How to Offload Compute-Intensive Code to Intel® GPUs
Rama Malladi, graphics performance modeling engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Intel® Processor Graphics Architecture is an Intel® technology that provides graphics, compute, media, and display capabilities for many of Intel’s system-on-a-chip (SoC) products. The Intel Processor Graphics Architecture is informally known as “Gen,” shorthand for generation. Each release of the architecture has a corresponding version indicated after the word “Gen.” For example, the latest release of Intel Processor Graphics Architecture is Gen11. Over the years, they have evolved to offer excellent graphics (3D rendering and media performance) and general-purpose compute capabilities with up to 1 TFLOPS (trillion floating-point operations per second) of performance.
In this article, we explore the general-purpose compute capabilities of the Intel Processor Graphics Gen9 and Gen11 architectures and how to program them using Data Parallel C++ (DPC++) in the Intel® oneAPI Base Toolkit. Specifically, we look at a case study that shows programming and performance aspects of the two Gen architectures using DPC++.
Intel® Processor Graphics: Architecture Overview by Gen
Intel® Processor Graphics is a power-efficient, high-performance graphics and media accelerator integrated on-die with the Intel® CPU. The integrated GPU shares the last-level cache (LLC) with the CPU, which permits fine-grained, coherent data sharing at low latency and high bandwidth. Figure 1 shows the SoC with Gen11 graphics. The on-die integration enables much lower power consumption than a discrete graphics card.
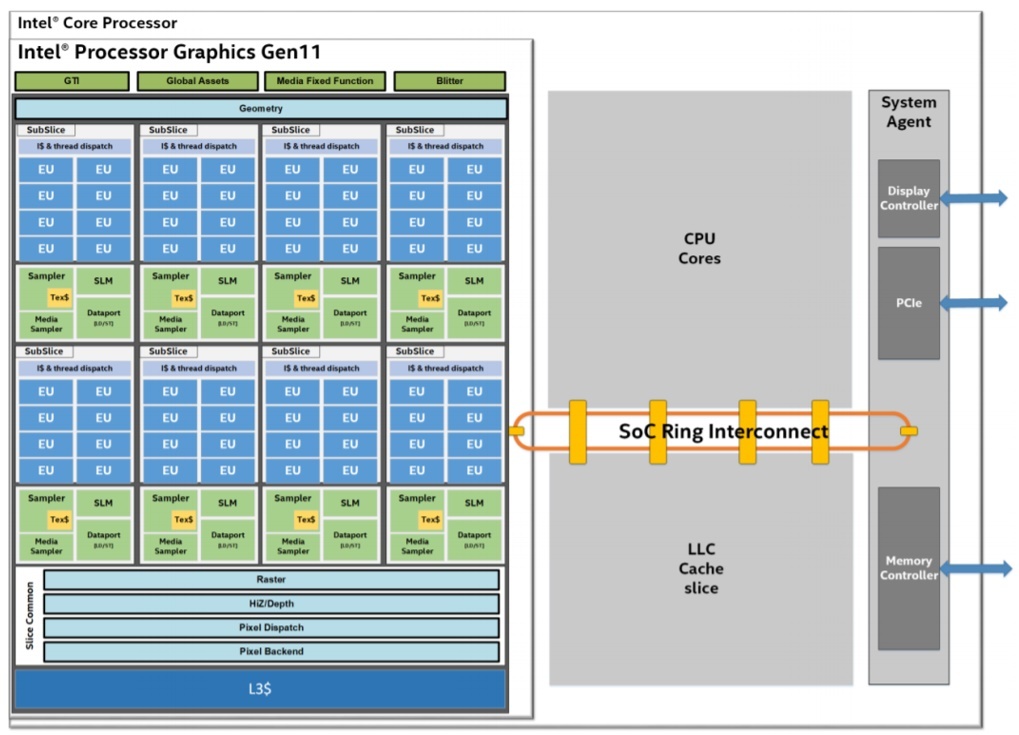
Figure 1. Intel Processor Graphics Gen11 SoC (part of the larger CPU SoC)
Figure 2 shows the architecture block diagram of a Gen9 GPU. The GPU contains many execution units (EUs), each capable of doing single instruction, multiple data (SIMD) computations. A collection of eight EUs would be a subslice. Each subslice has:
- An instruction cache
- L1/L2 sampler caches
- Memory load/store unit ports
These subslices are aggregated to form a slice, which consists of a shared L3 cache (coherent with the CPU) and a banked shared local memory (SLM). An Intel integrated GPU might have one or more such slices. In such a configuration, the L3 is connected to multiple slices via an interconnect fabric.
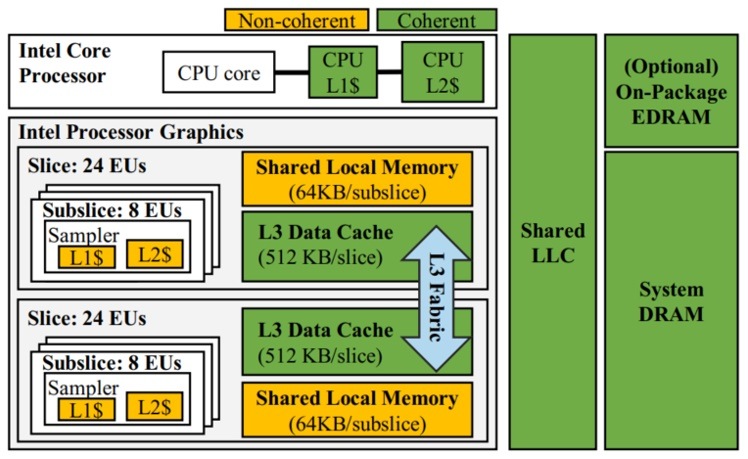
Figure 2. Gen9 GPU Architecture
Figure 3 shows some details of the EU in the Gen9 architecture. The EU supports multithreading with up to seven threads per EU, with each thread having 128 SIMD-8 32-bit registers. An EU can issue up to four instructions per cycle. (Learn more about architecture details and benchmarking of Intel GPUs here.) For example, the peak theoretical GFLOPS for the hardware can be calculated as (EUs)*(SIMD units/EU)*(FLOPS per cycle/SIMD unit)*(Freq GHz).
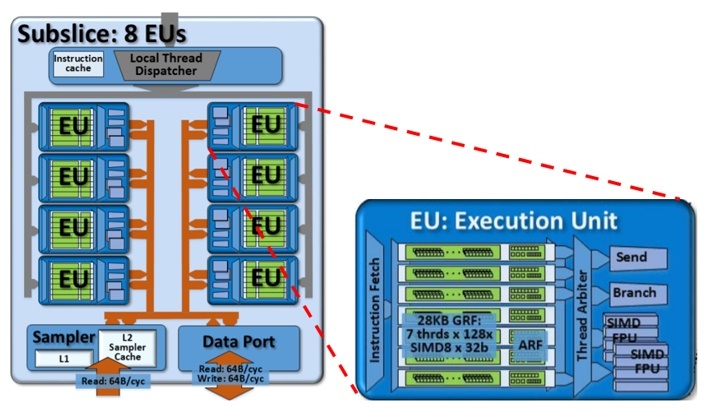
Figure 3. Subslice and EU architecture details
When you’re programming a device such as a GPU, getting the best performance requires language constructs that map well to the hardware features available. Several APIs are available, but let’s take a closer look at oneAPI.
oneAPI and DPC++
oneAPI is an open, free, and standards-based programming model that provides portability and performance across accelerators and generations of hardware. oneAPI includes DPC++, the core programming language for code reuse across various hardware targets. You can find more details in my previous article, Heterogeneous Programming Using oneAPI (The Parallel Universe, Issue 39). DPC++ includes:
- A unified shared memory (USM) feature for easy host-device memory management
- OpenCL™-style NDRange subgroups to aid vectorization
- Support for generic/function pointers
- And many other features
This article presents a case study that converts a CUDA* code to DPC++.
Case Study: Compute Kernel Execution on Intel Processor Graphics
Let’s look at the Hogbom Clean imaging algorithm, widely used in processing radio astronomy images. This imaging algorithm has two hot spots:
- Find Peak
- SubtractPSF
For brevity, we’ll focus on the performance aspects of Find Peak. The original implementation was in C++, OpenMP*, CUDA, and OpenCL. The host CPU offloads the CUDA and OpenCL kernels onto the GPU when available. (CUDA is a proprietary approach to offload computations to only NVidia GPUs.) Figures 4 and 5 show snippets of the host and device code, respectively.

Figure 4. Find Peak host code: C++, CUDA

Figure 5. Find Peak device code: CUDA
We can manually replace the CUDA code with DPC++, or we can use the DPC++ Compatibility Tool (DPCT). DPCT assists in migrating CUDA programs to DPC++ (Figures 6 and 7). It just requires the Intel oneAPI Base Toolkit and the NVIDIA CUDA header. Invoking the DPCT tool to migrate an example.cu file is as simple as:

For migrating applications with many CUDA files, we can use the DPCT options –in-root to set the location of program sources and –out-root for writing the DPCT migrated code. If the application uses make or cmake, it’s recommended that migration be done using intercept-build. This creates a compilation database file (.json file) with the compiler invocations (the input file names for both the host C++ code and the device CUDA code and the associated compiler options).

Specifically, for migrating Hogbom Clean CUDA code to DPC++, we can either invoke the DPCT tool on the HogbomCuda.cu file, which has the CUDA kernels, or use intercept-build. By default, the migrated code gets the file name extension dp.cpp.
Let’s review the migrated DPC++ code (Figures 6 through 9) and compare with the original CUDA code (Figures 4 and 5).


Figure 6. Find Peak DPC++ host code migrated using DPCT

Figure 7. Comparison of CUDA host code versus migrated DPC++ host code

Figure 8. Find Peak DPC++ device DPCT migrated code

Figure 9. Comparison of Find Peak CUDA kernel versus migrated DPC++ device kernel
Some key aspects of a DPC++ code include the invocation of device code using SYCL queues, a lambda function handler for executing the device code, and, optionally, a parallel_for construct for multithreaded execution. The migrated DPC++ code here uses the unified shared memory (USM) programming model and allocates memory on the device for data being read/written by the device kernels. Since this is a device allocation, explicit data copy needs to be done from host to device and vice versa. We can also allocate the memory as shared and it can be accessed and updated by both the host and the device. Not shown here is non-USM code, in which data transfers are done using SYCL buffers and accessors.
The DPCT-migrated code determines the current device and creates a queue for that device (calls to get_current_device() and get_default_queue()). To offload DPC++ code to the GPU, we need to create a queue with the parameter sycl::gpu_selector. The data to be processed should be made available on the device and to the kernel that executes on the GPU. The dimensions and size of the data being copied into and out of the GPU are specified by sycl::range, sycl::nd_range. When using DPCT, each source line in the CUDA code is migrated to equivalent DPC++ code. For the Find Peak device kernel code (d_findPeak), the DPC++ code generated (from CUDA code) is nearly a one-to-one equivalent migration. Hence, DPCT is a very powerful tool for quick porting and prototyping. The migrated DPC++ code comparison versus CUDA code is shown Figures 7 and 9.
Having migrated the code to DPC++ using DPCT, our next task is to check correctness and efficiency. In some cases, the DPCT tool may replace preprocessor directive variables with their values. We may need a manual fix to undo this replacement. We may also get compilation errors with the migrated code that indicates a fix (for example, replacing CUDA threadId.x with an equivalent nd_range accessor). The Hogbom Clean application code has a correctness checker that helped us validate the results produced by the migrated DPC++ code. The correctness check was done by comparing results from the DPC++ code execution on the GPU and a baseline C++ implementation on the host CPU.
Now we can determine the efficiency of the migrated DPC++ code on a GPU by analyzing its utilization (EU occupancy, use of caches, SP or DP FLOPS) and data transfer between host and device. Some of the parameters that have an impact on GPU utilization are the workgroup sizes and range dimensions. In the Hogbom Clean application, for Find Peak, these are nBlocks and findPeakWidth.
To illustrate the performance impact and tuning opportunity, Figure 10 shows a performance profile collected using nBlocks values set to 24 and 4. The findPeakWidth was set to 256. The profile was collected with Intel® VTune™ Profiler, which supports GPU profiling. Tuning is more explicitly required when using DPCT because the parameters that are efficient for an NVidia GPU using CUDA may not be the most efficient for an Intel GPU executing DPC++ code. Table 1 shows the stats collected on Gen9 (48 EUs).
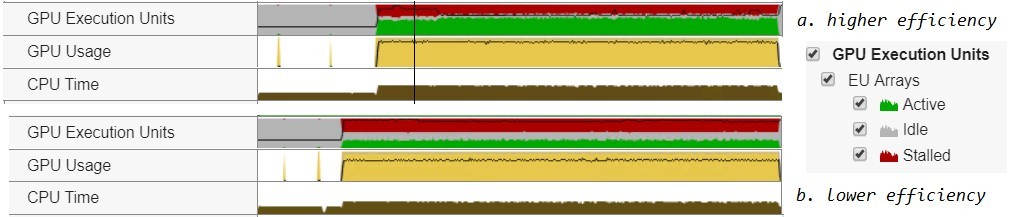
Figure 10. Hogbom Clean profile on Gen9 for two values of nBlocks = (a) 24 and (b) 4
Table 1. Performance metrics on Gen9 GPU for the Find Peak hotspot
| Function | Global Size | Local Size | Execution Time (Sec.) |
Instances | % GPU Array | FPU Util. % |
L3 Shader BW GB/Sec. |
||
|---|---|---|---|---|---|---|---|---|---|
| d_find Peak |
6,144 | 256 | A:3.61 | 1,001 | Archived | Stalled | Idle | 8.6 | 19.5 |
| 36.5 | 48.8 | 14.7 | |||||||
| 1,024 | 256 | B:8.65 | 1,001 | 13.1 | 52.5 | 34.4 | 1.7 | 8.3 | |
In addition to GPU utilization and efficiency optimizations, the data transfer between host and device should also be tuned. The Hogbom Clean application has multiple calls to Find Peak, and SubtractPSF kernels and the data used by these kernels can be resident on the device. Thus, they don’t require reallocation and/or copy from host to device, or vice versa. (We’ll discuss some of these optimizations related to data transfers and USM in future articles.)
Writing Better Algorithms
Understanding the Intel Processor Graphics Architecture and DPC++ features can help you write better algorithms and portable implementations. In this article, we reviewed some details of the architecture and explored a case study using DPC++ constructs and DPCT. It’s important to tune the kernel parameters to get best performance on Intel GPUs, especially when using DPCT. We recommend trying the Intel® DevCloud to develop, test, and run applications on the latest Intel® hardware and software.
______
You May Also Like
Intel® oneAPI Base ToolkitGet started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.Get It Now See All Tools |