Part 2: Order When Kernels Run Using the oneAPI Programming Framework
Ben Ashbaugh, James Brodman, Michael Kinsner; Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
In Part 1 of our Data Parallel C++ (DPC++) Data Management blog, we looked at data movement and control when targeting cross-architecture systems that include hardware accelerators (such as in the oneAPI programming model). We introduced Unified Shared Memory (USM) and buffers that can help programmers achieve their portability and performance goals with DPC++ (the oneAPI cross-architecture language). In this blog, we detail how the different runs of DPC++ kernels are ordered relative to each other.
If you missed our first blog and need a primer on DPC++, read Dive into DPC++ for an inside look at the language and its kernel-based approach.
Order the Kernel Runs–Just Like Everyday Life
In DPC++, the order of how kernels run is important because kernels may run concurrently on one or multiple hardware accelerators, and the kernel code runs asynchronously from the application host code. Without properly ordering these runs, one kernel may start operating on data while another kernel is still using it, leading to data corruption and hard-to-find bugs—experiences that are best avoided.
Kernels are asynchronous tasks submitted to a queue for running on a device, and must often run in a specific order—just like tasks in everyday life. For example, if you are hungry for dinner, you may first need to go to a grocery store to buy ingredients (task A) and then prepare a dish (task B). When an ordering requirement exists between two tasks, we say that a dependence exists between them. In our example, since you can't prepare a dish until after buying ingredients, there is a dependence between these two tasks.
For kernels, the data that a kernel is operating on (reading from or writing to) usually drives the dependencies. For example, for any data that a kernel reads from to do, its work needs to be produced and available on the device before the kernel can run. These data dependences mean that synchronization and data transfers are required before running most kernels. The data transfer tasks may be explicit programmer-specified copy operations or implicit data movements performed by the DPC++ runtime.
Visualize all of your program device tasks and the dependences between them as a directed acyclic graph (DAG). The nodes in the graph are the tasks to run on a device and the edges are the dependences between tasks.
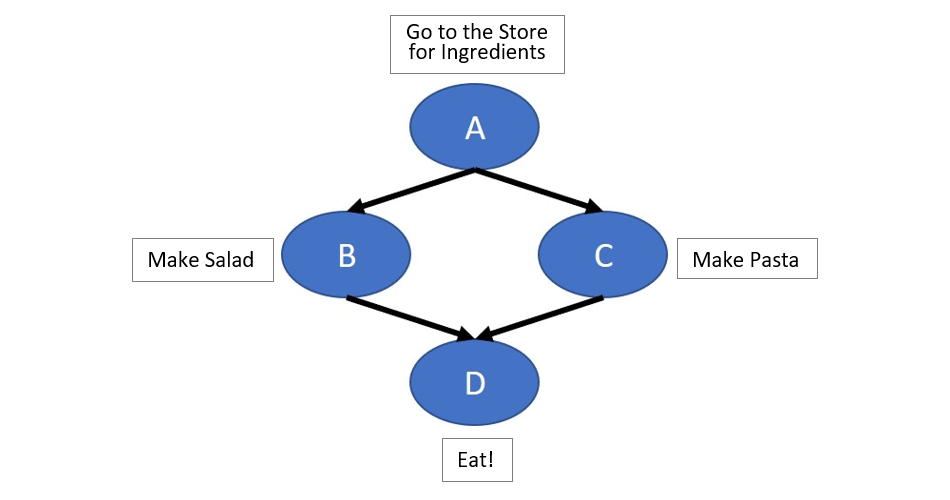
Figure 1. Simple task graph
In Figure 1, task A (Go to the Store for Ingredients) must run before tasks B (Make Salad), and C (Make Pasta). Likewise, B and C must run before task D (Eat!). Because tasks B and C are independent, they do not have a dependence between them. This means the runtime is free to run them in any order, or even in parallel, as long as task A has finished running.
Tasks may have dependences with just a subset of other tasks. When two subsets of tasks are independent, if we only specify the dependences that matter for correctness, the runtime has maximum freedom to optimize the running order.
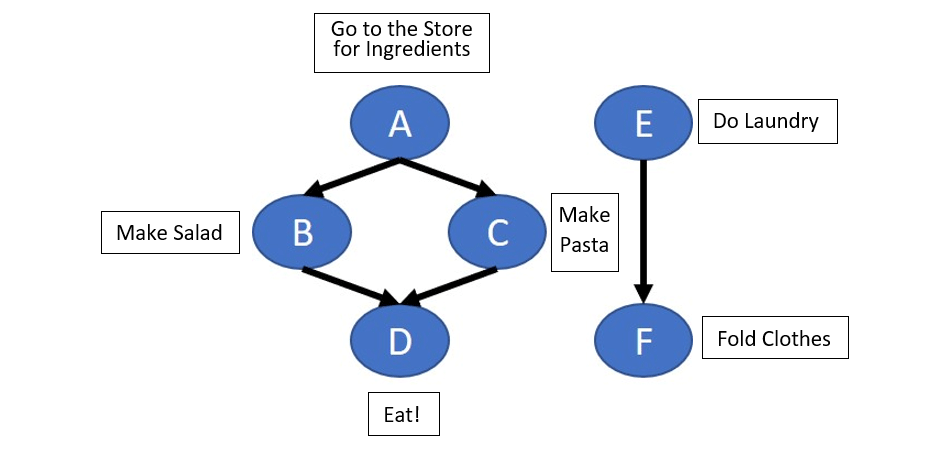
Figure 2. Task graph with disjoint dependences
In Figure 2 we add a few household chores to our evening, in the form of tasks E (Do Laundry) and F (Fold Clothes). Task E must run before F, but tasks E and F have no dependences with A, B, C, and D. If all of these tasks are submitted to a queue for running, there are many valid execution orderings. For example:
- The tasks could be run in order from A to F.
- Running tasks E and F could be interleaved within tasks A to D if, for example, you want to take a break and do laundry after shopping.
- In cases with no dependences between tasks—such as for tasks B, C, and E—you could recruit a roommate or family member and run the tasks in parallel.
There are two ways to model running tasks in a queue:
- Strictly in the order of submission: Implicit dependencies between tasks constrain the order of running (not necessarily based on the data accessed by a task).
- Running tasks in any order: Dependences must be described explicitly—typically based on the data a task accessed.
In-Order Queues

Figure 3. Use of ordered_queue
The simplest option in DPC++ is to submit tasks to an in-order queue object, as seen in Figure 3, where each task waits for the previous tasks to complete before starting. While in-order queues are intuitive and a good fit for many algorithms, the disadvantage is that tasks in an in-order queue never run in parallel, even when no true dependences are between them. Running tasks in parallel can help improve the performance of some algorithms, so out-of-order queues are the most commonly used in real applications.
Out-of-Order Queues
The other option in DPC++ is to submit tasks to a queue object that is an out-of-order queue. This means that tasks may run in any order so long as any dependences between tasks are satisfied. The dependences between tasks must be described explicitly.
Dependences are described via a command group that includes the task and its dependences. Command groups are typically written as C++ lambdas to keep the code brief and are passed as arguments to the submit() method of a queue object. Broadly speaking, the dependences may be represented as:
- Data dependences related to the task in the command group, defined using accessor objects; or
- Running dependences on other tasks in the graph, represented by event objects.
Dependences with Events
The event mechanism explicitly adds dependences between two tasks in a graph by making one task depend on the completion of another, where an event object represents completion. It is most relevant for tasks that operate on USM allocations, which are referenced through pointers instead of accessors. To explicitly add a dependence between tasks, use the depends_on() method that accepts either a single event or a vector of events. The depends_on() method informs the runtime that the command group requires the specified events to complete before the task may run. Figure 4 shows an example of how depends_on() orders tasks:
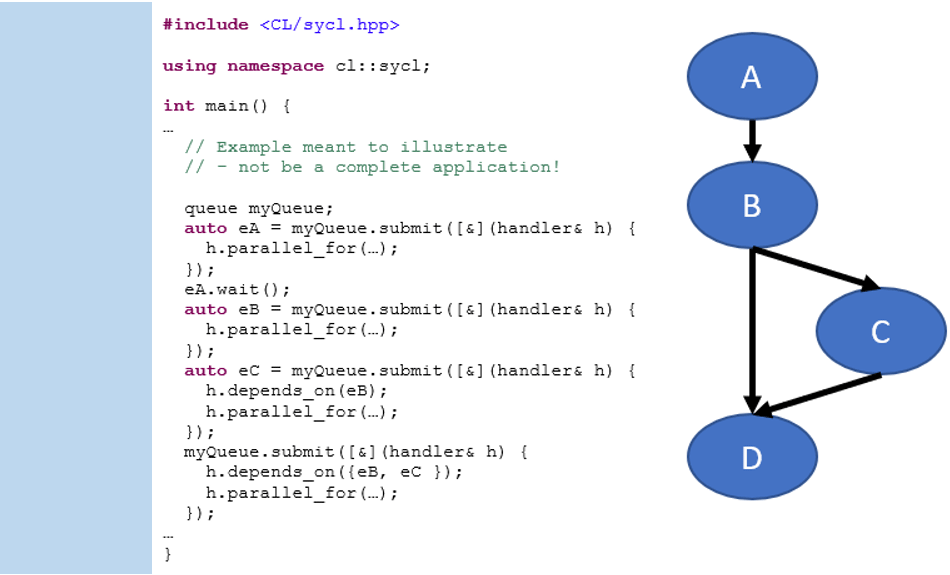
Figure 4. Use events and depends_on
Figure 4 also shows a helpful technique for debugging: To serialize parts of a graph, you can also synchronize through the host by explicitly calling the wait() method on the event. This forces the runtime to wait for the task to complete before continuing with running the host program. Waiting on the host can simplify debugging of applications, but it also constraints the asynchronous execution of tasks by coupling them with running the host program, so it is not recommended as a general-purpose solution in high-performance code. Similarly, you could call wait() on a queue object to block running on the host until all enqueued tasks in the queue have completed.
Do not use wait() or similar constructs to order running tasks for most code. Instead, the code needs to rely on either the depends_on() mechanism or accessors (described next) that allow the DPC++ runtime to manage the details of task ordering and sequencing for you.
Implicit Dependences with Accessors
Implicit dependences between tasks in DPC++ are often created from data dependences. Data dependences between tasks take three forms (shown in Figure 5).

Figure 5. Three forms of data dependences
Data dependences are expressed to the runtime through accessors. The order that you create accessors (the program order) creates an implicit ordering of the tasks using those accessors that the runtime manages for you. An example is shown in Figures 6 and 7.

Figure 6. Read after write
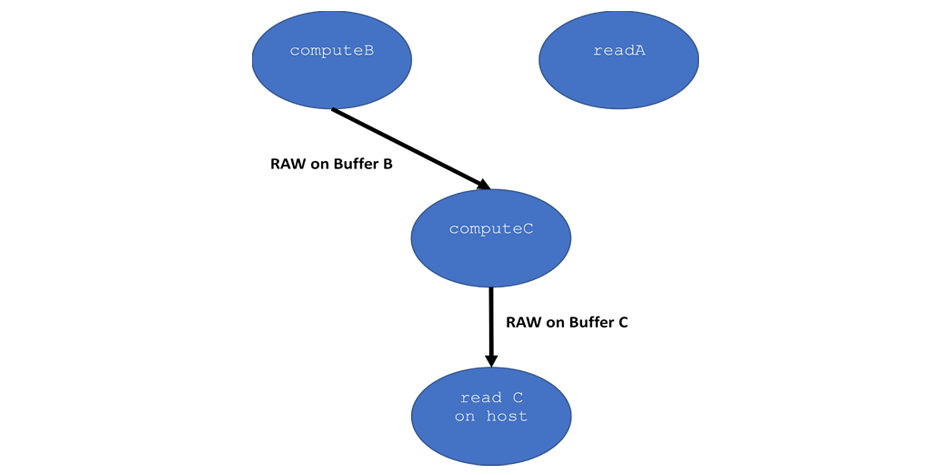
Figure 7. Read after write (RAW) task graph
In Figures 6 and 7, three kernels run—computeB, readA, and computeC—and then the final result is read on the host. The command group for kernel computeB creates two accessors: accA and accB. Kernel computeB reads from buffer A through accA and writes to buffer B through accB. The accessors give the DPC++ runtime the information that it needs to correctly order the running of the kernels, and when it needs to move data to specific memories (accessible by kernels running on different devices). For example, before readA or computeB start to run, buffer A must be copied from the host to the device and made available for use by the kernels.
The readA kernel creates a read-only accessor for buffer A, which creates a read-after-read (RAR) dependence because kernel readA is submitted after kernel computeB. RAR dependencies do not place extra restrictions on the runtime. So, kernels can run in any order (including at the same time) depending on what the runtime determines is the most efficient.
Kernel computeC reads buffer B—the output of computeB. Since kernel computeC was submitted after kernel computeB, kernel computeC has a RAW data dependence on buffer B. This means computeB must finish running and its output be made available as input to computeC before computeC runs.
Finally the program also creates a RAW dependence on buffer C between kernel computeC and the host, because the host needs to access buffer C after the kernel finishes. This forces the runtime to copy buffer C back to the host after computeC completes running, but the key is that the runtime does this automatically, behind the scenes. If you use accessors, the data movement and scheduling kernel runs for correctness are automatic.

Figure 8. WAR and WAW
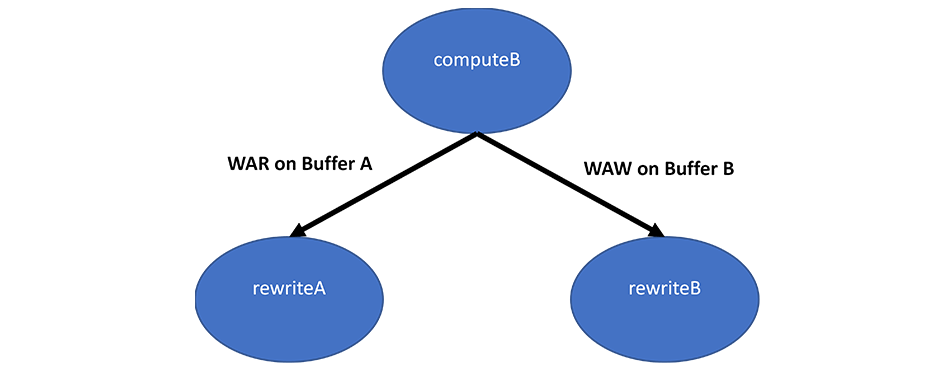
Figure 9. WAR and WAW task graph
In Figures 8 and 9, the program runs kernels computeB, rewriteA, and rewriteB. Kernel computeB once again reads from buffer A and writes to buffer B. Kernel rewriteA writes to buffer A, and kernel rewriteB writes to buffer B. Kernel rewriteA could run earlier than kernel computeB because less data needs to be transferred before the kernel is ready. But, it has to wait for kernel computeB to finish because there is a WAR dependence on buffer A.
While RAW dependences ensure that data flows in the correct direction, WAR dependences ensure existing values are not overwritten before they are read. The WAW dependence on buffer B functions in a similar way—if there were any reads of buffer B submitted in between kernels computeB and rewriteB, they would result in RAW and WAR dependences that would properly order the tasks. However, there is an implicit dependence between kernel rewriteB and the host in this example because the final data must be written back to the host. The WAW dependence ensures that the final output is correct.
Get Started Using DPC++
Access the cross-architecture language one of these ways:
- Use Intel® DevCloud for oneAPI: Test code and workloads across various Intel® processors and accelerators. No downloads, hardware acquisition, installation, set up, or configuration needed.
- Download Intel® oneAPI Toolkits
- Access the oneAPI specification
Other Resources
- Blogs: Dive into DPC++ | DPC++ Data Management – Part 1
- oneAPI Programming Guide | Four Chapters from the Upcoming DPC++ Book
- Free oneAPI and DPC++ webinars and how-to
Authors
Ben Ashbaugh is an Intel® software architect focused on parallel programming models for general-purpose computation on Intel graphics processors, including oneAPI and DPC++. He has authored numerous extensions for the OpenCL™ platform and is an Intel representative within the Khronos* Group, where he contributes to industry standards for the OpenCL platform, SPIR-V*, and SYCL*.
James Brodman is an Intel software engineer who researches languages and compilers for parallel programming. He is focused on the oneAPI initiative and DPC++. James has written extensively on programming models for Single Instruction Multiple Data (SIMD) and vector processing, languages for parallel processing, distributed memory theory and practice, programming multicore systems, and more.
Mike Kinsner is an Intel software engineer who researches and developing parallel programming models for various architectures. He also works on compilers for spatial architectures and is an Intel representative within the Khronos Group where he contributes to industry standards for SYCL and the OpenCL platform.
______
You May Also Like
| Intel® oneAPI Base Toolkit Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures. Get It Now See All Tools |
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Intel technologies may require enabled hardware, software, or service activation. No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.
© Intel Corporation, Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.