The vast proliferation and adoption of AI over the past decade has started to drive a shift in AI compute demand from training to inference. For the large number of novel AI models that we created, there is an increased emphasis to use them aross diverse environments ranging from the edge to the cloud.
AI inference refers to the process of using a trained neural network model to make a prediction. Conversely, AI training refers to the creation of the said model or machine learning algorithm using a training dataset. Inference and training, along with data engineering, are the key stages of a typical AI workflow. The workloads associated with the various stages of this workflow are diverse. No single processor–whether a CPU, GPU, or FPGA–nor AI accelerator works best for your entire pipeline.
Let us delve deeper into AI inference and its applications, the role of software optimization, and how CPUs and particularly Intel® CPUs with built-in AI acceleration deliver optimal AI inference performance, while looking at a few interesting use case examples.
Not only has my work in AI involved applications in a number of meaningful fields ranging from healthcare to social good, but I have also been able to apply AI to one of my biggest passions—art. I really enjoy combining my hobbies, such as painting and embroidery, with AI. An example of this is where I was able to use the neural style transfer technique to blend my artwork into the style of famous painters, photos of my friends and pets, or even an Intel microprocessor. We just might have an engaging, hands-on neural style transfer demo for you at the end of the article. Let’s get started.
AI Inference as a Part of the End-to-End AI Workflow
AI, at its essence, converts raw data into information and actionable insights through three stages: data engineering, AI training, and AI inference/deployment. Intel provides a heterogeneous portfolio of AI-optimized hardware combined with a comprehensive suite of AI tools and framework optimizations to accelerate every stage of the end-to-end AI workflow.
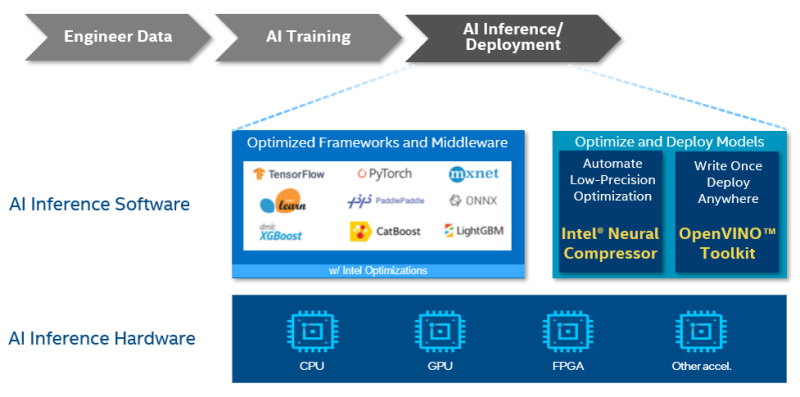
Figure 1. Inference as a part of the end-to-end AI workflow
With the amount of focus that has traditionally been paid to training in model-centric AI over the years and the more recent focus on data engineering and data-centric AI, inference can seem to be more of an afterthought. However, applying what is learned during the training phase to deliver answers to new problems, whether on the cloud or at the edge, is where the value of AI is derived.
Edge inferencing continues to explode across smart surveillance, autonomous machines, and various real-time IoT applications while cloud inferencing already has vast use across fraud detection, personalized recommendations, demand forecasting, and other applications that are not as time-critical and might need greater data processing.
Challenges with Deploying AI Inference
Deploying a trained model for inference can seem trivial. This is far from true as the trained model is not directly used for inference but rather modified, optimized, and simplified based on where it is being deployed. Optimizations depend on performance and efficiency requirements along with the compute, memory, and latency considerations.
The diversity of data and the scale of AI models continues to grow with the proliferation of AI applications across domains and use cases, including vision, speech, recommender systems, and time-series applications. Trained models can be large and complex with hundreds of layers and billions or even trillions of parameters. The inference use case, however, might require that the model still have low latency (for example, automotive applications) or run in a power-constrained environment (for example, battery-operated robots). This necessitates the simplification of the trained models even at a slight cost to prediction accuracy.
A couple of popular methods for optimizing a trained model without significant accuracy losses are pruning and quantization. Pruning refers to eliminating the least significant model weights that have minimal contribution to the final results across a wide array of inputs. Conversely, quantization involves reducing the numerical precision of the weights, for example, from a 32-bit float to an 8-bit integer.
Intel AI hardware architectures and AI software tools provide you with everything you need to optimize your AI inference workflow.
Accelerate AI Inference: Hardware
The different stages of the AI workflow typically have different memory, compute, and latency requirements. Data engineering has the highest memory requirements so that large datasets can fully fit into systems for efficient preprocessing, considerably shortening the time required to sort, filter, label, and transform your data.
Training is usually the most computationally intense stage of the workflow and typically requires several hours or more to complete, depending on the size of the dataset.
However, inference has the most stringent latency requirement, often requiring results in milliseconds or less. A point of note here is that while the computing intensity of inference is much lower than that of training, inference is often done on a much larger dataset leading to the use of greater total computing resources for inference vs training.
From hardware that excels at training large, unstructured data sets to low-power silicon for optimized on-device inference, Intel AI supports cloud service providers, enterprises, and research teams with a portfolio of versatile, purpose-built, customizable, and application-specific AI hardware that turns AI into reality.
The Role of CPUs in AI
The Intel® Xeon® Scalable processor, with its unparalleled general-purpose programmability, is the most widely used server platform from the cloud to the edge for AI. CPUs are extensively used in the data engineering and inference stages while training uses a more diverse mix of GPUs and AI accelerators in addition to CPUs. GPUs have their place in the AI toolbox, and Intel is developing a GPU family based on our Xe architecture.
CPUs, however, remain optimal for most machine learning inference needs, and we are also leading the industry in driving technology innovation to accelerate inference performance on the industry’s most widely used CPUs. We continue expanding the built-in acceleration capabilities of Intel® Deep Learning Boost (Intel® DL Boost) in Intel Xeon Scalable processors. Based on Intel® Advanced Vector Extensions 512 (Intel® AVX-512), the Vector Neural Network Instructions (VNNI) in Intel DL Boost deliver a significant performance improvement by combining three instructions into one, thereby maximizing the use of compute resources, using the cache better, and avoiding potential bandwidth bottlenecks.
Most recently, we announced Intel® Advanced Matrix Extensions (Intel® AMX), an extensible accelerator architecture in Intel Xeon Scalable processors, which enables higher machine learning compute performance for training and inference by providing a matrix math overlay for the Intel AVX-512 vector math units.
Accelerate AI Inference: Software
Intel complements the AI acceleration capabilities built into our hardware architectures with optimized versions of popular AI frameworks and a rich suite of libraries and tools for end-to-end AI development, including for inference.
All major AI frameworks for deep learning (such as TensorFlow*, PyTorch*, Apache MXNet*, and PaddlePaddle*) and classical machine learning (such as scikit-learn* and XGBoost) have been optimized by using oneAPI libraries (oneAPI is a standards-based, unified programming model that delivers a common developer experience across diverse hardware architectures) that provide optimal performance across Intel CPUs and XPUs.
These Intel software optimizations, referred to as software AI accelerators, help deliver orders of magnitude performance gains over stock implementations of the same frameworks. As a framework user, you can reap all performance and productivity benefits through drop-in acceleration without the need to learn new APIs or low-level foundational libraries. Along with developing Intel-optimized distributions for leading AI frameworks, Intel also upstreams our optimizations into the main versions of these frameworks, helping deliver maximum performance and productivity to your inference applications when using default versions of these frameworks.
Deep neural networks (DNNs) show state-of-the-art accuracy for a wide range of computation tasks but still face challenges during inference deployment due to their high computational complexity. A potential alleviating solution is low-precision optimization. With hardware acceleration support, low-precision inference can compute more operations per second, reduce the memory access pressure, and better utilize the cache to deliver higher throughput and lower latency.
Intel® Neural Compressor
The Intel® Neural Compressor tool aims to help practitioners easily and quickly deploy low-precision inference solutions on many of the popular deep learning frameworks including TensorFlow, PyTorch, MXNet, and ONNX* (Open Neural Network Exchange) runtime. Unified APIs are provided for neural network compression technologies such as low-precision quantization, sparsity, pruning, and knowledge distillation. It implements the unified low-precision inference APIs with mixed precision, easy extensibility, and automatic accuracy-driven tuning while being optimized for performance, model size, and memory footprint.
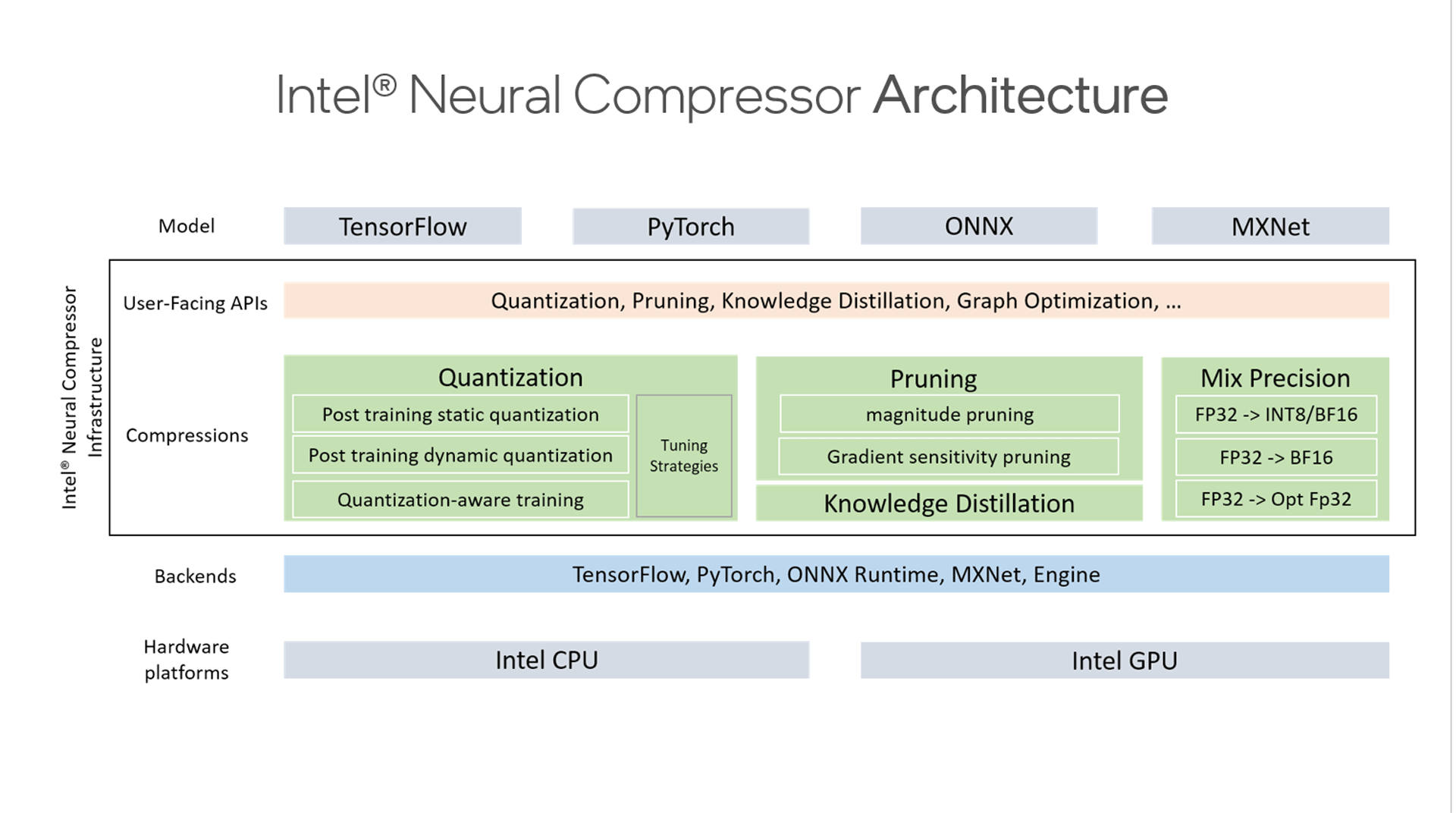
Figure 2. Intel Neural Compressor infrastructure
Transformers are deep learning models that are increasingly used for natural language processing (NLP). The Alibaba Cloud* end-to-end machine learning Platform for AI (PAI) uses Intel-optimized PyTorch transformers for real-world processing tasks for their millions of users.
Low latency and high throughput are keys to a Transformer model’s success, and 8-bit low precision is a promising technique to meet such requirements. Intel DL Boost offers powerful capabilities for 8-bit low-precision inference on AI workloads. With the support of Intel® Neural Compressor (previously called the Intel® Low Precision Optimization Tool), we can optimize 8-bit inference performance while significantly reducing accuracy loss. You can read more about the partnership with Alibaba Cloud and how Intel’s latest CPUs and the Intel Neural Compressor tool helped bring up to a 3x performance boost on the Alibaba Cloud PAI blade inference toolkit.
Intel Neural Compressor is also an integral part of the Optimum machine learning optimization toolkit from HuggingFace* that aims to enable maximum efficiency and production performance to run Transformer models. The Intel Neural Compressor makes models faster with minimal impact on accuracy, taking advantage of post-training quantization, quantization-aware training, and dynamic quantization. It also helps make them smaller with minimal impact on accuracy, with easy-to-use configurations to remove model weights. To read more about quantizing the BERT model for Intel® Xeon® CPUs, see Introducing Optimum.
This compressor is available as part of AI Tools, which provides high-performance APIs and Python* packages to accelerate end-to-end machine learning and data-science pipelines, or as a stand-alone component.
Intel® Distribution of OpenVINO™ Toolkit
The Intel® Distribution of OpenVINO™ toolkit enables practitioners to optimize, tune, and run comprehensive AI inference using an included model optimizer and runtime and development tools. It supports many of the popular AI frameworks, including TensorFlow, ONNX, PyTorch, and Keras*. The toolkit also allows for the deployment of applications across combinations of accelerators and environments, including CPUs, GPUs, and VPUs, and from the edge to the cloud.
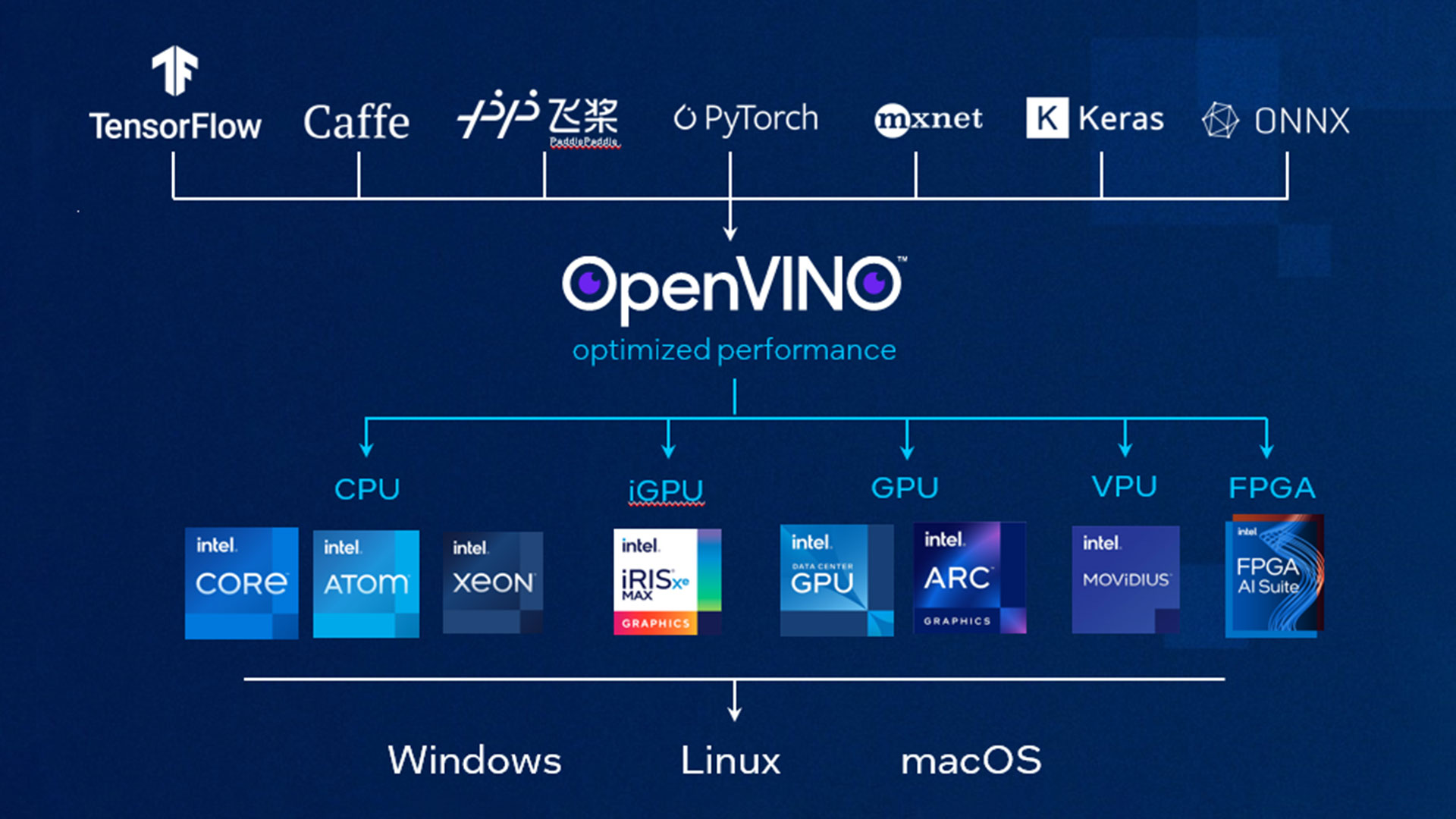
Figure 3. Intel Distribution of OpenVINO toolkit
Developers can explore over 350 pretrained models that are optimized and hosted on the Open Model Zoo repository, including popular models such as YOLO* and MobileNet-SSD for object detection that are optimized with the post-training optimization tool. The performance is benchmarked. Also included are several state-of-the-art models for pose estimation, action recognition, text spotting, pedestrian tracking, and scene and object segmentation that can be easily downloaded for immediate use.
To try it, developers can use OpenVINO™ notebooks that install OpenVINO toolkit locally for rapid prototyping and validating their workloads. You can get started with just your laptop and get a real-time performance boost from our optimized models in fewer than 15 minutes.
AI Inference Application Demo: Neural Style Transfer
Hopefully our discussion today has helped you get a better sense of the Inference stage of the AI workflow, its importance and applications, and how it can be accelerated through both AI-optimized hardware architectures and software tools. Something that has always helped me crystallize concepts is using them in hands-on applications. As mentioned earlier, I love AI and I love to paint. I want to leave you with a quick demo on neural style transfer where I use Intel CPUs and Intel-optimized TensorFlow to transform my paintings into different styles ranging from Van Gogh’s Starry Night to a design of an Intel chip and many more.
![]()
Figure 4. Neural style transfer
Neural style transfer is an AI optimization technique that combines your original image with the artistic style of a reference image. Here is a link to all the files, including code and images, that you will need to run your own neural style transfer experiment along with a short video that walks you through all of the steps.