![]()
Modin* is an open source project which enables speeding up of data preparation and manipulation – a crucial initial phase in every data science workflow. Developed by Devin Petersohn during his work in the RISELab at UC Berkeley, it is a drop-in replacement for the extensively used Python* library, Pandas. Being fully compatible with Pandas, Modin has wide coverage of the Pandas API. It accelerates Pandas’ data handling operations by adopting a DataFrame partitioning method which enables splits along both rows and columns. This facilitates scalability and flexibility for Modin to perform parallel and distributed computations efficiently.
Intel, being one of the largest maintainers and contributors to the Modin project, has created its own build of the performant dataframe system viz. the Intel® Distribution of Modin. Available both as a stand-alone component and through the state-of-the-art Intel® AI Analytics Toolkit, powered by oneAPI, the Intel® Distribution of Modin aims to provide the best end-to-experience of expedited analytics on Intel platforms. This article aims to shine some light on both the classical Modin framework and its Intel® distribution.
Before proceeding, get yourself acquainted with the Pandas library to better understand the power of Modin.
Comparing Modin Vs Pandas
Pandas is a very popular open-source Python library for data manipulation and analysis. It has several benefits including speed, flexibility, and ease of use. There are however certain limitations with Pandas that Modin tries to address:
-
Pandas does not support multi-threading; you can only use one single core at a time for any operation whereas Modin automatically distributes the computation across all the cores on your machine for parallel computations. As modern processors become increasingly multi-core, this provides significant advantages.
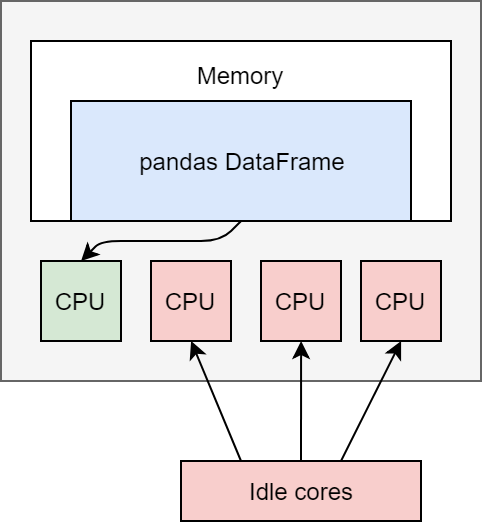
Image source: Official Modin documentation

- Pandas’ execution speed may deteriorate, or the application may run out of memory while handling voluminous data. Modin, on the other hand, can efficiently handle large datasets (~1TB+).
- Pandas usually copies the data irrespective of the changes made to it being in place or not. While Modin uses immutable data structures, unlike Pandas, and maintains a mutable pointer to it. So, for in place operations, Modin only adjusts the pointer among the DataFrames sharing common memory blocks. This enables memory layouts to remain unmodified, resulting in their better memory management than in Pandas.
- Instead of having duplicate methods of performing the same operation as in Pandas, Modin has a single internal implementation of each behavior while still covering the whole Pandas API.
- Pandas uses over 200 algebraic operators while Modin can perform the same operations with its internal algebra comprising of merely 15 operators. This makes Modin easier to use as a developer needs to learn and remember fewer operators.
Key Advantages of Modin
Modin provides several performance and productivity benefits to developers who are currently using Pandas.
- Ease of use: Modify a single line of code to accelerate your Pandas application.
- Productivity: Accelerate Pandas with minor code changes with no effort required to learn a whole new API. This also allows easy integration with the Python ecosystem.
- Robustness, light weight, and scalability: Modin makes it capable of processing MBs and even TBs of data on a single machine. It also allows seamless scaling across multiple cores with Dask and Ray distributed execution engines.
- Performance: Modin delivers orders of magnitude performance gains over Pandas.
Intel® Distribution of Modin
The Intel® Distribution of Modin is a performant, parallel, and distributed dataframe system that accelerates Pandas while using a fully compatible API. It provides all the advantages of stock Modin while also leveraging the OmniSci* framework in the back end to provides accelerated analytics on Intel® platforms.
Modin has a hierarchical architecture resembling that of a database management system. Such a structure enables optimization and swapping of individual components without disturbing the rest of the system.
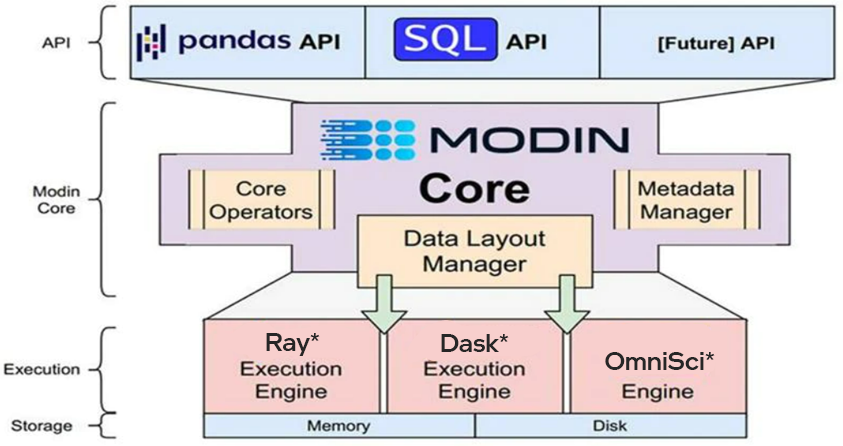
Image source: Official Intel® Distribution of Modin documentation
The user sends interactive or batch commands to Modin through API. Modin then executes them using one of its supported execution engines. The following top-down model shows the working of Modin.

Image source: Official documentation
To understand the architecture in detail, visit the documentation of Modin.
Supported specifications for Intel® Distribution of Modin
- Programming language: Python
- Operating System (OS): Windows* and Linux*
- Processors: Intel® Core™ and Intel® Xeon® processors
Installation methods
Modin can be installed with ease using one of the following ways:
- As a part of the Intel® AI Analytics Toolkit
- From PyPI using pip command
- From conda-forge collection
- From GitHub repository*
Code implementation
Here’s a practical demonstration of how some Pandas operations can be expedited using Modin. A customized dataset of dimensions \(2^{15}\) * \(2^{10}\) having random integers between 10 and 1000 has been used to test Pandas vs. Modin performance on it.
A stepwise explanation of the code is as follows:
- Install Modin
!pip install modin[all]
With [all] or nothing specified, Modin gets installed with all the supported execution engines. Instead, you can also work with a specific engine by specifying its name in the installation step e.g., modin[dask] or modin[ray].
- Import Modin and other required libraries.
import modin as md
import numpy as np
import pandas as pd - Create a customized of random integers using randint() method of NumPy.
arr = np.random.randint(low=10, high=1000, size= (2**15,2**10))
The ‘low’ and ‘high’ parameters specify the lowest and the highest number chosen for random distribution of integers; the ‘size’ parameter specifies the (rows * columns) dimensions of the array.
- Store the data into a CSV file.
np.savetxt("data.csv", arr, delimiter=",")
A condensed portion of the dataset appears as follows:
- Mean operation to calculate the average value of each column
- Using Pandas:
%time p_df.mean(axis=0) - Using Modin:
%time m_df.mean(axis=0)
- Using Pandas:
- Concatenate a DataFrame with itself
- Using Pandas:
%time pd.concat([p_df, p_df], axis=0) - Using Modin:
%time md.concat([m_df, m_df], axis=0)9
- Using Pandas:
- applymap() method to apply an operation elementwise to the whole DataFrame
- Using Pandas:
%time p_df.applymap(lambda i:i*2)
This line of code multiplies each element of the DataFrame by 2. - Using Modin:
%time m_df.applymap(lambda i:i*2)
- Using Pandas:
Below is a summary of recorded wall clock time and speedup achieved by Modin for each operation:
|
DataFrame operation |
Pandas (median of 4 runs) |
Modin (1st run) |
Modin (median of 4 runs) |
Speedup |
|---|---|---|---|---|
|
Read csv file |
10.800s |
15.400s |
9.190s |
1.175x |
|
Mean |
0.064s |
0.066s |
0.048s |
1.333x |
|
Concatenate |
0.162s |
0.002s |
0.001s |
162.000x |
|
applymap() |
8.570s |
0.034s |
0.029s |
295.517x |
Note: The speedup is computed as [(Pandas’ wall time)/ (Modin’s wall time)]. Both the wall time terms considered in the computation are medians for 4 runs of each operation.
♦ Click here to access the above-explained code sample. Note that the results may vary for different runs of the notebook depending upon the hardware configuration and software versions used, random generation of data and some initializations performed by Modin in the initial iteration.
Testing Details
Following is the information on the above tested code:
| Testing date: | 05/21/2022 |
|---|---|
| Test done by: | Intel Corporation |
| Hardware configuration used: | |
| Intel® Xeon® CPU @ 2.30GHz (single core) Intel® Xeon® CPU @ 2.30GHz (single core) |
|
| Processor | Broadwell (CPU family: 6, Model: 79) |
|
CPU MHz: |
2200.214 |
| Cache size: | 56320 kB |
|
Vendor ID: |
GenuineIntel |
| Stepping: | 0 |
|
fpu: |
yes |
| fpu_exception: | yes |
| cpuid level: | 13 |
| bogomips: | 4400.42 |
| clflush size: | 64 |
| cache alignment: | 64 |
| address size: | 46 bits physical, 48 bits virtual |
|
Operating system: |
Linux (Ubuntu* 18.04.3 LTS (Bionic Beaver)) |
| RAM: | 12.68 GB |
| Disk: | 107.72 GB |
| Software versions used: | |
|---|---|
| Coding environment: | Google Colab |
| Programming language: | Python 3.7.13 |
| NumPy 1.21.6 | |
| Pandas 1.3.5 | |
Potential limitations of Modin
- When Modin is run for the first time, it may take a long time to execute for some operations (at times even longer than Pandas) as it does some initialization in the initial iteration. However, over multiple runs it clearly demonstrates its acceleration capabilities.
- The gain in execution speed may be low or insignificant over that achieved using Pandas for some small datasets of say few KBs; larger the dataset more effective will be the acceleration.
- Visit this page to know about some scenarios where Modin may result in slower execution than Pandas.
Next steps
We hope that this post has piqued your interest in Modin by giving you a quick overview of its features and advantages while illustrating how it can easily expedite some of the crucial Pandas operations. There are several other operations covering a majority of the Pandas API for which Modin can give you faster outputs with minor code modifications. Get started with using Intel Distribution of Modin today as part of your AI workflows, and if interested we encourage you to contribute to the still relatively new and developing Modin project. We also encourage you to check out Intel’s other AI Tools and Framework optimizations and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio.
Useful Resources
To plunge deeper into Modin, refer to the following links:
- Modin: official documentation
- Modin: GitHub repository
- Data Science at Scale with Modin: Medium article
- Intel® distribution of Modin: documentation
- Intel® distribution of Modin: Getting started guide
- Intel® distribution of Modin: GitHub
- Intel® distribution of Modin: demo video
Acknowledgment:
We would like to thank Vadim Sherman, Andres Guzman-ballen, and Igor Zamyatin for their contributions to the blog and Rachel Oberman, Preethi Venkatesh, Praveen Kundurthy, John Kinsky, Jimmy Wei, Louie Tsai, Tom Lenth, Jeff Reilly, Keenan Connolly, and Katia Gondarenko for their review and approval help.
See Related Content
Articles
- Scale Your Pandas Workflow with Modin - No Rewrite Required
Read - One-Line Code Changes Boost Data Analytics Performance
Read - Deliver Fast Python Data Science and AI Analytics on CPUs
Read
Podcast
- An Open Road to Swift Dataframe Scaling
Listen
On-Demand Webinars
- Seamlessly Scale pandas Workloads with a Single Code-Line Change
Watch
Get the Software
Intel® oneAPI AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now