Intel and Google Cloud Platform (GCP) are collaborating to offer high-performance, customizable solutions based on the latest technologies. This includes AI software and hardware integration. This article shows how to use Intel Optimized AI Software in GCP environments like the Vertex AI platform and the Google Cloud Compute Engine.
Summary of Intel® AI Analytics Toolkit (AI Kit)
The Intel AI Analytics Toolkit (AI Kit) allows data scientists, developers, and researchers to use AI tools and frameworks to accelerate end-to-end data science and analytics pipelines on Intel® architecture. The components are built using oneAPI libraries for low-level compute optimizations. This toolkit maximizes performance from preprocessing through machine learning and provides interoperability for efficient model development.
The AI Kit has optimizations for the following frameworks and libraries:
Starting with TensorFlow 2.9, the optimizations by Intel are up-streamed automatically to the original distribution. For TensorFlow versions between 2.5 and 2.9, Intel optimizations can be enabled by setting the environment variable: TF_ENABLE_ONEDNN_OPTS=1. Intel® Extension for TensorFlow*, an extension plug-in based on TensorFlow PluggableDevice interface, enables the use of Intel GPUs with TensorFlow and facilitates the use of additional features such as Advanced Auto Mixed Precision (AMP) and quantization. This blog gives an easy introduction to the Intel extension with a free code sample.
Most optimizations are already up-streamed to the original distribution of PyTorch. Intel® Extension for PyTorch* is available for doing quantization and mixed precision and for an extra performance boost on Intel hardware, such as Intel CPUs and GPUs.
With Intel® Extension for Scikit-learn*, you can accelerate your scikit-learn applications and still have full conformance with all scikit-learn APIs and algorithms. Intel Extension for Scikit-learn is a free software AI accelerator that brings up to 100X acceleration across a variety of applications.
In collaboration with the XGBoost community, Intel has been directly upstreaming many optimizations for XGBoost. These optimizations provide superior performance on Intel CPUs. To achieve better inference performance, XGBoost models can be converted using daal4py, a tool that facilitates the usage of Intel® oneAPI Data Analytics Library (oneDAL).
Intel® Neural Compressor is an open-source library that performs model compression to reduce the model size and increase the speed of deep learning inference for deployment on CPUs or GPUs, by leveraging model compression technologies, such as quantization, pruning, and knowledge distillation. It is compatible with TensorFlow, PyTorch, MXNet and ONNX (Open Neural Network Exchange) models.
Modin* is a drop-in replacement for pandas. This enables data scientists to scale distributed DataFrame processing without any API code-related changes. The Intel® Distribution of Modin* adds optimizations to further accelerate processing on Intel hardware.
Additionally, Intel also offers:
- Intel® Distribution for Python*—a high-performance binary distribution of commonly used core Python numerical, scientific, and machine learning packages. This blog explains how to incorporate Intel Distribution for Python into your AI workflow.
- Model Zoo for Intel® Architecture—a collection of pretrained models, sample scripts, best practices, and tutorials for open-source machine learning models to run on Intel® Xeon® Scalable processors.
Get Started with Vertex AI
Introduction
Vertex AI provides a unified platform for machine learning development. It helps manage various stages in a ML workflow, such as working with datasets, labeling data, model development and deployment. As of November 2023, the following tools are also available in Vertex AI:
- Model Garden—a repository of foundation models.
- Workbench—a Jupyter-based environment for data science workflows.
- Colab Enterprise—a managed notebook environment that lets you share notebooks (IPYNB files) and collaborate with others.
- Pipelines—an MLOps service to help one automate, monitor, and govern ML systems.
- Generative AI Studio—a Google Cloud console tool for rapidly prototyping and testing generative AI models.
In addition, Vertex AI includes a preview offering of Ray on Vertex AI as well as a Marketplace for virtual machines, SaaS, APIs, and Kubernetes apps.
Installing Intel Optimized AI Software in Vertex AI
Workbench, as part of Vertex AI, provides two Jupyter notebook instance options: managed notebooks and user-managed notebooks (for custom environments). While Vertex AI already provides AI images, the user can also bring Docker container images with custom dependencies and frameworks that are not available in the default images. As many of the tools provided in the AI Kit are also available as docker containers, you could bring them to your Vertex AI Workbench environment.
Here’s a list of Docker containers from the AI Kit:
There are two pre-built docker images hosted in DockerHub, one which includes the Intel extension for CPU and another for GPU.
Run the following commands to pull the Docker container images:
CPU:
docker pull intel/intel-extension-for-tensorflow:cpu
GPU:
docker pull intel/intel-extension-for-tensorflow:gpu
2. Intel® Extension for PyTorch*
The CPU image for the Intel Extension for PyTorch is also available in DockerHub. Run the following command to pull the Docker container image:
docker pull intel/intel-optimized-pytorch:latest
Aside from the docker containers available, the user can install these libraries in a custom container offered as part of user-managed notebooks. If libraries are installed through pip or conda, the installation only persists while the kernel is running, as specified in the Google Cloud documentation1. If one includes the --user flag during a pip installation, the libraries persist until instance restart, and they are preserved during an upgrade. An alternative way to ensure a persistent installation is to include the library installations in the Dockerfile.2
The following environments available on Ubuntu 20.04 (as of November 2023) include some optimized libraries:
- Python 3 (with Intel® MKL)
- PyTorch 1.13 (with Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.1 (with LTS and Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.3 (with LTS and Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.6 (with LTS and Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.8 (with LTS and Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.9 (Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.10 (Intel® MKL-DNN/MKL)
- TensorFlow Enterprise 2.11 (Intel® MKL-DNN/MKL)
Here is a full list of container images. In case of choosing a TensorFlow environment, we recommend version 2.9 or newer, to take advantage of oneDNN by default, and version 2.10 or newer to have an environment compatible with the Intel® Extension for TensorFlow*.
The AI Kit tools can be installed with package managers such as Conda or PyPI. Below is a quick list of installation instructions for the AI Kit components (try to go through the installation guide for each tool to make sure it is compatible with the image and instance on which you install it).
- Intel Distribution for Python
conda install -c intel python
(This distribution does not contain basic packages such as NumPy.)
conda install -c intel intelpython3_core
(This installation option includes NumPy and other basic packages.)
conda install -c intel intelpython3_full
(This is the full complete distribution of Python. In addition to basic packages, this includes libraries such as scikit-learn, scikit-learn extension, XGBoost and daal4py.)
- Intel Extension for TensorFlow4
pip install --upgrade intel-extension-for-tensorflow[xpu]
GPU only:
pip install tensorflow==2.14.0
pip install --upgrade intel-extension-for-tensorflow[gpu]
CPU only:
pip install tensorflow==2.14.0
pip install --upgrade intel-extension-for-tensorflow[cpu]
- Intel Extension for PyTorch5
GPU6:
# General Python*
python -m pip install torch==1.13.0a0+git6c9b55e torchvision==0.14.1a0 intel_extension_for_pytorch==1.13.120+xpu -f https://developer.intel.com/ipex-whl-stable-xpu
# Intel® Distribution for Python*
python -m pip install torch==1.13.0a0+git6c9b55e torchvision==0.14.1a0 intel_extension_for_pytorch==1.13.120+xpu -f https://developer.intel.com/ipex-whl-stable-xpu-idp
CPU:
pip install intel_extension_for_pytorch
or
python -m pip install intel_extension_for_pytorch -f https://developer.intel.com/ipex-whl-stable-cpu
- Intel Extension for Scikit-learn
Install from PyPI (recommended by default)
[Optional step] [Recommended]
python -m venv env source env/bin/activate
pip install scikit-learn-intelex
or
conda create -n env -c conda-forge python=3.9 scikit-learn-intelex
- Intel Optimization for XGBoost
pip install xgboost
pip install daal4py
(daal4py is used to optimize XGBoost models and speed up inference on Intel architecture)
- Modin
pip install modin[all]
or
conda install -c conda-forge modin-all
(Open-source Modin packages, to which Intel also heavily contributes and maintains.)
- Intel Neural Compressor
pip install neural-compressor
or
conda install -c intel neural-compressor
If you have any issues with these tools, feel free to open a GitHub issue on the respective GitHub repository. Also, download this cheet sheet to quickly access the installation commands for various Intel Optimized AI Libraries & Frameworks.
Intel instances available in Vertex AI
Table 1 summarizes the Intel instances available in Vertex AI Workbench for us-central1 (Iowa) as of July 2023 (not all instances mentioned in the table are available in other regions). This information should help you choose appropriate instances for your AI workloads. As most of Intel’s software optimizations use Intel® Advanced Vector Extensions 512 (Intel® AVX-512), it is useful to ensure that your AI workload in Vertex AI will end up on an instance that supports Intel AVX-512 (such as Intel® Xeon® Scalable processors). At times the hardware behind the same type of instance can be of different generations and the performance might vary as a result. We highly encourage using the latest instances to get the best performance optimizations.
To specifically take advantage of the deep learning optimizations available in the AI Kit, Intel® Deep Learning Boost (Intel® DL Boost) (VNNI) and Intel® Advanced Matrix Extensions (Intel® AMX) with bfloat16 instructions are recommended as these instructions are leveraged by the software to optimize deep learning training and inference workloads. The 4th generation Intel® Xeon® Scalable processor is the first generation that supports Intel® AMX with bfloat16. Therefore, we recommend using instances based on 4th generation Intel Xeon Scalable processors for deep learning. As of November 2023, you can use 4th generation Intel Xeon Scalable processors for prediction jobs in Vertex AI. You can find more information here.
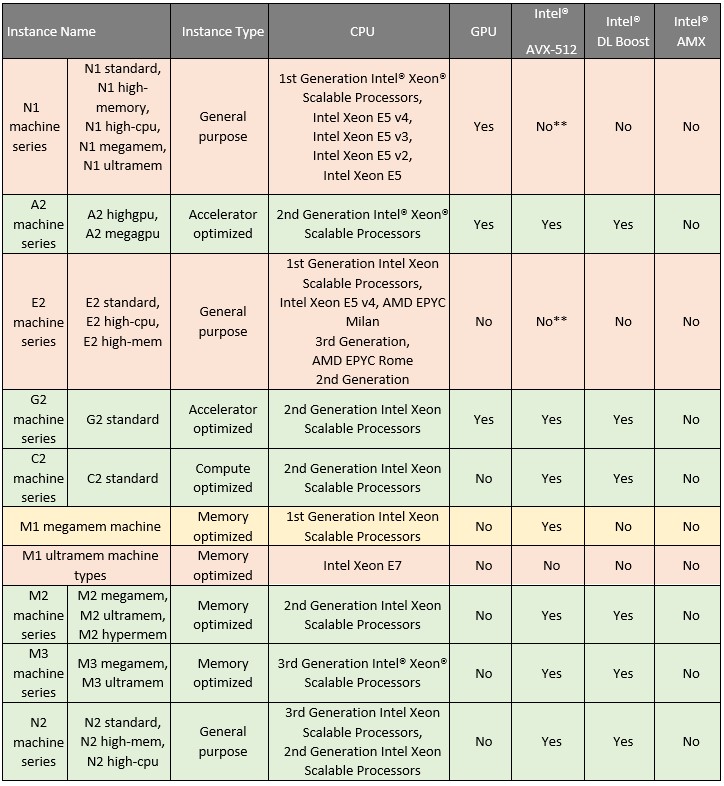
**While the 1st Generation Intel Xeon Scalable Processors has support for Intel AVX-512, it is missing in the other CPU families from the list
Legend:

In addition to Workbench instances mentioned in the table, there is a separate selection of instances that can be chosen for custom training and prediction jobs. We recommend checking out this documentation for custom training and this documentation for prediction to understand the machine types available for these workloads in Vertex AI. To ensure software compatibility, check out the software requirements of the optimization tool you plan to use and check that it is compatible with your image.
Short demo
In this section we will guide you through a few simple steps on how to verify the utility of Intel Extension for PyTorch, one of the tools available in the AI kit. Please note that the interface shown here corresponds to Vertex AI as of November 2023.
- In the Vertex AI menu, go to Workbench>USER-MANAGED NOTEBOOKS.
- Go to CREATE NEW

- Scroll down and click on ADVANCED OPTIONS
- Choose region: us-central1 (Iowa), Operating System: Ubuntu 20.04 [experimental], environment: PyTorch 1.13 (with Intel® MKL-DNN/MKL), machine type: n2-highcpu-8. Leave the rest of the parameters assigned to their default value.
- After the instance is created, OPEN JUPYTERLAB.
- Visit this repository. In the repository, download the notebook and upload it to the Jupyter Lab you just created. Make sure to install Intel Extension for PyTorch to run it.
Check out more examples from the AI and Analytics Samples repository to learn how to take advantage of the other Intel AI Kit tools.
Compute Engine instances powered by Intel Processors
Compute Engine delivers configurable virtual machines running in Google's data centers. Unlike in the case of Vertex AI, most of the software needs to be installed. At the same time, one can have more control over the hardware and can access instances that are not available for Vertex AI services.
In May 2023, Google Cloud announced the general availability of C3 VMs powered by 4th generation Intel Xeon Scalable processors. These instances support Intel AMX which means they can provide a significant boost to one’s Deep Learning workloads. Intel AMX is also required for enabling BF16 precision in Xeon processors. In this brief, you can find more details on Intel AMX and expected performance improvement. As of November 2023, C3 instances powered by 4th Gen Intel Xeon Scalable processors are available for online prediction in Vertex AI, so you can leverage AMX for your inference workloads.
Check out the article on how to deploy Intel® Neural Compressor Using Google Cloud Platform Service. This article provides instructions for deploying the Intel Neural Compressor to Docker containers and the containers are packaged by Bitnami on the Google Cloud Platform service for Intel Xeon Scalable processors.
Google Cloud Marketplace
Google Cloud Marketplace provides solutions integrated with Google Cloud to scale and simplify procurement with online discovery, flexible purchasing, and fulfillment of enterprise-grade cloud solutions.
The products available in the marketplace which are related to Intel AI are:
- Intel Neural Compressor for TF packaged by Bitnami: TensorFlow has been optimized with Intel® Neural Compressor. Intel Neural Compressor applies quantization, pruning, and knowledge distillation methods to achieve optimal product objectives, such as inference performance and memory usage, with expected accuracy criteria. This offering accelerates AI inference on Intel hardware, especially with Intel® Deep Learning Boost.
- TensorFlow for Intel packaged by Bitnami: TensorFlow has been optimized using oneAPI Deep Neural Network Library (oneDNN) primitives. oneDNN is a cross-platform performance library for deep learning applications. To increase its performance, this solution works with Intel® AVX-512 instructions.
- Dace IT℠ with Intel OpenVINO™ Intelligent Traffic Management 2021: This is designed to detect, track bikes and vehicles, as well as pedestrians, and to estimate a safety metric for an intersection. The application uses the DL Streamer included in the Intel® Distribution of OpenVINO™ toolkit. Initially, the pipeline is executed with the provided input video feed and models. The DL Streamer preprocesses the input and performs inference according to the pipeline settings. The inference results are parsed using callback function. These results are fed to the detection, tracking, and collision functions.
The new additions in the Marketplace can be found by searching for “Intel” or the name of the specific tool.
What’s Next?
Get started with Intel Optimized AI Software on GCP and follow this partner showcase page to stay up to date with Intel's collaboration with Google Cloud. We encourage you to also check out and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about the new 4th Gen Intel Xeon Scalable processors, visit Intel's AI Solution Platform portal where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.
Useful Resources
- Intel AI Developer Tools and Resources
- oneAPI Unified Programming Model
- Official Documentation - TensorFlow* Optimizations from Intel
- Official Documentation - PyTorch* Optimizations from Intel
- Official Documentation - Intel® Extension for Scikit-learn*
- Official Documentation - Intel® Optimization for XGBoost*
- Official Documentation - Intel® Distribution of Modin*
- Intel® Advanced Matrix Extensions Overview
- Accelerate AI Workloads with Intel® AMX
1Upgrade the environment of a user-managed notebooks instance https://cloud.google.com/vertex-ai/docs/workbench/user-managed/upgrade
2Here’s a guide on creating derivative containers https://cloud.google.com/deep-learning-containers/docs/derivative-container and on storing Docker container images in Artifact Registry https://cloud.google.com/artifact-registry/docs/docker/store-docker-container-images#create
3User-managed notebooks can be built also on to of Debian 10 and Debian 11, but the Intel AI Kit has not been validated on Debian
4Refer to this link for the latest version of Intel Extension for TensorFlow and here for the installation requirements.
5Refer to this link for the latest version of Intel® Extension for PyTorch*.