Today, we’re pleased to announce the Deep Learning Reference Stack (DLRS) 9.0 release. Release v9 offers more compute performance with the 3rd Gen Intel® Xeon® Scalable processor, and it integrates DeepSpeech, an automatic speech recognition (ASR) engine. DLRS v9 continues to feature Intel® Advanced Vector Extensions 512 (Intel® AVX-512) with Intel® Deep Learning Boost (Intel® DL Boost). Intel DL Boost accelerates AI training and inference performance.
DLRS v9.0 further improves the ability to quickly prototype and deploy DL workloads, reducing complexity while enabling customization. This release features:
-
TensorFlow* 1.15 and TensorFlow* 2.4.0: An end-to-end open source platform for machine learning (ML). This stack uses open source versions with Intel optimizations.
-
PyTorch* 1.8: An open source machine learning framework that accelerates the path from prototyping to production deployment. This stack uses open source versions with Intel optimizations.
-
PyTorch Lightning: A lightweight wrapper for PyTorch designed to help researchers set up all the boilerplate state-of-the-art training.
-
Transformers: State-of-the-art Natural Language Processing (NLP) for TensorFlow 2.4 and PyTorch.
-
Flair: A framework for state-of-the-art Natural Language Processing using PyTorch
-
OpenVINO™ model server version 2021.2: A solution that delivers improved neural network performance on Intel processors, helping unlock cost-effective, real-time vision applications [1]
-
TensorFlow Serving 2.4: A Deep Learning model serving solution for TensorFlow models.
-
Horovod: A framework for optimized distributed Deep Learning training for TensorFlow and PyTorch.
-
oneAPI Deep Neural Network Library One DNN accelerated backends for TensorFlow, PyTorch and OpenVINO
-
Intel DL Boost Vector Neural Network Instructions (VNNI): Features designed to accelerate deep neural network-based algorithms.
-
Deep Learning Compilers (TVM* 0.6): An end-to-end compiler stack.
-
Seldon Core and KFServing : Integration examples with DLRS for deep learning model serving on a Kubernetes cluster.
-
DeepSpeech : An open-source Speech-To-Text engine, using a model trained by machine learning techniques.
Benefits
In DLRS v9 we continue to incorporate a serving container to our suite of optimized stacks that includes hardware accelerated OpenVINO™ model server, updated to 2021.1 (Figure 1).
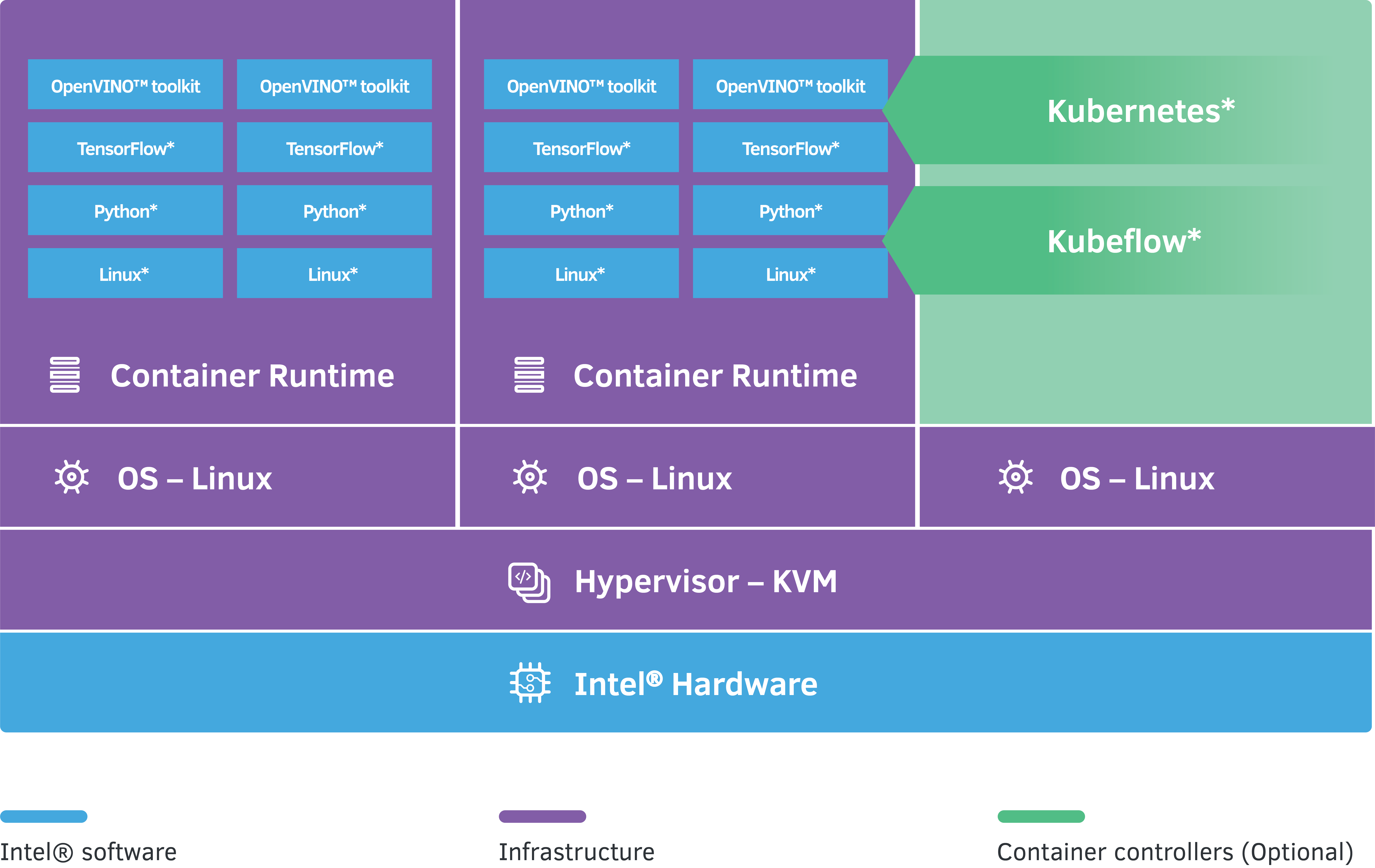
Figure 1.
DLRS v9 continues to use the new Intel® DL Boost Vector Neural Network Instructions (VNNI), which allows the user to accelerate deep learning training to inference operations on 3rd Gen Intel® Xeon® Scalable processors. We have enabled this functionality for both Pytorch and Tensorflow frameworks (Figure 2).
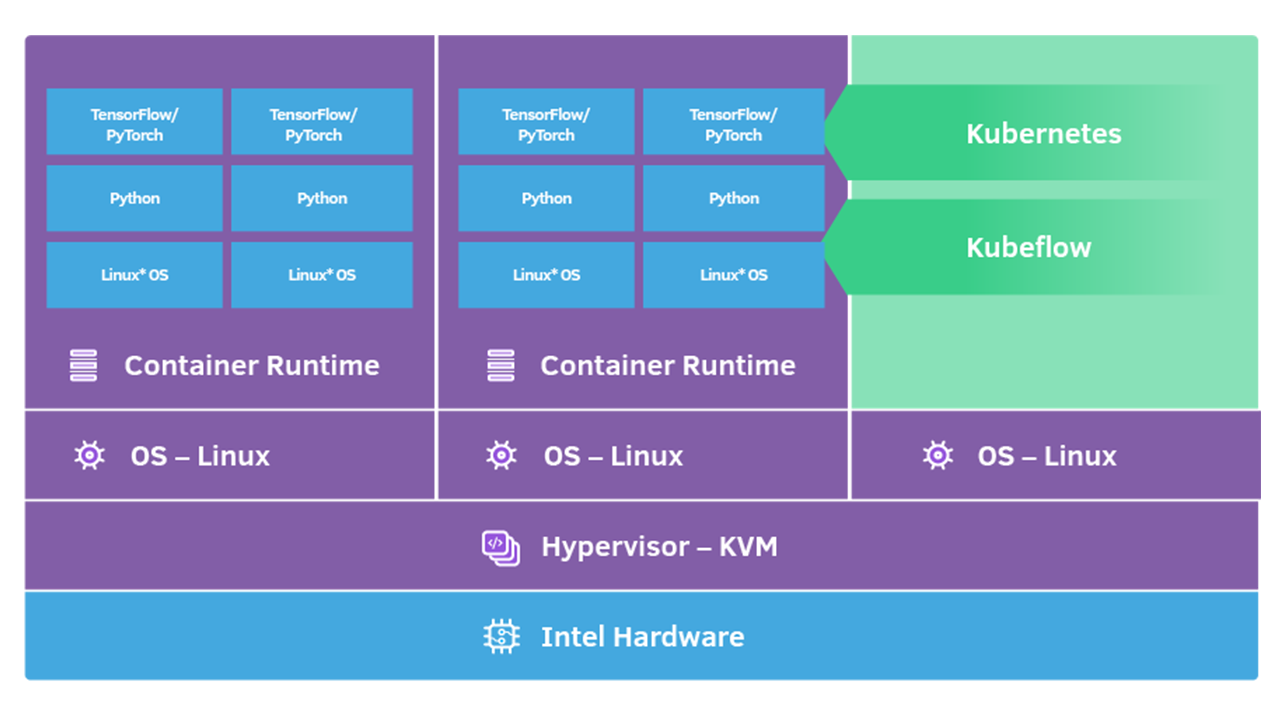
Figure 2.
The 3rd Gen Intel® Xeon® Scalable processors also support accelerated INT8 convolutions with Intel® AVX 512 VNNI [2] instructions for higher levels of inference performance.
Enabling Deep Learning Use Cases
As a platform for building and deploying portable, scalable, machine learning (ML) workflows, Kubeflow Pipelines*makes deployment of DLRS images easy. This enables orchestration of machine learning pipelines while simplifying ML Ops and the management of numerous deep learning use cases and applications. DLRS v9 continues to incorporate Transformers[3] , a state-of-the-art general-purpose library that includes a number of pretrained models for Natural Language Understanding (NLU) and Natural Language Generation (NLG). The library helps to seamlessly move from pre-trained or fine-tuned models to productization.
DLRS v9 still incorporates Natural Language Processing (NLP) libraries to demonstrate that pretrained language models can be used to achieve state-of-the-art results [4] with ease. NLP Libraries can be used for natural language processing, machine translation, and building embedded layers for transfer learning.
In addition to the Docker* deployment model, DLRS is integrated with Function-as-a-Service (FaaS) technologies, which are scalable event-driven compute platforms. One can use frameworks such as Fn [6] and OpenFaaS [7] to dynamically manage and deploy event-driven, independent inference functions. We have created an OpenFaaS template (available already in the OpenFaaS template store) that integrates DLRS capabilities with this popular FaaS project. DLRS v9 uses the latest version of TensorFlow 1.15 and Ubuntu 20.04, but it can be extended to any of the other DLRS flavors.
One can use end-to-end use cases for the Deep Learning Reference Stack to help developers quickly prototype and bring up the stack in their environments. Some end to end use-cases of such deployments are:
-
Galaxies Identification: Demonstrates the use of the Deep Learning Reference Stack to detect and classify galaxies by their morphology using image processing and computer vision algorithms on the Intel® Xeon® processor.
-
Using AI to Help Save Lives: A Data Driven Approach for Intracranial Hemorrhage Detection: AI training pipeline to help detect intracranial hemorrhage (ICH)
-
Github* Issue Classification Use Case: Used to auto-classify and tag issues using the Deep Learning Reference Stack for deep learning workloads
-
Pix2pix: Can be used to perform image to image translation using end-to-end system stacks
-
TF Serving: how the Deep Learning Reference Stack (DLRS) with applied TensorFlow* Serving reduces the complexity of training and serving machine learning models in a production environment.
We’ll continue to unveil additional use cases targeting developer and service provider needs in the coming weeks.
Supported Tools and Frameworks
This release also supports the latest versions of popular developer tools and frameworks:
-
Operating System: Ubuntu* 20.04, and CentOS* 8.0 Linux* distributions.
-
Orchestration: Kubernetes* to manage and orchestrate containerized applications for multi-node clusters with Intel platform awareness.
-
Containers: Docker* Containers and Kata* Containers with Intel® Virtualization Technology (Intel® VT) for enhanced protection.
-
Libraries: oneAPI Deep Neural Network Library (oneDNN), an open-source performance library for deep learning applications. The library includes basic building blocks for neural networks optimized for Intel® Architecture Processors and Intel® Processor Graphics.
-
Runtimes: Python* and C++
-
Deployment: Kubeflow* Seldon and Kubeflow* Pipelines support the deployment of the Deep Learning Reference Stack.
-
User Experience: JupyterLab*, a popular and easy to use web-based editing tool.
Multiple layers of the Deep Learning Reference Stack are performance-tuned for Intel® architecture, offering significant advantages over other stacks, as shown below:
Performance gains for the Deep Learning Reference Stack with TensorFlow:
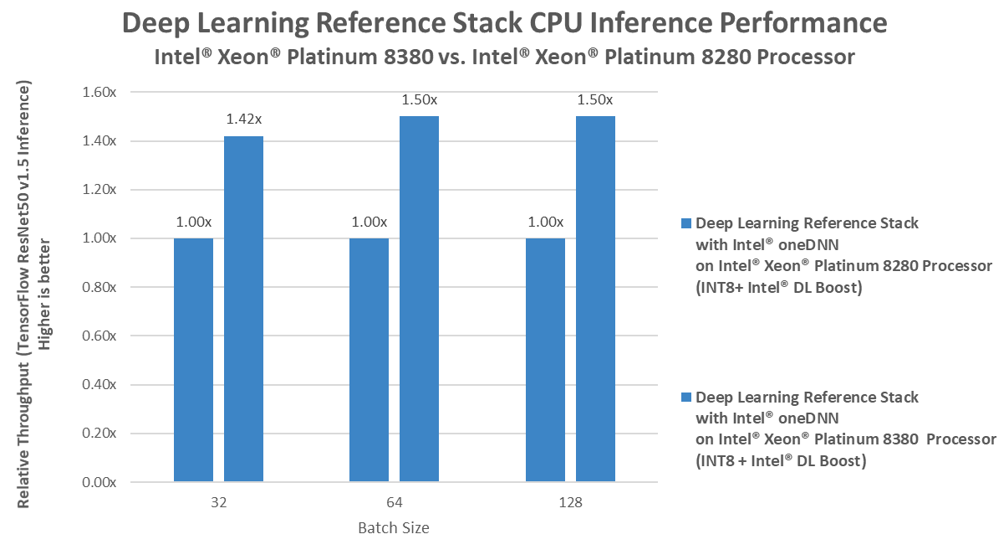
3rd Gen Intel® Xeon® Scalable processor–Tested by Intel as of 03/24/2021. 2 socket Intel® Xeon® Platinum 8380 Processor(2.3GHz, 40 cores), HT On, Turbo On, Total Memory 256 GB (16 slots/ 32GB/ 3200 MHz), BIOS: SE5C6200.86B.0021.D40.2101090208 (ucode: 0x8d055260), Ubuntu 20.04.1 LTS kernel 5.4.0-65-generic, Deep Learning Framework: TensorFlow* v2.4.0, hash 582c8d, ResNet-50 v1.5 , Compiler: gcc v9.3.0,oneDNN version: v1.5.1, BS=32,64,128, Synthetic data, 2 inference instance/2 socket, Datatype: INT8
2nd Gen Intel® Xeon® Scalable processor–Tested by Intel as of 03/24/2021. 2 socket Intel® Xeon® Platinum 8380 Processor(2.3GHz, 40 cores), HT On, Turbo On, Total Memory 256 GB (16 slots/ 32GB/ 3200 MHz), BIOS: SE5C6200.86B.0021.D40.2101090208 (ucode: 0x8d055260), Ubuntu 20.04.1 LTS kernel 5.4.0-65-generic, Deep Learning Framework: TensorFlow* v2.4.0, hash 582c8d, ResNet-50 v1.5, Compiler: gcc v9.3.0,oneDNN version: v1.5.1, BS=32,64,128, Synthetic data, 2 inference instance/2 socket, Datatype: INT8
Performance gains for the Deep Learning Reference Stack with PyTorch:
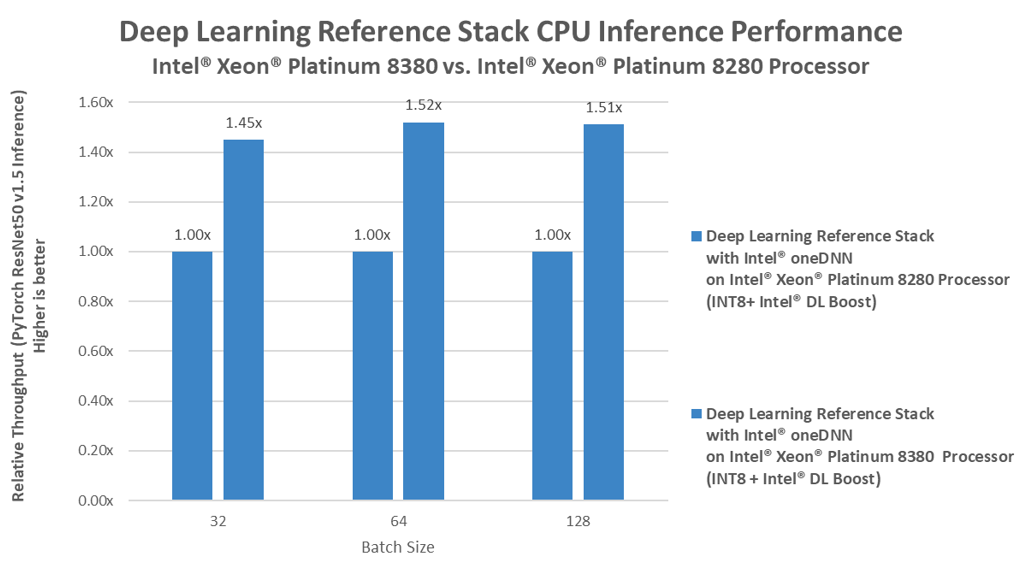
3rd Gen Intel® Xeon® Scalable processor–Tested by Intel as of 03/24/2021. 2 socket Intel® Xeon® Platinum 8380 Processor(2.3GHz, 40 cores), HT On, Turbo On, Total Memory 256 GB (16 slots/ 32GB/ 3200 MHz), BIOS: SE5C6200.86B.0021.D40.2101090208 (ucode: 0xd0001e0), Ubuntu 20.04.1 LTS kernel 5.4.0-65-generic, Deep Learning Framework: TensorFlow* v2.4.0, hash 582c8d, ResNet-50 v1.5, Compiler: gcc v9.3.0,oneDNN version: v1.5.1, BS=32,64,128, Synthetic data, 2 inference instance/2 socket, Datatype: INT8
2nd Gen Intel® Xeon® Scalable processor–Tested by Intel as of 03/24/2021. 2 socket Intel® Xeon® Platinum 8380 Processor(2.3GHz, 40 cores), HT On, Turbo On, Total Memory 256 GB (16 slots/ 32GB/ 3200 MHz), BIOS: SE5C6200.86B.0021.D40.2101090208 (ucode: 0xd0001e0), Ubuntu 20.04.1 LTS kernel 5.4.0-65-generic, Deep Learning Framework: TensorFlow* v2.4.0, hash 582c8d, ResNet-50 v1.5, Compiler: gcc v9.3.0,oneDNN version: v1.5.1, BS=32,64,128, Synthetic data, 2 inference instance/2 socket, Datatype: INT8
Intel is dedicated to ensure popular frameworks and topologies run best on Intel® architecture, giving you a choice in the right solution for your needs. DLRS also drives innovation on our current Intel® Xeon® Scalable processor and Intel® Core™ mobile processor. We plan to continue performance optimizations for coming generations.
Visit the Intel® Developer Zone page to learn more and download the Deep Learning Reference Stack code. Please contribute feedback. As always, we welcome ideas for further enhancements through the stacks mailing list.
[1] Intel® Distribution of OpenVINO™ Toolkit Release Notes
[2] Introduction to Deep Learning Boost
[3] Using Transformers* for Natural Language Processing
[4] Ruder.io
[5] Flair NLP
[6] Pix2Pix on Fn
[7] DLRS template for OpenFaaS
Notices & Disclaimers
For workloads and configurations, visit www.Intel.com/PerformanceIndex. Results may vary.
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. *Other names and brands may be claimed as the property of others.