According to Gartner, Inc., graph processing is one of the top 10 data analytics trends for 2021. It is an emerging application area, as well as a necessary tool for data scientists working with linked datasets (e.g., social, telecommunication, and financial networks; web traffic; and biochemical pathways). Graphs in practical applications tend to be large, and they're getting larger. For example, social networks today can have billions of nodes and edges, so high-performance parallel computing is essential.
To this end, Katana Graph, in collaboration with Intel, has designed a high-performance, easy-to-use graph analytics Python library with (a) highly optimized, parallel implementations of important graph analytics algorithms; (b) a high-level Python interface to write custom parallel algorithms on top of the underlying C++ graph engine; (c) interoperability with pandas, scikit-learn, and Apache Arrow, and tools and libraries in the Intel AI software stack; (d) comprehensive support for extraction, transformation, and loading (ETL) from various formats; and (e) a Metagraph plugin.
This article will cover what's in the library, how to get access to the library, usage examples, and benchmark data to highlight performance.
Graph Analytics Algorithms in the Library
The key algorithms that are commonly used in graph-processing pipelines come prepackaged in the Katana library. The algorithms that are currently available are listed below:
- Breadth-first search: Returns an oriented tree constructed from a breadth-first search starting at a source node
- Single-source shortest path: Computes the shortest paths to all the nodes starting from a source node
- Connected components: Finds the components (i.e., groups of nodes) of the graph that are connected internally, but not connected to other components
- PageRank: Computes the ranking of nodes in the graph based on the structure of incoming links
- Betweenness centrality: Computes the centrality of nodes in the graph based on the number of shortest paths that pass through each node
- Triangle counting: Counts the number of triangles in a graph
- Louvain community detection: Computes the communities of the graph that maximizes the modularity using the Louvain heuristics
- Subgraph extraction: Extracts the induced subgraph of the graph
- Jaccard similarity: Computes the Jaccard coefficient of a given node to every other node in the graph
- Community detection using label propagation: Computes the communities in the graph using a label propagation algorithm
- Local clustering coefficient functions: Measures the degree to which nodes in a graph tend to cluster together
- K-Truss: Finds the maximal induced subgraph of the graph that contains at least three vertices where every edge is incident to at least K - 2 triangles
- K-Core: Finds the maximal subgraph that contains nodes of degree K or more
More algorithms are being added to the library, and it's easy for users to add their own algorithms, as we'll demonstrate below.
Getting the Katana Graph Library
Katana Graph's analytics library is open-source and freely available under the 3-Clause BSD license. It is available on GitHub or easily installed from Anaconda.org:
$ conda install -c katanagraph/label/dev -c conda-forge katana-python
Using the Katana Graph Library
Katana's Python library supports ETL from various formats, such as adjacency matrices, pandas DataFrames, NumPy arrays, edge lists, GraphML, NetworkX, etc. A few examples are shown below:
import numpy as np
import pandas
from katana.local import Graph
from katana.local.import_data import (
from_adjacency_matrix,
from_edge_list_arrays,
from_edge_list_dataframe,
from_edge_list_matrix,
from_graphml)
Input from an Adjacency Matrix
katana_graph = from_adjacency_matrix(
np.array([[0, 1, 0], [0, 0, 2], [3, 0, 0]]))
Input from an Edge List
katana_graph = from_edge_list_arrays(
np.array([0, 1, 10]), np.array([1, 2, 0]),
prop = np.array([1, 2, 3]))
Input from a Pandas DataFrame
katana_graph = from_edge_list_dataframe(
pandas.DataFrame(dict(source=[0, 1, 10],
destination=[1, 2, 0],
prop = [1, 2, 3])))
Input from GraphML
katana_graph = from_graphml(input_file)
Executing a Graph Analytics Algorithm
The following example computes the betweenness centrality of an input graph:
import katana.local
from katana.example_utils import get_input
from katana.property_graph import PropertyGraph
from katana.analytics import betweenness_centrality,
BetweennessCentralityPlan,
BetweennessCentralityStatistics
katana.local.initialize()
property_name = "betweenness_centrality"
betweenness_centrality(katana_graph, property_name, 16,
BetweennessCentralityPlan.outer())
stats = BetweennessCentralityStatistics(g, property_name)
print("Min Centrality:", stats.min_centrality)
print("Max Centrality:", stats.max_centrality)
print("Average Centrality:", stats.average_centrality)
Katana's Python library is interoperable with pandas, scikit-learn, and Apache Arrow.
Along with the prepackaged routines listed previously, data scientists can also write their own graph algorithms using an easy Python interface that exposes Katana Graph's optimized C++ engine1 and its concurrent data structures and parallel loop constructs. The Katana Graph library already contains a breadth-first search implementation, but the following example illustrates how easy it is to implement such algorithms using the API:
def bfs(graph: Graph, source):
"""
Compute the BFS distance to all nodes from source.
The algorithm in bulk-synchronous level by level.
:param graph: The input graph.
:param source: The source node for the traversal.
:return: An array of distances, indexed by node ID.
"""
next_level_number = 0
# The work lists for the current and next levels using a
# Katana concurrent data structure.
curr_level_worklist = InsertBag[np.uint32]()
next_level_worklist = InsertBag[np.uint32]()
# Create and initialize the distance array.
# source is 0, everywhere else is INFINITY
distance = np.empty((len(graph),), dtype=np.uint32)
distance[:] = INFINITY
distance[source] = 0
# Start processing with just the source node.
next_level_worklist.push(source)
# Execute until the worklist is empty.
while not next_level_worklist.empty():
# Swap the current and next work lists
curr_level_worklist, next_level_worklist = next_level_worklist,
curr_level_worklist
# Clear the worklist for the next level.
next_level_worklist.clear()
next_level_number += 1
# Process the current worklist in parallel by applying
# bfs_operator for each element of the worklist.
do_all(
curr_level_worklist,
# The call here binds the initial arguments of bfs_operator.
bfs_operator(graph, next_level_worklist,
next_level_number, distance)
)
return distance
# This function is marked as a Katana operator, meaning that it will
# be compiled to native code and prepared for use with Katana do_all.
@do_all_operator()
def bfs_operator(graph: Graph, next_level_worklist,
next_level_number, distance, node_id):
"""
The operator called for each node in the work list.
The initial four arguments are provided by bfs above.
node_id is taken from the worklist and passed to this
function by do_all.
:param next_level_worklist: The work list to add next nodes to.
:param next_level_number: The level to assign to nodes we find.
:param distance: The distance array to fill with data.
:param node_id: The node we are processing.
:return:
"""
# Iterate over the out edges of our node
for edge_id in graph.edges(node_id):
# Get the destination of the edge
dst = graph.get_edge_dest(edge_id)
# If the destination has not yet been reached, set its level
# and add it to the work list so its out edges can be processed
# in the next level.
if distance[dst] == INFINITY:
distance[dst] = next_level_number
next_level_worklist.push(dst)
# There is a race here, but it's safe. If multiple calls to
# operator add the same destination, they will all set the
# same level. It will create more work because the node will
# be processed more than once in the next level, but it avoids
# atomic operations so it can still be a win in low-degree graphs.
Metagraph Support
Katana Graph's Python analytics library will be available via a Metagraph plugin. Metagraph provides a consistent Python entry point into graph analysis. One can write a graph workflow using a standard API, and then have that dispatch to compatible graph libraries that plug into Metagraph. Now, the open- source graph community will be able to directly use Katana Graph's high-performance applications. The Metagraph plugin comes in an Anaconda package that can be installed and invoked as follows:
$ conda create -n metagraph-test -c conda-forge \
-c katanagraph/label/dev \
-c metagraph metagraph-katana
import metagraph as mg
bfs = mg.algos.traversal.bfs_iter(katana_graph, <start node>)
How Fast Is the Katana Graph Library?
The Katana library has been extensively benchmarked against other graph analytics frameworks and has consistently shown equivalent or better performance for the GAP Benchmark Suite2. Table 1 shows the Katana Graph's performance relative to the GAP reference implementations for various graphs from diverse domains.
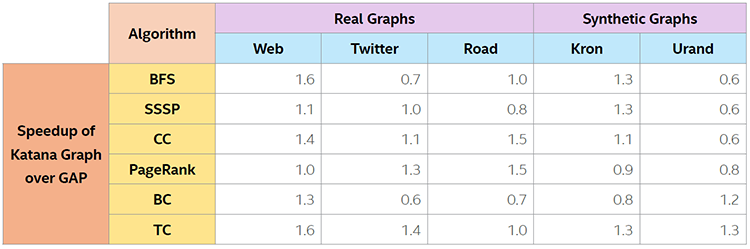
Table 1. Measuring Katana Graph performance using the GAP Benchmark Suite. This data is taken from Azad et al. (2020)2. System: dual-socket 2.0 GHz Intel® Xeon® Platinum 8153 processor (64 logical cores) and 384 GB DDR4 memory. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
The Katana Graph library has also been shown to perform well on extremely large graphs, such as Clueweb123 and WDC124 (at 42 and 128 billion edges, respectively, these are some of the largest publicly available graphs) on recent byte-addressable memory technologies such as Intel® OptaneTM DC persistent memory5, 6 (Figure 1).
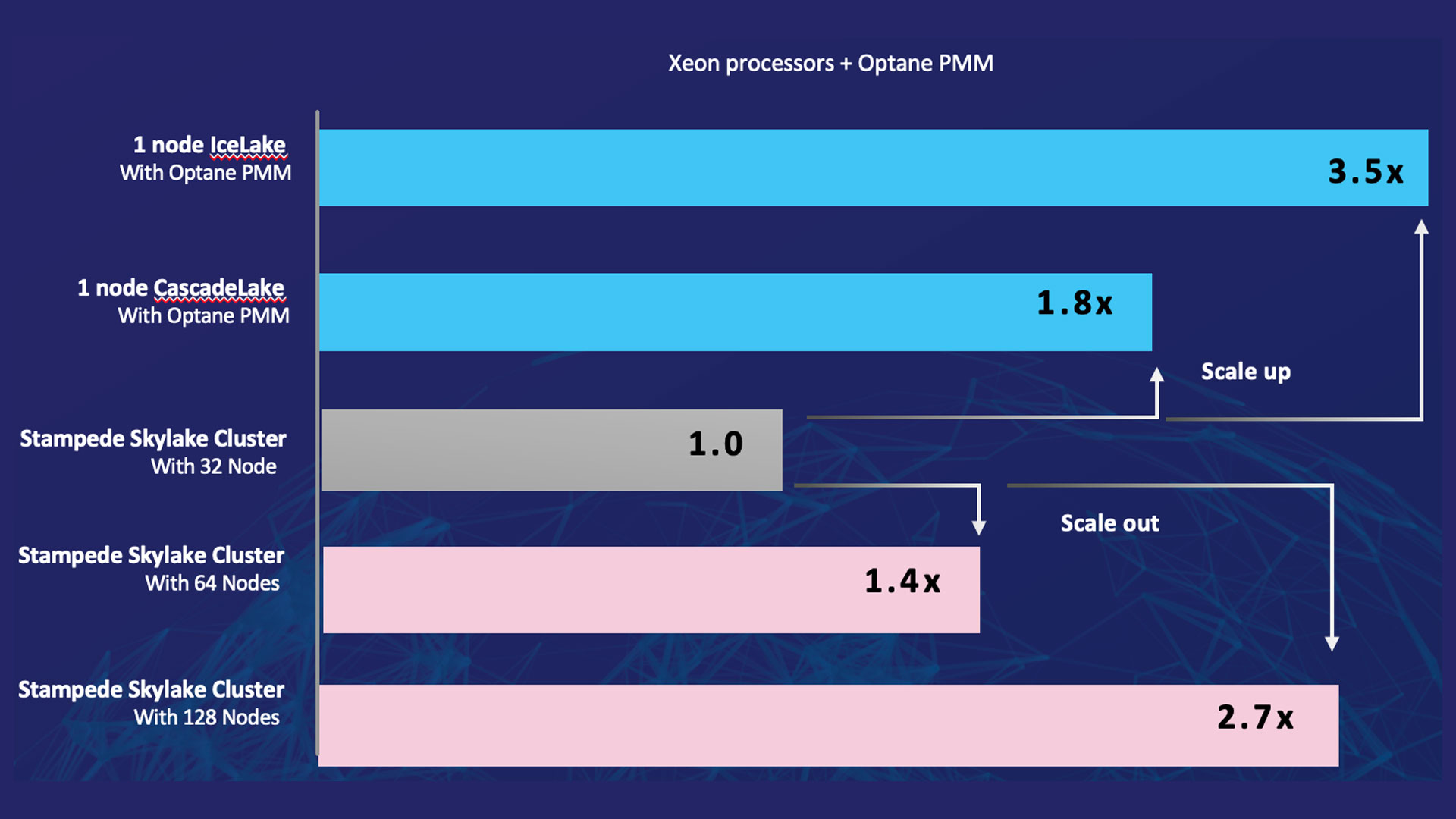
Figure 1. Katana Graph BFS performance on extremely large graphs. It compares the performance of a single Intel Optane memory-based node to clusters with multiple nodes. Each TACC Stampede Skylake cluster node has two 2.1 GHz Intel Xeon Platinum 8160 processors and 192 GB DDR4 memory. The Cascade Lake servers have two 2.2 GHz 2nd Generation Intel Xeon Scalable processors with 6 TB Intel Optane PMM and 384 GB DDR4 DRAM. The Ice Lake servers have two 2.2 GHz Intel Xeon Platinum 8352Y processors with 8 TB Intel Optane PMM and 1 TB DDR4 DRAM. This chart was compiled with data from references [5] and [6]. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Where Can I Learn More?
I hope you're convinced that the Katana Graph library is a versatile, high-performance option for graph analytics. You can learn more about the library, ask questions, post feature requests, etc. at the GitHub site.
References
- Nguyen, D., Lenharth, A., and Pingali, K. (2013). A lightweight infrastructure for graph analytics. Proceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP '13).
- Azad, A. et al. (2020). Evaluation of graph analytics frameworks using the GAP Benchmark Suite, IEEE International Symposium on Workload Characterization (IISWC).
- The ClueWeb12 Dataset
- Web Data Commons – Hyperlink Graphs
- Gill, G., Dathathri, R., Hoang, L., Peri, R., and Pingali, K. (2020) Single machine graph analytics on massive datasets using Intel Optane DC Persistent Memory. Proceedings of the VLDB Endowment, 13(8), 1304– 1318.
- Dathathri, R. et al. (2019). Gluon-Async: A bulk-asynchronous system for distributed and heterogeneous graph analytics. Proceedings of the 28th International Conference on Parallel Architectures and Compilation Techniques (PACT).
Related Content
Watch
Intel® oneAPI AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.