 What Is XGBoost?
What Is XGBoost?
eXtreme Gradient Boosting is an open source machine learning library built for an efficient implementation of distributed, gradient-boosted tree-based algorithms.
The library’s scalability, flexibility, and portability make it an extensively used machine learning framework for Python*, C++, Java*, R, Scala, Perl*, and Julia* on Windows*, Linux*, and macOS*.
The XGBoost algorithm was primarily designed for efficient compute time and memory resources. XGBoost delivers parallel-tree boosting and focuses on machine learning techniques such as regression, classification, and ranking problems.
Why Is Boosting Important?
Boosting is an ensemble technique where new models are added to correct the errors made by existing models and Gradient boosting technique employs gradient descent to minimize the loss function.
XGBoost further improves the generalization capabilities of a gradient-boosting method by employing advanced vector norms such as L1 norm (sum of the absolute values of the vector) and L2 norm (square root of the sum of the squared vector values).
Intel has powered several optimizations for XGBoost to accelerate gradient boosting models and improve its training and inference capabilities, including XGBoost Optimized for Intel® architecture.
Install and Use XGBoost Optimizations
For versions of XGBoost higher than 0.81, Intel has up-streamed training optimizations of XGBoost using the ‘hist’ parameter method. Optimizations for the inference stage were up-streamed after version 1.3.1, so any version higher than 1.3.1 has Intel optimizations for both training and inference phases. To get an extra inference boost to the already up-streamed optimizations or if you are using a version of XGBoost older than 0.81, you can convert the XGBoost model to daal4py (an API to the Intel® oneAPI Data Analytics Library [oneDAL]).
Intel-optimized XGBoost can be installed in the following ways:
- As a part of AI Tools
- From PyPI repository, using a pip package manager: pip install xgboost
- From Anaconda package manager:
- Using an Intel channel: conda install xgboost –c https://software.repos.intel.com/python/conda/
- Using a conda-forge channel: conda install xgboost –c conda-forge - As a Docker* container (provided you have a DockerHub account)
Machine Learning Training Using XGBoost
Get a comparative performance analysis with and without Intel optimizations.
We have created a code sample that shows the performance comparison of XGBoost without (0.81 version) and with (1.4.2 version) Intel optimizations. In this sample, we used the popular Higgs dataset with particle features and functions of those features to distinguish between a signal process that produces Higgs bosons and a background process that does not produce them. The Higgs boson is a basic particle in the standard model produced by the quantum excitation of the Higgs field. Here, an XGBoost model is trained, and the results with and without Intel optimizations are compared.
Note To use training optimizations of XGBoost for Intel architecture, initialize the tree_method parameter to hist as mentioned in the code sample.
Learn more about the XGBoost parameters mentioned in the code sample and other available parameters.
The performance of XGBoost with (0.9, 1.0, 1.1 versions) and without Intel optimizations (0.81 version) is compared on the following real-life datasets:
- Higgs (1,000,000 rows, 2 classes)
- Airline-OHE (1,000,000 rows, 2 classes)
- MSRank (3,000,000 rows, 5 classes)
- Letters (20,000 rows, 26 classes)
Comparing the run times for training shows up to 16x improvement with the Intel optimizations.
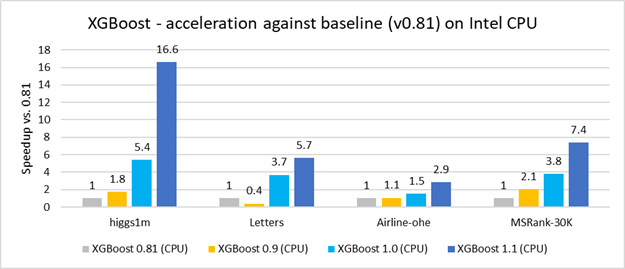
Figure 1. Release-to-release acceleration of XGBoost training.1
Machine Learning Inference Using XGBoost
Do a comparative performance analysis using up-streamed Intel optimizations and oneDAL.
For Python 3.6 and higher versions, the inference speedup attained by XGBoost optimized by Intel can be further elevated using the daal4py API of oneDAL. Install daal4py, import it, and you are all set to boost the inference stage by adding a single line of code between your model training and prediction phases—yes, it is that simple.
Here is the way to expedite your inference process using XGBoost optimized by Intel.
Install the daal4py API:
For more ways to install daal4py and detailed information on the API, check out daal4py.
Import daal4py as follows:
The performance of stock XGBoost with daal4py acceleration is compared on the following datasets,
- Mortgage (45 features, approximately 9M observations)
- Airline (691 features, one-hot encoding, approximately 1M observations)
- Higgs (28 features, 1M observations)
- MSRank (136 features, 3M observations)
The result shows up to 36x improvement using daal4py/the oneDAL library.
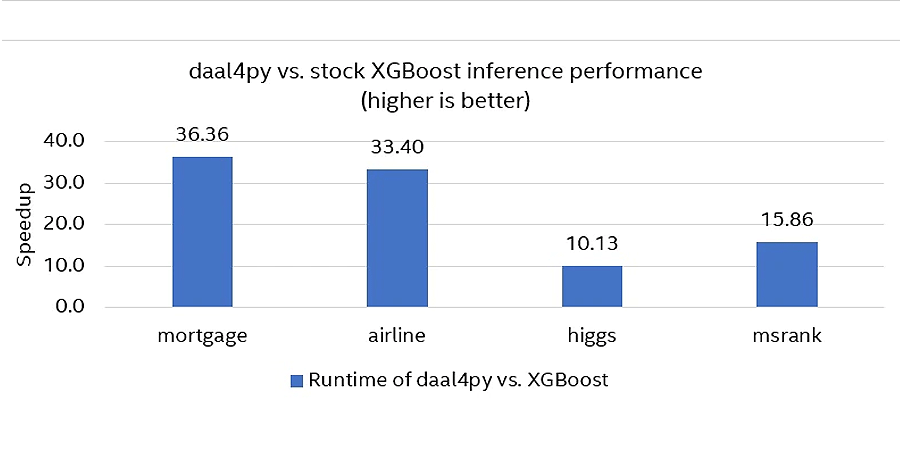
Figure 2. Performance comparison: A stock XGBoost Prediction versus daal4py prediction.2
Additionally, here is a simple example demonstrating the use of daal4py. In the example, an XGBoost model is trained and results are predicted using the daal4py prediction method. Also, this code sample shows a performance comparison between XGBoost prediction and daal4py prediction for the same accuracy.
What's Next
If XGBoost is your library of choice for an AI or machine learning workflow, you can get performance optimizations driven by Intel automatically by updating to the latest library version to make your gradient-boosted tree algorithm run faster by several times. You can also leverage the daal4py API of oneDAL if you want even greater performance enhancement for inference workloads. We also encourage you to check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow and, if interested, to learn about the unified, open, standards-based oneAPI programming model at the foundation of these tools and optimizations.
Additional Resources
Acknowledgment
We would like to thank Vadim Sherman, Rachel Oberman, Preethi Venkatesh, Praveen Kundurthy, John Kinsky, Jimmy Wei, Louie Tsai, Tom Lenth, Jeff Reilly, Monique Torres, Keenan Connolly, and John Somoza for their review and approval
You May Also Like
Related Webinars
- Maximize Your CPU Resources for XGBoost Training and Inference
- Intel® AI Tools and XGBoost for Predictive Modeling
- Learn Predictive Modeling with Intel® AI Tools
Related Articles
- Improve the Performance of XGBoost and LightGBM Inference
- XGBoost Optimized for Intel® Architecture Getting Started Guide
- Optimizing XGBoost Training Performance
- Achieve Up to 36X Faster Gradient Boosting Inference with Intel® oneAPI Data Analytics Library
Product and Performance Information
1 Image source: Medium*; Hardware configuration: c5.metal AWS EC2* instance: Intel® Xeon® 8275CL processor, two sockets with 24 cores per socket, 192 GB RAM (12 slots, 32 GB, 2933 MHz), Hyperthreading: on. Operating system: Ubuntu* 18.04.2 LTS; Testing date: November 10, 2020; Software configuration: XGBoost releases 0.81, 0.9, 1.0, 1.1 build from sources. Other software: Python 3.6, NumPy 1.16.4, pandas 0.25, scikit-learn* 0.21.2.
2 Image source: Intel; Hardware configuration: Intel Xeon Platinum 8275CL (2nd generation Intel Xeon Scalable processors): 2 sockets, 24 cores per socket, Hyperthreading: on, Turbo: on. Operating system: Ubuntu 18.04.4 LTS (Bionic Beaver), total memory of 192 GB (12 slots, 16 GB, 2933 MHz); Testing date: May 18, 2020; Software configuration: XGBoost 1.2.1, daal4py version 2020 update 3, Python 3.7.9, NumPy 1.19.2, pandas 1.1.3, and scikit-learn 0.23.2.
3 Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex.