Advanced software development tools and their time-to-time upgrades (or better replacements) are essential for developers to build real-world optimized solutions, benefit from the latest available hardware, and compete in the race of software technology. Intel® Software Development Tools is an actively evolving, rich, one-stop collection of software tools, libraries, and frameworks that enable building, deploying, and fine-tuning applications in a wide range of fields, including AI and HPC. Backed by the oneAPI programming framework, the suite enables accelerated, cross-vendor parallel computing across heterogeneous architectures, including CPUs, GPUs, AI PC NPUs, and other accelerators.
At the recently held IXPUG (Intel Extreme Performance Users Group) Annual Conference 2025, Sanjiv Shah from Intel delivered an opening keynote where he discussed how our software developer resources have evolved over the years, and how they prove useful for the key industry leaders and developer communities. This article will give you highlights of the session.
→ The complete keynote recording and presentation slides are available here: The Evolution of Intel Developer Software.
About The Keynote Speaker
Sanjiv Shah is a Vice President (Data Center and AI Group) and a General Manager (Developer Software Engineering) at Intel. For the past 25+ years, he has been an expert contributing to the software developer ecosystem.
Long History of Intel® Developer Software on the Leading Edge of Progress
The long history of Intel software dates back to the 1980s (or even earlier), when we introduced Fortran* and C compilers and debuggers. These were followed by the C++ compiler, scientific libraries like the math kernel library (now called the Intel® oneAPI Math Kernel Library or oneMKL), and the Intel® VTune™ Profiler tool for performance analysis and debugging in the ‘90s.
In the early 2000s, we stepped into the parallelism domain along with some software acquisitions. The results were enabling OpenMP* support for C++ and Fortran compilers, creating the Intel® MPI Library, and more. Considering the limitations of the existing parallel programming models, we introduced the threading building blocks library (today’s Intel® oneAPI Threading Building Blocks or oneTBB). We also came up with an array of CPUs called the Intel® Xeon Phi™ Processors, one of our first accelerators.
At the beginning of the 2010s, we started our efforts to empower AI applications with the introduction of what we have today as Intel® oneAPI Data Analytics Library (oneDAL), Intel® Distribution for Python*, and Intel® oneAPI Collective Communications Library (oneCCL) for deep learning in distributed environments.
While we were launching more GPUs in the market, the urge to have an open programming model supporting a wide range of GPUs and accelerators gave rise to the oneAPI specification backed by the SYCL* framework. We launched our oneAPI implementation, which evolved into the UXL Foundation initiative for open, multiarchitecture, cross-vendor, accelerated parallel computing (learn more in the latter part of this article).
→ Watch the session recording from [00:00:35] to dive deeper into the history of Intel developer software.
Making Our Foundational Technology Stronger!
Beginning at [00:07:25] in the keynote video, Sanjiv discusses the four major fundamental software technology areas that we have been focusing on over the past 5 years:
-
Compilers – We have adopted the LLVM* compiler technology across all the Intel® compilers for industry standards-compliant, faster compilation of applications targeting heterogeneous architectures. We have also added sanitizers to the compilers to detect undesirable code behaviors. (Read further for more details on LLVM compilers and sanitizers)
-
Programming Models – We have added GPU offload support to the OpenMP standard, enhanced the Intel® oneAPI Threading Building Blocks (oneTBB) library, and integrated SYCL with oneAPI libraries for efficient parallel programming on GPUs.
-
Distributed Programming – The Intel MPI Library now supports GPI-initiated communications and libfabrics*. We also continue to enhance oneCCL for distributed computing.
-
Analyzers – Our progress in the analyzers space includes feature enhancements in Intel VTune Profiler and Intel® Advisor tools, which help detect, analyze, and fix performance issues at both hardware and software levels through hotspots analysis, CPU bandwidth utilization, GPU offload analysis, and much more.
Next Gen LLVM*-powered Compilers and Sanitizers
Sanjiv highlights the following advantages that the LLVM technology comes with:
-
Reduced compilation time
-
Improved error diagnostics through enhanced C++ error messaging, optimization reports, and sanitizers
-
OpenMP offload support for GPUs
-
SYCL support for CPUs and GPUs
-
Open standards-based technology with free licensing that encourages community contributions and easy industry adoption
Intel® oneAPI DPC++/C++ Compiler and Intel® Fortran Compiler, leveraging the LLVM technology, can be easily integrated into a wider range of applications (C/C++, Fortran, Java*, OpenCL™, etc.) and perform better than several competitive platforms, as illustrated by the keynote speaker from [00:12:55] in the video.
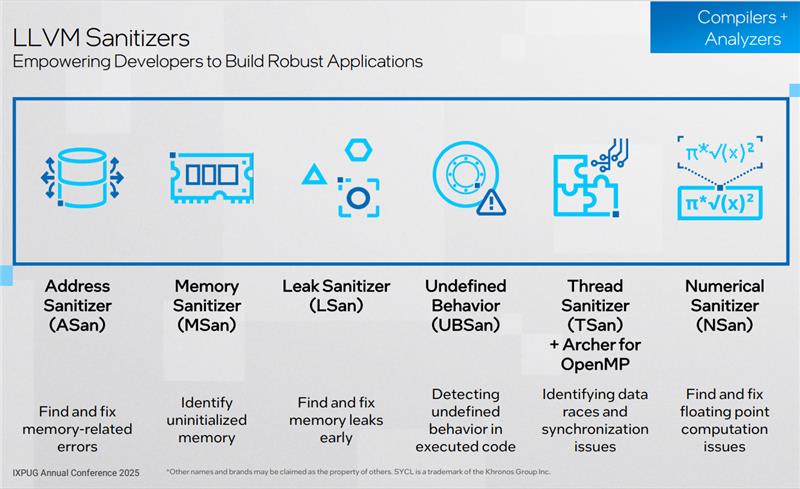
Fig.1: Types of LLVM Sanitizers
Sanitizers extend the functionalities by detecting bugs during the testing phase. We have enabled various LLVM sanitizers for our C/C++ and Fortran compilers. These tools help pinpoint and fix errors like uninitialized memory, memory leaks, data races, and more in CPUs and/or GPUs. Each type of sanitizer detects a specific kind of undesirable code behavior.
→ Refer to the session video from [00:10:35] for more details on our LLVM-based compilers and sanitizers.
→ Learn more about sanitizers: Find Bugs Quickly Using Sanitizers with the Intel oneAPI DPC++/C++ Compiler.
Extended OpenMP* Support for GPUs
We have been actively expanding support for OpenMP offload on GPUs. Since November last year, we have started supporting OpenMP 6.0, which enables advanced features, including interoperability with SYCL, support for accelerator devices, improved loop transformations, and increased control over memory and storage resources. PyTorch Optimizations from Intel leverage OpenMP at the backend, empowering AI workloads on CPUs.
OpenMP also serves as a more flexible and feature-rich framework for adding parallelism to C/C++ and Fortran applications compared to OpenACC*. The Intel® Application Migration Tool enables easy code migration from OpenACC to OpenMP.
→ Check out the OpenACC to OpenMP migration article and related code samples.
→ More details: Intel oneAPI DPC++/C++ Compiler supports OpenMP.
→ Watch another IXPUG session: OpenMP in oneAPI: Empowering Scientific Computing on Intel Platforms, From Laptops to Aurora Exascale.
Open, Accelerated Programming with oneAPI and the UXL Foundation
A huge number of proprietary architectures available in the accelerator space pose a challenge for developers to try and utilize the power of multi-core hardware from diverse vendors, and hence, maximize the application performance. This limitation motivated us to introduce the oneAPI initiative for open software development targeting heterogeneous architectures, including CPUs, GPUs, and other accelerators, free from vendor lock-in.
The success of the oneAPI effort in its initial phase resulted in the formation of the UXL Foundation, a project under the Linux Foundation’s Joint Development Foundation, in 2023. Driven by 30+ key industry players, it aims at establishing an open, multi-architecture, multi-vendor software ecosystem for accelerated parallel computing.
At the foundation of the UXL Foundation lies the open, industry standards-based, community-driven oneAPI specification that helps developers increase application performance, productivity, and portability. Intel has its own implementation of the oneAPI specification with a set of tools (also available ascomprehensive bundles in various oneAPI toolkits).
Code Once, Deploy Anywhere with SYCL* Framework
oneAPI programming paradigm is backed by the Khronos* Group’s SYCL framework based on modern C++ standards. SYCL interoperates with different programming models and enables targeting multi-vendor hardware with a common codebase. Our Intel oneAPI DPC++/C++ Compiler was the very first of its kind to attain SYCL 2020 conformance. What value this brings to developers is that their SYCL code compiled by the Intel compiler is portable and can reliably run across multi-vendor GPUs in the long term.
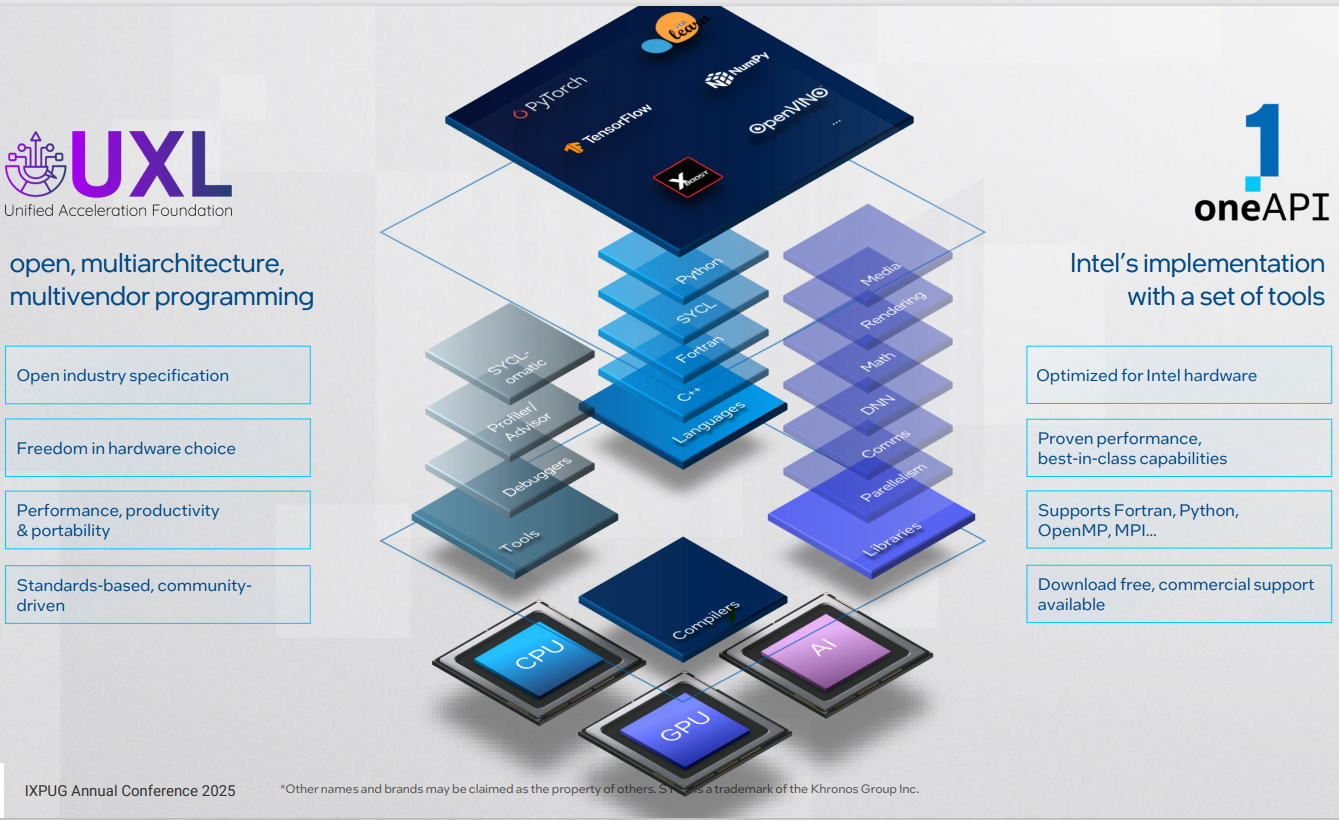
Fig.2: Open-source software development stack powered by SYCL and oneAPI
You can, of course, build a SYCL application from scratch to avail yourselves of the benefits of SYCL. However, if you have CUDA* code, you can easily convert it into C++ with SYCL code using the two oneAPI-powered automated migration tools: the Intel® DPC++ Compatibility Tool and its open-source implementation called the SYCLomatic. These tools can migrate around 90%-95%[a] of your CUDA code in 5 simple steps (learn about the migration workflow here).
→ For more details on our recent contributions to oneAPI and SYCL adoption, watch the ‘Growth of Accelerators’ section of the keynote recording from [00:16:50].
→ Check out our Migrate from CUDA to C++ with SYCL portal and CUDA to SYCL Catalog of Ready-to-Use Applications.
There are 40+ practical SYCL applications (available in the catalog mentioned above) across various domains, including math, health and life sciences, aerodynamics, fluid dynamics, geology, geography, high-energy physics, etc. Some of the key partners and customers of our software developer ecosystem who have been leveraging and/or enabling SYCL include Argonne National Laboratory*, CERN*, C-DAC*, University of Utah*, University of Birmingham*, UC Berkeley*, and many more. Several popular applications and frameworks have been successfully migrated from CUDA to C++ with SYCL, resulting in significant performance improvements. Examples include GROMACS and NAMD for molecular dynamics, the Ginkgo C++ library for sparse linear algebra, and others.
Sanjiv also highlights how Amber* and GROMACS molecular dynamics packages, Ansys* Fluent software for fluid dynamics simulation, and some other commercial rendering applications can be equally executed on Argonne’s Aurora supercomputers and GPUs from different vendors like Intel, NVIDIA*, and AMD*. This proves SYCL's heterogeneity characteristic.
Our Recent Software Enablement Efforts
With significant GPU performance improvements noted with the use of low-precision formats as compared to high-precision ones (see the comparison illustrated from [00:31:25] in the session recording), oneMKL now supports low-precision formats such as int8, float16, and bfloat16 that help enhance low-precision and mixed-precision operations for GEMM, vector math, and other routines. Intel® oneAPI Deep Neural Network (oneDNN) library helps accelerate matrix multiplication for several low-precision data types.
→ Check out the IXPUG talk: Using Low-Precision to Emulate Higher Precision for HPC.
The SYCL Joint Matrix extension available as a part of Intel oneAPI DPC++/C++ Compiler provides a lightweight abstraction for matrix hardware programming. Compared to AI/ML libraries and frameworks such as oneDNN and TensorFlow*, the joint matrix extension offers better custom optimizations and fusion capabilities for tasks like building your neural network. It helps deliver high performance and port common code to multiple targets such as Intel® Advanced Matrix Extensions (Intel® AMX) for CPUs, Intel® X Matrix Extensions (Intel® XMX) for GPUs, NVIDIA Tensor Cores, AMD Matrix Cores, etc.
→ More details in this IXPUG session: Joint Matrix: A Unified SYCL Extension for Matrix Hardware Programming.
CUTLASS is originally NVIDIA’s collection of C++ abstractions for high-performance matrix multiplications (GEMM). Since CUTLASS v3.0, we have enabled the SYCL backend (called the cutlass-sycl project) to leverage the library across multi-vendor GPUs. It has been incorporated in 200+ projects, including major deep learning frameworks such as PyTorch and llama.cpp*.
The SYCL Graph extension, available as part of the Intel oneAPI DPC++/C++ Compiler, helps reduce latency while submitting the same graph kernels to multiple devices. This functionality is supported by several applications, such as GROMACS, llama.cpp, and Kokkos*. It aids in reducing the overhead of kernel submission, especially in AI workloads that usually have a large number of small kernels.
→ Learn more in this IXPUG talk: ‘SYCL Graph: Reducing Kernel Graph Overhead for Intel GPUs’.
→ Watch the keynote recording from [00:31:20] to learn more about our ongoing and upcoming efforts for optimized AI development and accelerated computing.
Have A Seamless Developer Experience with Intel® Software!
Start exploring and experimenting with our oneAPI tools, libraries and framework optimizations for faster AI, HPC, rendering, and more. Download multi-purpose toolkits or stand-alone tools that cater to your needs. Sign up for Intel® Tiber™ AI Cloud, where you can get hands-on experience of our optimized software on the latest accelerated hardware.
Useful Resources
-
Tech.Decoded - blogs, tech articles, case studies, webinars, workshops, and more
[a] An Intel estimate as of September 2024, which is based on measurements from a set of 100 HPC benchmarks, AI applications, and samples, with examples like GROMACS, llama.cpp, and SqueezeLLM. Results may vary.