Introduction
This article showcases how the Deep Learning Reference Stack (DLRS) with applied TensorFlow* Serving reduces the complexity of training and serving machine learning models in a production environment.
Background
Artificial Intelligence (AI) often starts in a research laboratory where machine learning models are designed and trained by data scientists to solve complex problems with the best performance possible. While design and training might appear the ultimate goal, in practical scenarios the goal of building machine learning models is to expose them to consumers in a production environment where they can be used to actively solve real world problems.
Yet data scientists and companies struggle to bridge the gap between research and production deployments. According to “The state of enterprise ML”[1], a report made by Algorithmia[2], most companies take over a month and up to a year to deploy one model and only 28% do so within a month. The same report mentions that only 22% of companies have successfully deployed and maintained a model. Nevertheless, most of the companies surveyed reported investment increases in AI projects from1% to 75%. The research is clear. Building successful AI projects requires establishing effective and efficient processes for designing, building, and deploying models.
Deploying models into production requires an assessment of multiple requirements: frameworks, tools, hardware, modularity and even programming languages. Models cannot be scaled easily because of versioning and reproducibility. While machine learning models require faster iteration than the traditional software development, version-control is critical to retrain and re-evaluate models to improve performance. This difference exposes an important gap between data scientists, machine learning engineers, and DevOps engineers. While the first two provide the data and code, the latter often knows the best processes and methods for deploying a project into production.
TensorFlow Serving to the rescue
“TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments.[...]TensorFlow Serving provides out of the box integration with TensorFlow models, but can be easily extended to serve other types of models,” per TensorFlow [3]. TensorFlow Serving is a tool that can certainly help data scientists, machine learning engineers and DevOps bring their models into production because it solves most of the complexities of model iteration and deployment. TensorFlow Serving allows the user to monitor, version control, batch and extend the resources to other types of models, while continuing to use the TensorFlow API.
TensorFlow Serving is architected around “servables”, which are abstractions of a model, objects that clients use to perform computation (e.g. inference). These servables are created by a “loader”, which standardizes the APIs for loading and unloading a servable and are created by another component called “source”. Sources create loaders for each version of the servable and notify a “manager” about the aspired version. The manager applies the configured version policy to determine the next action to take (e.g., loading a new version of a servable and unloading an older one). The manager also receives client requests and returns a handle for the servable. Figure 1 below shows the TensorFlow serving architecture diagram.
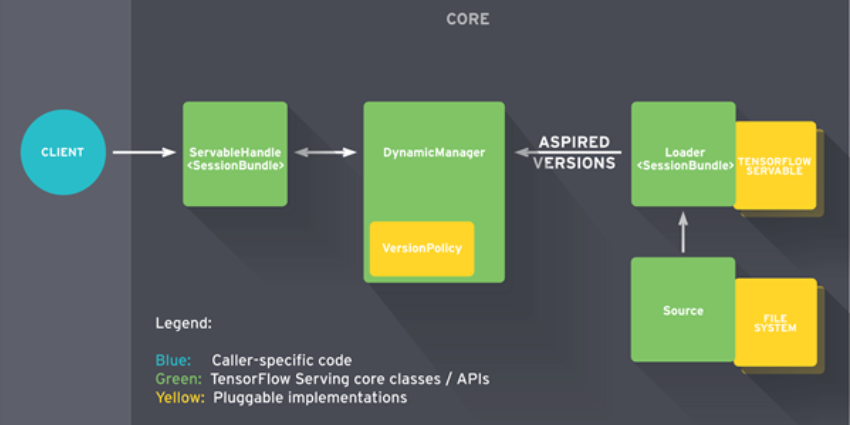
Figure 1. "TensorFlow serving architecture diagram" by TensorFlow is licensed under CC BY 4.0 [4].
Yet another factor comes into play when configuring a TensorFlow training and serving environment. Thankfully, the Deep Learning Reference Stack (DLRS) eliminates the need of creating such an environment from scratch while adding optimizations.
DLRS for training and serving
DLRS is an integrated, highly-performant open source solution optimized for Intel® architecture. DLRS offers a vast range of solutions for inference and training. In the DLRS release v0.7.0 and higher, the stack has integrated TensorFlow Serving as part of its serving container image. Both container images can be found at the oneContainer Portal[5] as dlrs-tensorflow and dlrs-serving. Please refer to the oneContainer Portal for detailed information about these two and all of the container solutions at Intel. These ready-to-use container images allow any user to initiate a machine learning training workload, create a servable object, and serve it while being able to access dedicated features of Intel® architecture. The details of this process are shown in the following section. This white paper’s main goal is to show how the complexities of deploying a machine learning model into production can be reduced using DLRS.
Architecture
The scope of this white paper is to show how to create a servable object and serve it. Thus, data ingestion and analysis and algorithm design will not be included in the pipeline; though keep in mind, these are important steps and must be considered in any real scenario. This section shows the process of training a model and saving it as a servable object using DLRS, configuration of the model server, and serving it using TensorFlow Serving. For steps and code, please refer to the System Stacks use cases repository[6].The following diagram shows the process of serving a machine learning model.

Figure 2. Machine learning pipeline showing required stages for serving a trained model.
Software
-
DLRS v0.7.0 with TensorFlow 2.4 and Ubuntu* 20.04 (sysstacks/dlrs-tensorflow2-ubuntu:v0.7.0)
-
DLRS v0.7.0 with TensorFlow Serving 2.3.0 and Ubuntu 18.04 (sysstacks/dlrs-serving-ubuntu:v0.7.0)
-
Prometheus 2.23
-
Docker* 18 or above
Preparing the model
To load a trained model into TensorFlow Serving, it has to be saved in TensorFlow’s SavedModel format[7]. SavedModel contains a complete TensorFlow program, including weights and computation, and it does not require the original model building code to run. Saving in this format will create a protobuf file in a well-defined directory hierarchy which will include the model version number. This will be useful in the future in version-control tasks.
Creating a SavedModel using TensorFlow Keras API is done by saving the model after training:
# Assuming import tensorflow as tf
# and the model variable points to the trained model
MODEL_DIR = “/workspace”
version = 1
export_path = os.path.join(MODEL_DIR, str(version))
tf.keras.models.save_model(
model,
export_path,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None
)
Training in DLRS
For the sake of simplicity, the training algorithm won’t be shown in this section. The important thing to notice is that besides saving the model, no significant changes have to be made on the traditional training algorithm and script, in fact, up to this point everything should be done as usual.
Running a training script in DLRS is fairly simple:
# Assuming ${PWD} contains a training script
# For development purposes, a volume will be mounted so that resources
# are available for both the host and the container
# In production environments, an entrypoint is a better option
$ docker run --rm -ti -v ${PWD}/:/workspace sysstacks/dlrs-tensorflow2-ubuntu:v0.7.0
# Inside the container
# The training script will train and save the model inside /workspace
# which will also be saved in the host machine
root@fae3be7635aa:/workspace# python train.py
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 2us/step
…
Epoch 1/5
1210/1875 [==================>...........] - ETA: 46s - loss: 0.7991 - accuracy: 0.7250
…
As expected, the trained model is saved inside /workspace/1/ directory and also in the host, the number denotes the version of the model and inside it the following can be found:
root@fae3be7635aa:/workspace/1# ls
total 84
drwxr-xr-x 2 root root 4096 Jan 7 23:15 assets
-rw-r--r-- 1 root root 74086 Jan 7 23:15 saved_model.pb
drwxr-xr-x 2 root root 4096 Jan 7 23:15 variables
Serving in DLRS
Once saved, the model can be loaded into a model server. dlrs-serving provides the environment for running a model server with TensorFlow Serving. In this section, dlrs-serving will be used as the parent image for creating a microservice for model serving.
First, the Dockerfile:
$ cat Dockerfile.serving
FROM sysstacks/dlrs-serving-ubuntu:v0.7.0
COPY ./serving_entrypoint.sh /usr/bin/serving_entrypoint.sh
# Expose port for REST API
EXPOSE 8501
# Set default values for model path
ENV MODEL_DIR=/models
RUN mkdir ${MODEL_DIR}
ENTRYPOINT ["/usr/bin/serving_entrypoint.sh"]
As shown before, this container image requires an entrypoint. In this example, the entrypoint is the TensorFlow Serving package running. Looking at the serving_entrypoint.sh file shows that the binary is running with predefined flags.
#! /usr/bin/env bash
tensorflow_model_server --rest_api_port=8501 \
--model_name=${MODEL_NAME} --model_base_path=${MODEL_DIR}/ \
"$@"
Running a model server in DLRS is fairly simple. After building the previous Dockerfile:
# This will mount the directory where the SavedModel is,
# expose 8501 port for REST API requests
# Assuming the image was tagged as model-server:0.1
$ docker run --rm -ti -v ${PWD}/:/models/ -p 8501:8501 -e MODEL_NAME=my_model model-server:0.1
The server is up and running, ready to receive requests from clients.
2020-12-04 17:49:01.230807: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: my_model version: 1}
[evhttp_server.cc : 238] NET_LOG: Entering the event loop ...
2020-12-04 17:49:01.313477: I tensorflow_serving/model_servers/server.cc:387] Exporting HTTP/REST API at:localhost:8501 ...
Advanced configuration
Up to this point, we haven’t really shown production environment capabilities. TensorFlow Serving provides a model server ready for production. It is a powerful tool that can be configured using configuration files that are read and interpreted in runtime to influence the behavior of the server.
Serving multiple models and versions
TensorFlow Serving is capable of serving multiple models and versions of the same model. This allows users to do simple A/B testing and have one model type per server. Here’s an example of a configuration file that allows for serving multiple models:
$ cat models.config
model_config_list {
config {
name: 'model_a'
base_path: '/models/model_a/'
}
config {
name: 'model_b'
base_path: '/models/model_b/'
}
}
To enable this configuration file, one can edit the entrypoint script adding the --model_config_file flag as follows:
#! /usr/bin/env bash
tensorflow_model_server --port=8500 --rest_api_port=8501 \
--model_name=${MODEL_NAME} --model_base_path=${MODEL_DIR}/ \
--model_config_file=/models/models.config
"$@"
Model versioning and label assignment is helpful for simple A/B testing and for directing clients to “stable” or “experimental” versions of the served model. TensorFlow Serving allows users to redirect traffic to any of the versions specified in the configuration file.
...
model_version_policy {
specific {
versions: 1
versions: 2
}
}
version_labels {
key: 'stable'
value: 1
}
version_labels {
key: 'experimental'
value: 2
}
...
Monitoring
TensorFlow Serving provides a way of monitoring the server using the --monitoring_config_file flag and specifying a monitor configuration file. This configuration allows users to read metrics from the server, such as the number of times the model was attempted to load, number of requests, among many others. TensorFlow Serving collects all metrics that are captured by Serving as well as core TensorFlow. To enable server monitoring, a Prometheus server that pulls metrics from the model server is required.
The configuration file for this looks as follows:
prometheus_config {
enable: true,
path: "/monitoring/prometheus/metrics"
}
As with previous examples, the monitoring_config_file flag has to be added to the entrypoint script.
A flag for everything
TensorFlow Serving is a flexible and highly capable tool, which can be configured for a wide range of applications. There is a flag for everything running, including more complex configurations like batch serving and automatic model and configuration updates. TensorFlow Serving abstraction capabilities allow users to easily and quickly adapt the tool to the many applications they might have, it is ready to use and is already integrated in dlrs-serving, which makes it a great tool for production environments.
Production-ready solutions
Machine learning is quickly becoming an important tool for solving complex problems. As it matures from research to applied business solutions, it faces many challenges, like scalability, deployment, and which tools and methods to use. One of the ways of solving this problem is to leverage the practices of other disciplines such as DevOps and combine these with frameworks that already aim at making it easier for everyone to bring their projects to a production level.
The System Stacks team is dedicated to integrating cutting edge technologies into its solutions. dlrs-serving and dlrs-tensorflow provide users with ready-to-use container images capable of doing training and serve models, which include production-ready frameworks such as TensorFlow and TensorFlow Serving. These solutions allow multi-disciplinary teams to abstract the complexities associated with setting up tools for development and production environments. In the years to come, these solutions will be critical for closing the gap between research and practice.
References
[1] https://info.algorithmia.com/hubfs/2019/Whitepapers/The-State-of-Enterprise-ML-2020/Algorithmia_2020_State_of_Enterprise_ML.pdf
[2] https://algorithmia.com/
[3] https://www.tensorflow.org/tfx/guide/serving
[4] https://www.tensorflow.org/tfx/serving/architecture#life_of_a_servable
[5] https://software.intel.com/content/www/us/en/develop/tools/containers.html
[6] https://github.com/intel/stacks-usecase/model-serving/tfserving
[7] https://www.tensorflow.org/guide/saved_model
Notices and Disclaimers
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.