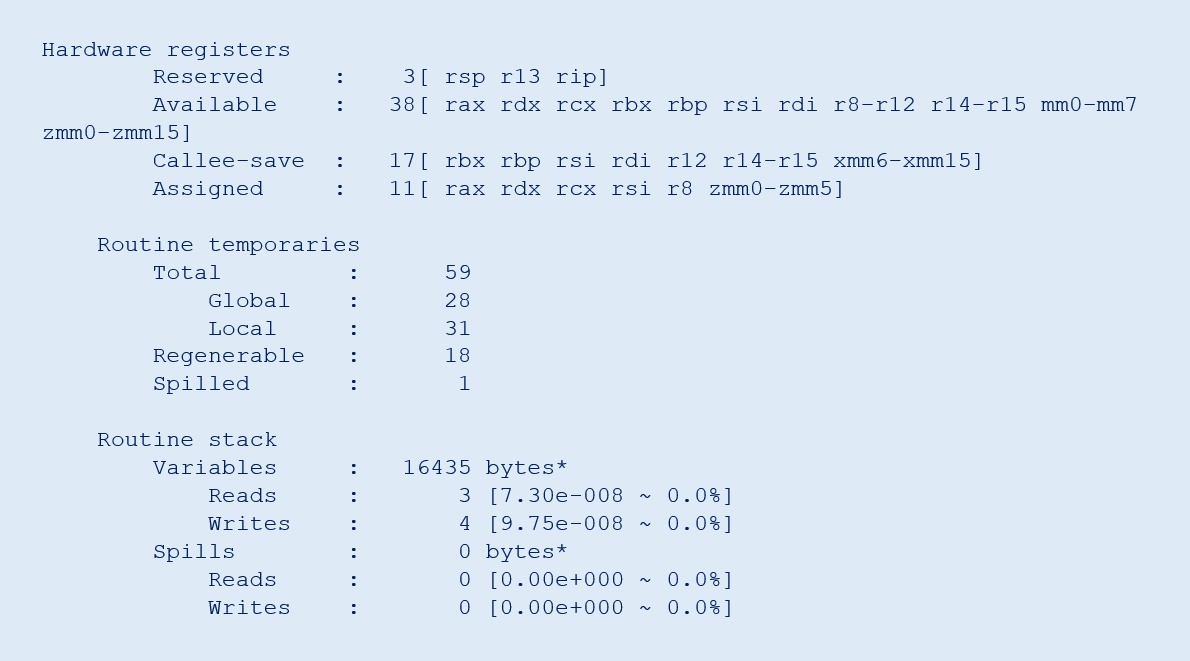
Figure 2. Intel C++ Compiler code-generation report showing register pressure and stack usage
Interprocedural Optimization
The pseudocode shown in Figure 3 was adapted from a Lattice Boltzmann method (LBM) application. Figures 4 and 5 shows the compiler optimization reports with and without IPO. The compilation units lbm_file1.c and lbm_file2.c contain functions func_grids and func2, respectively. func2 invokes func_grids in a time-step loop.
One of the most common optimizations for better compiler code generation and performance is function inlining. However, it can be done only when the callee (function definition) and caller (invocation) are in a single compilation unit. This is not the case for the LBM example in Figure 3. However, the Intel® compiler can do interprocedural optimization (the -ipo and /Qipo compiler options on Linux and Windows, respectively). As shown in Figure 4, the call to func_grids prevents vectorization of the loop in func2. Using IPO gives the compiler an opportunity to vectorize such loops and function calls by inline optimization (Figure 5).

Figure 3. Example code showing the use of IPO compiler optimization

Figure 4. Compiler optimization reports for each file without IPO

Figure 5. Compiler optimization report using IPO showing inlining, vectorization, and dead static function elimination. Note that only one report (ipo_out.optrpt) is generated.
Function Inlining
One of the most common compiler optimizations is to inline a called function within the caller. A function is more likely to be inlined if it is smaller in size. The compiler generally tries to limit the “code bloat” caused by inlining, but you can override the compiler’s conservative tendencies by changing the options listed in Figure 6.

Figure 6. Compiler options and heuristics for inlining
Floating-Point Model and Precision
Scientific users usually want to maintain high precision in their computations. This is typically accomplished by using 64-bit instead of 32-bit floating-point datatypes. However, using lower precision datatypes when appropriate can improve performance. In addition, compiler optimizations that affect numerical reproducibility and consistency are sometimes prevented using the -fp-model precise option (fp:precise on Windows).
The code in Figure 7 computes the square norm of a 2D array. If this code is compiled with the precise floating-point model, the compiler is unable to vectorize the inner loop (Figure 8). A more relaxed floating-point model (the default) allows the compiler to perform more aggressive optimization, as suggested in the report.

Figure 7. A simple two-level reduction loop

Figure 8. A precise floating-point model can limit optimization
OpenMP* and Auto-parallelization
Another speedup opportunity on modern processors is parallelism. The Intel compilers support parallelism when the compiler can determine that it is safe (auto-parallelization) or when the parallelism is expressed using OpenMP (Figure 9). The compiler optimization reports which loops are parallelized when the OpenMP (-qopenmp and /Qopenmp on Linux and Windows, respectively) and auto-parallelization (-parallel and /Qpar on Linux and Windows, respectively) options are used (Figure 10).

Figure 9. Code snippet with OpenMP parallel constructs and potential compiler auto-parallelization

Figure 10. Compiler report showing OpenMP and auto-parallelization
Conclusion
Intel compilers provide a rich set of features, performance optimizations, and support for the latest language standards. You are encouraged to try the latest compiler and experience application performance improvements that are possible by changing a few compiler options. The compiler reports and examples shown in this article and previous articles help to understand what the compiler is doing.
Resources
1. Intel® 64 and IA-32 Architectures Software Developer Manuals
2. Intel C++ Compiler Classic Developer Guide and Reference
3. Consistency of Floating-Point Results Using the Intel Compiler
______
You May Also Like
| Use OpenMP Accelerator Offload for Programming Heterogeneous Architectures Read |
| Run High-Performance Computing (HPC) Applications on CPUs and GPUs with Xe Architecture Using Intel C++ and Intel Fortran Compilers with OpenMP |
| Intel® oneAPI DPC++/C++ Compiler |