Application Development
This document is a guide for helping developers to quickly develop and run applications on Intel® Data Center GPU Max Series. Four types of common applications are addressed in this development approach named SYCL*, CUDA, C/Fortran, and Python AI:
- SYCL: refers to a user developing a SYCL application from scratch for GPU
- CUDA: refers to a user having an existing CUDA application and wanting to migrate this application to SYCL code that offloads the computation to GPU
- C++/Fortran: refers to a user having the C++/Fortran application running on CPU and wanting to extend this application to offload the OpenMP region to GPU
- Python AI: refers to a user having a Python AI framework workload running on the CPU and wanting to extend this application to offload the training/inference part to GPU.
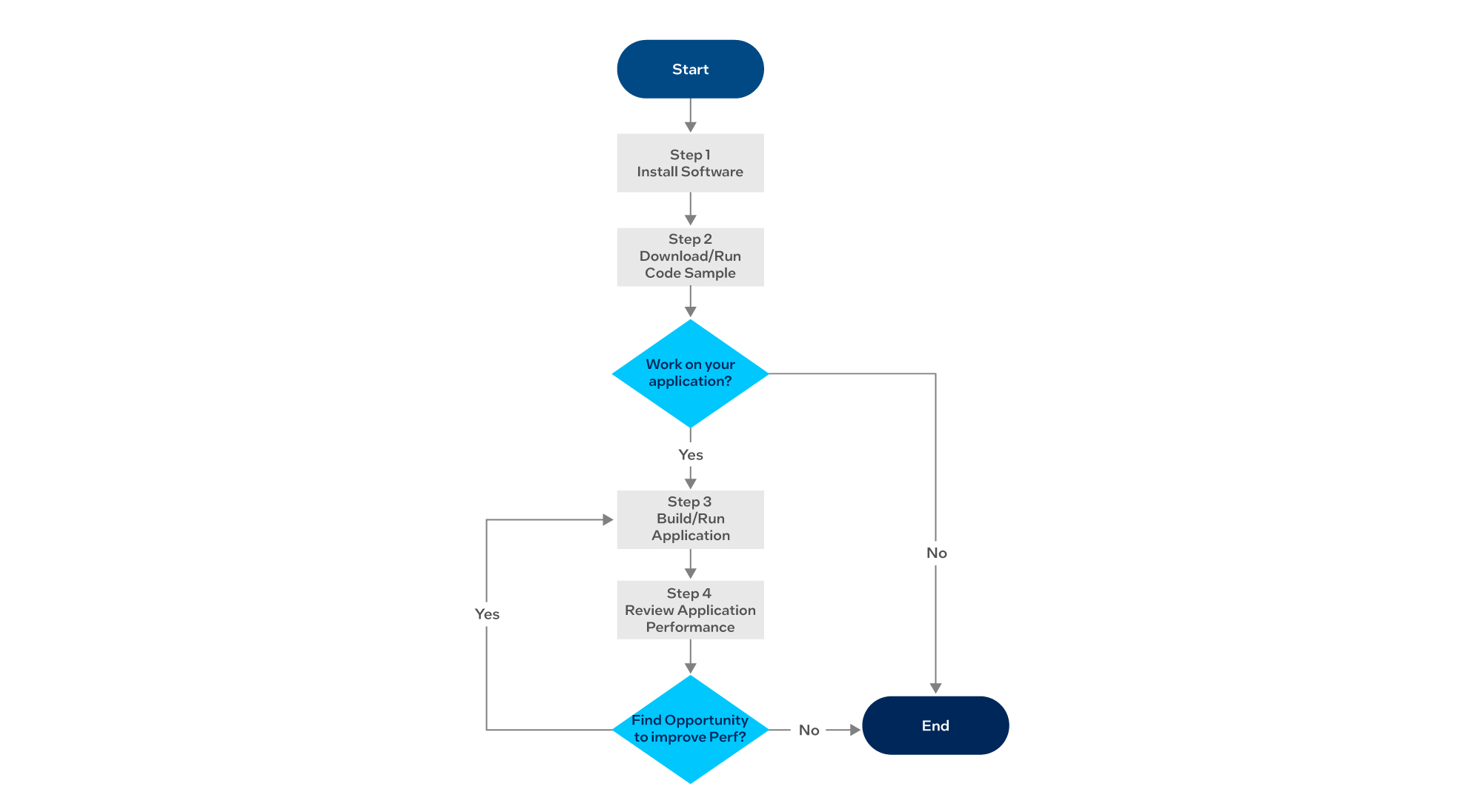
Depending on the type of development approach, this guide refers users to the appropriate documents for quickly developing the application for Intel Data Center GPU Max Series. The flow chart below shows the general approach used in this guide.
- Install the required software toolkits.
- Get familiar with the toolkits by:
- Ensuring Intel Data Center GPU Max Series works correctly.
- Users can download, compile and run a code sample on Intel Data Center GPU Max Series.
- Introduces user to build and run the application depending on the application types (SYSCL, CUDA, C/Fortran, Python AI).
- The users use Intel tools to identify opportunities to improve code performance. If there is any, then go to Step 3 to implement the code change.
Step 1: Install the Software
The first step is to install the Intel oneAPI toolkits. For SYSCL, CUDA, and C/Fortran application types, you need to download the Intel® oneAPI Base Toolkit and Intel® HPC Toolkit. The Intel oneAPI Base Toolkit is designed for general computing applications, and the Intel oneAPI HPC Toolkit is designed for High-Performance computing. These toolkits provide the tools developers need to build, analyze, optimize and scale HPC applications.
If you work with Python AI workload, you need to download the Intel oneAPI Base Toolkit and Intel oneAPI Analytics Toolkit. The Intel oneAPI Analytics Toolkit allows developers Python* tools and frameworks to accelerate end-to-end data science and analytics pipelines on Intel® architecture.
| Development Approach | Step 1: Install the Software |
|---|---|
| SYCL CUDA C++/Fortran |
• Install Intel oneAPI Base Toolkit • Install Intel oneAPI HPC Toolkit |
| Python AI | • Install Intel oneAPI Base Toolkit • Install AI Tools |
Resources:
Step 2: Download and Run Code Sample
In this step, you should familiarize yourself with the Intel Data Center GPU Max Series by downloading and running a code sample. At the end of the step, if the code sample runs correctly, your Intel Data Center GPU Max Series is most likely working properly. You can download the Intel oneAPI code sample from
$ git clone https://github.com/oneapi-src/oneAPI-samples.git
To compile and run the code sample, you must activate the oneAPI environment variables:
$ source /opt/intel/oneapi/setvars.sh
Running a SYCL code sample:
$ cd oneAPI-samples/DirectProgramming/C++SYCL/DenseLinearAlgebra/matrix_mul
$ make all
$ make run
$ ./matrix_mul_dpc
Device: Intel® Graphics [0x0bd5]
Problem size: c(150,600) = a(150,300) * b(300,600)
Result of matrix multiplication using SYCL: Success - The results are correct!
Running a CUDA code sample:
$ cd oneAPI-samples/DirectProgramming/C++SYCL/guided_concurrentKernels_SYCLMigration
$ mkdir build
$ cd build
$ cmake ..
$ make
Running a C++/Fortran code sample:
$ cd oneAPI-samples/DirectProgramming/C++/CompilerInfrastructure/OpenMP_Offload_Features
$ mkdir build
$ cd build
$ cmake ..
$ make
$ src/prog4
SYCL: Running on Intel® Graphics [0x0bd5]
SYCL and OMP memory: passed
OMP and OMP memory: passed
OMP and SYCL memory: passed
SYCL and SYCL memory: passed
Running a AI Python code sample:
For example, to run a Pytorch workload on Intel Data Center GPU Max Series, you first activate the pytorch-gpu conda env available inside oneAPI AI kit.
$ conda activate pytorch-gpu
And run some code sample at https://intel.github.io/intel-extension-for-pytorch/xpu/1.13.10+xpu/tutorials/examples.html
| Development Approach | Step 2: Download /Run Code Sample |
|---|---|
| SYCL CUDA C++/Fortran |
• Download oneAPI Code Sample • Set oneAPI environment variables • Compile and run the code sample accordingly |
| Python AI | • Download code sample from https://intel.github.io/intel-extension-for-pytorch/xpu/1.13.10+xpu/tutorials/examples.html • Set oneAPI environment variables • Activate the corresponding conda environment • Run the python code sample |
Resources:
Step 3A: Build Application
The Intel oneAPI Samples provides a good resource for writing SYCL code to offload the computation to Intel GPU. In addition, please refer to SYCL documentation.
For the CUDA development approach, migrate your CUDA code with the Intel DPC++ Compatibility Tool, which is part of the oneAPI Base Toolkit. Then finish writing the SYCL code. Finally, refer to the SYCL book.
For the C++/Fortran development approach, OpenMP* offload constructs are a set of directives for C++ and Fortran that allow you to offload data and execution to target accelerators such as GPUs. The constructs are supported in the Intel oneAPI HPC Toolkit with the Intel® C++ Compiler and the Intel® Fortran Compiler.
Refer to the Intel oneAPI GPU Optimization Guide for GPU offload tips and instructions.
You may use the Intel Advisor tool to analyze your code and identify the best opportunities for GPU offload. The Offload Modeling feature provides performance speedup projections, estimates offload overhead and pinpoints performance bottlenecks. Offload Modeling enables you to improve ROI by modeling different hardware solutions to maximize performance.
For Python AI development approach, you can implement code for GPU offload using Intel® Extension for PyTorch* GPU or TensorFlow 2.10 or above, Intel Extension for TensorFlow. Set some env variables if necessary. Refer to Intel® Extension for PyTorch or Intel Extension for TensorFlow* to offload the computation to Intel GPU.
| Development Approach | Step 3A: Build Application |
|---|---|
| SYCL | • Implement SYCL code • Run Offload Modeling Analysis in Intel Advisor to analyze your code |
| CUDA | • Use the Intel DPC++ Compatibility Tool to migrate most of your code • Inline comments help you finish writing and tuning your code • Run Offload Modeling Analysis in Intel Advisor to analyze your code |
| C++/Fortran | • Implement OpenMP offload onto the GPU • Run Offload Modeling Analysis in Intel Advisor to analyze your code |
| Python AI | • For the PyTorch framework, implement GPU offload by using Intel Extension for PyTorch* GPU • For the TensorFlow framework, install stock TensorFlow 2.10 or above, and Intel Extension for TensorFlow* |
Resources:
- Intel® oneAPI DPC++/C++ Compiler Developer Guide and Reference
- Data Parallel C++, by James Reinders et al.
- Intel oneAPI GPU Optimization Guide
- See the Implement GPU Offload section on page Optimize Your GPU Application with the Intel® oneAPI Base Toolkit.
- OpenMP Offloading Tuning Guide
- Training on Migrate from CUDA* to C++ with SYCL*
- Intel Extension for PyTorch*
- Intel Extension for PyTorch* Documentation
- Intel Extension for TensorFlow* - Quick Get Started
- Intel Extension for TensorFlow*
Step 3B: Run Application
If you haven’t done setting environment variables in Step 2, you must set up the oneAPI development environment:
$ source /opt/<path to oneAPI installation>/setvars.sh
For SYCL, CUDA, and C++/Fortran development approach, compile your application with icpx/ifx (with option -fsycl for SYCL and CUDA). Refer to Intel oneAPI DPC++/C++ Compiler Developer Guide and Reference for more information. For CUDA application, you can migrate your code with the Intel DPC++ Compatibility Tool. Finally, you can also debug your application using Intel® Distribution for GDB*.
For the Python AI development approach, you can run your application using Intel® Distribution for Python*, which is part of the Intel® AI Analytics Toolkit.
| Development Approach | Step 3B: Run Application |
|---|---|
| SYCL CUDA C++/Fortran |
• Set oneAPI environment variables • For CUDA application, migrate code with the Intel DPC++ Compatibility tool and finish writing SYCL code • Compile application with icpx/ifx (option -fsycl for SYCL and CUDA) • Optionally, debug your code with Intel® Distribution for GDB* |
| Python AI | • Set oneAPI environment variables • Run your code with Intel® Distribution for Python* |
Resources:
- Intel oneAPI Programming Guide
- Intel oneAPI DPC++/C++ Compiler Developer Guide and Reference
- A debug-oriented user study includes several samples illustrating how to use oneAPI Debug tools to find real-world bugs.
- Intel® Distribution for GDB*
Step 4: Review Application Performance
Analyze your application by running Roofline Analysis in Intel® Advisor, and GPU Offload analysis in Intel® VTune™ Profiler. Refer to the oneAPI GPU Optimization Guide to improve the performance. Then implement the change by going back to step 3.
| Development Approach | Step 4: Review Application Performance |
|---|---|
| SYCL CUDA C++/Fortran Python AI |
• Run Roofline Analysis in the Intel Advisor tool • Run the GPU Offload analysis, GPU Compute/Media Hotspots analysis in Intel® VTune™ Profiler |
Resources: