| File(s) | Download |
| License | 3-Clause BSD License |
| Optimized for... | |
| Operating System: | Linux* |
| Hardware: | Third generation Intel® Xeon® Scalable processor |
| Software: (Programming Language, tool, IDE, Framework) | C++ Compiler version 19, Intel® Parallel Studio XE 2019 |
| Prerequisites: | Familiarity with C++ |
This code example shows how to use the new Intel® Advanced Vector Extensions 512 (Intel® AVX-512) with Intel® Deep Learning Boost (Intel® DL Boost) in third generation Intel Xeon Scalable processors. Intel AVX-512 with Intel DL Boost now introduces new instructions that use the bfloat16 (Brain Floating Point) format and can improve the performance of deep learning training tasks.
The example demonstrates testing the new instructions using intrinsic functions.
Intel® DL Boost: AVX-512_BF16 Extension
bfloat16 (BF16) is a new floating-point format that can accelerate machine learning (deep learning training, in particular) algorithms.
Third generation Intel Xeon Scalable processors include a new Intel AVX-512 extension called AVX-512_BF16 (as part of Intel DL Boost) which is designed to accelerate AI operations using the BF16 format.
The AVX-512_BF16 feature includes an instruction (VDPBF16PS) to compute dot product of BF16 pairs and accumulate to single precision (FP32), as well as instructions (VCVTNE2PS2BF16, VCVTNEPS2BF16) to convert packed single precision data (FP32) to packed BF16 data.
Find a detailed description of the AVX-512_BF16 instructions in the Intel® Architecture Instruction Set Extensions and Future Features Programming Reference.
Why BF16?
Figure 1 shows how two 16-bit floating-point formats (FP16 and BF16) compare to the FP32 format. FP16 format has 5 bits of exponent and 10 bits of mantissa, while BF16 has 8 bits of exponent and 7 bits of mantissa. Compared to FP32, we can see that, while reducing the precision (only 7 bits mantissa), BF16 retains a range that is similar to FP32, which makes it appropriate for deep learning training (For more information about bfloat16 and why it is better suited to support deep learning tasks, see publication Leveraging the bfloat16 Artificial Intelligence Datatype For Higher-Precision Computations).
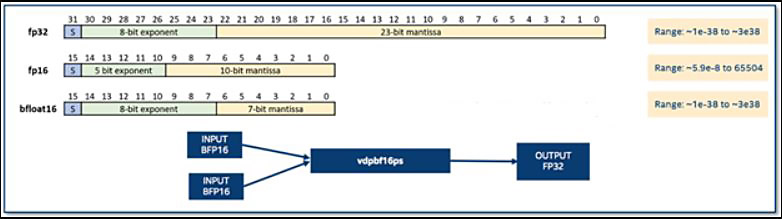
Figure 1. Comparison between different floating-point formats. The new instruction vdpbf16ps performs dot product of BF16 pairs and accumulates result to single precision (FP32). (Image credit to David Mulnix).
Code Sample Walkthrough
This code sample uses Intel AVX-512 intrinsics to illustrate use of the BF16 instructions.
First, we include the prototypes for Intel AVX-512 intrinsics in the immintrin.h header file:
#include <immintrin.h>
Next we can declare memory and register variables. The Intel AVX-512 intrinsic functions use C data types as operands representing the 512-bit registers used in the operations. The __m512 data type can hold 16 FP32 values, while the __m512bh data type can hold 32 BF16 values:
int main() {
float op1_f32[16];
float op2_f32[16];
float op3_f32[16];
float res_f32[16];
float res_comp_f32[16];
// register variables
__m512 v1_f32;
__m512 v2_f32;
__m512 v3_f32;
__m512bh v1_f16;
__m512bh v2_f16;
__m512 vr_f32;
Next we initialize the float arrays. As this code sample illustrates dot product operations, we choose the square root of 2.0 as an operand, so the result of multiplying the operands on different precisions becomes apparent.
// Choose some sample values for arrays
float v = sqrt(2);
for (int i = 0; i < 16; i++)
{
op1_f32[i] = v;
op2_f32[i] = v;
res_f32[i] = 1.0;
// Compute result of dot product operation using float32 (for comparison with bf16)
res_comp_f32[i] = 2.0 * op1_f32[i] * op2_f32[i] + res_f32[i];
}
In the initialization loop shown above, we also perform the dot-product operation using regular FP32 instructions, to later compare with the result of the same operation using BF16 instructions.
Once the arrays in memory are initialized, data can be loaded into the registers using the _mm512_loadu_ps function (data does not need to be aligned on any particular boundary; otherwise, if data is aligned on a 64-byte boundary, the _mm512_load_ps function can be used instead):
// Load 16 float32 values into registers
// (data does not need to be aligned on any particular boundary)
v1_f32 =_mm512_loadu_ps(op1_f32);
v2_f32 =_mm512_loadu_ps(op2_f32);
vr_f32 =_mm512_loadu_ps(res_f32);
(…)
Next step is to convert FP32 data in registers to BF16 format. As described in the introduction, the VCVTNE2PS2BF16 instruction converts two packed FP32 data to one packed BF16 data, which holds twice the number of values. The Intel C/C++ compiler intrinsic equivalent to the above instruction is:
__m512bh _mm512_cvtne2ps_pbh (__m512, __m512)
(see the Intel® Architecture Instruction Set Extensions and Future Features Programming Reference for more information). In this code sample, we initialize two registers with identical BF16 data (just for the purpose of easy interpretation of the results):
// Convert two float32 registers (16 values each) to one BF16 register #1 (32 values)
v1_f16 = _mm512_cvtne2ps_pbh(v1_f32, v2_f32);
// Convert two float32 registers (16 values each) to one BF16 register #2 (32 values)
v2_f16 = _mm512_cvtne2ps_pbh(v1_f32, v2_f32);
Now we can use the VDPBF16PS instruction to perform the dot product operation. The Intel C/C++ compiler intrinsic equivalent to this instruction is:
__m512 _mm512_dpbf16_ps(__m512, __m512bh, __m512bh)
Notice that the intrinsics function above takes, besides the two registers with BF16, another parameter of type __m512 which is of type FP32, which is used to accumulate to the result of the dot product of two BF16 pairs. The following expression illustrates this operation for 2 pairs of BF16 values and one FP32 value:
VR32[1] = V116[1] x V216[1] + V116[2] x V216[2] + V332[1]
In this case, to simplify, we re-write the FP32 input with the packed FP32 results (although it is not required to do so):
// FMA: Performs dot product of BF16 registers #1 and #2.
// Accumulate result into one float32 output register
vr_f32 = _mm512_dpbf16_ps(vr_f32, v1_f16, v2_f16);
The final step is to copy the result data from register into memory:
// Copy output register to memory
// (memory address does not need to be aligned on any particular boundary)
_mm512_storeu_ps((void *) res_f32, vr_f32);
We compile the code sample and run the executable to display the results:
icpc testBF16.cpp -o testBF16
./testBF16
INPUT TO BF16 INSTRUCTION:
Two float32 vectors, each containing values:
1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421 1.41421
One float32 vector (input/output vector), containing values:
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
RESULTS OF DOT PRODUCT USING BF16 INSTRUCTION:
4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915 4.99915
RESULTS OF DOT PRODUCT USING FLOAT32 INSTRUCTIONS :
5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5
Notice in the results above the loss of precision when using the BF16 instruction compared to the result when using the regular FP32 instructions. Notice also that the BF16 result is the result of the dot product operation performed on two registers containing 32 values each, compared to 16 values each when using the regular FP32 instructions.
For More Information
Find detailed descriptions of Intel AVX-512 intrinsics in the Intel® Intrinsics Guide. A detailed description of the BF16 format and instruction can be found in the white paper BFLOAT16 – Hardware Numerics Definition