Visible to Intel only — GUID: GUID-3F71D514-38FD-4D9F-92C8-3D71FD5C3C3F
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-3F71D514-38FD-4D9F-92C8-3D71FD5C3C3F
Data Types
oneDNN functionality supports a number of numerical data types. IEEE single precision floating-point (fp32) is considered to be the golden standard in deep learning applications and is supported in all the library functions. The purpose of low precision data types support is to improve performance of compute intensive operations, such as convolutions, inner product, and recurrent neural network cells in comparison to fp32. Boolean data type is used for Graph Compiler to optimize operations which take bool as inputs and/or outputs data type.
Data type |
Description |
|---|---|
f32 |
|
bf16 |
|
f16 |
|
s8/u8 |
signed/unsigned 8-bit integer |
s4/u4 |
signed/unsigned 4-bit integer |
f64 |
|
boolean |
bool (size is C++ implementation defined) |
f8_e5m2 |
OFP8 standard 8-bit floating-point with 5 exponent and 2 mantissa bits |
f8_e4m3 |
OFP8 standard 8-bit floating-point with 4 exponent and 3 mantissa bits |
NOTE:
Boolean is only supported in the Graph Compiler in CPU engines. No primitives support boolean during primitive computation.
Inference and Training
oneDNN supports training and inference with the following data types:
Usage mode |
CPU |
GPU |
|---|---|---|
Inference |
f32, bf16, f16, f8_e5m2/f8_e4m3, s8/u8, s4/u4, boolean |
f32, bf16, f16, f8_e5m2/f8_e4m3, s8/u8, f64 |
Training |
f32, bf16, f16 |
f32, bf16, f64 |
NOTE:
Using lower precision arithmetic may require changes in the deep learning model implementation.
NOTE:
f64 is only supported for convolution, reorder, layer normalization and pooling primitives, on the GPU engine.
NOTE:
Boolean is only supported by the oneDNN graph API when the graph compiler backend is enabled.
NOTE:
s4/u4 data types are only supported as a storage data type for weights argument in case of weights decompression. For more details, refer to Matmul Tutorial: weights decompression.
See topics for the corresponding data types details:
Individual primitives may have additional limitations with respect to data type by each primitive is included in the corresponding sections of the developer guide.
General numerical behavior of the oneDNN library
During a primitive computation, oneDNN can use different datatypes than those of the inputs/outputs. In particular, oneDNN uses wider accumulator datatypes (s32 for integral computations, and f32/f64 for floating-point computations), and converts intermediate results to f32 before applying post-ops (f64 configuration does not support post-ops). The following formula governs the datatypes dynamic during a primitive computation:
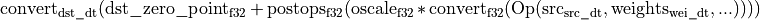
The Op output datatype depends on the datatype of its inputs:
if src, weights, … are floating-point datatype (f32, f16, bf16, f8_e5m2, f8_e4m3), then the Op outputs f32 elements.
if src, weights, … are integral datatypes (s8, u8, s32), then the Op outputs s32 elements.
if the primitive allows to mix input datatypes, the Op outputs datatype will be s32 if its weights are an integral datatype, or f32 otherwise.
The accumulation datatype used during Op computation is governed by the accumulation_mode attribute of the primitive. By default, f32 is used for floating-point primitives (or f64 for f64 primitives) and s32 is used for integral primitives.
No downconversions are allowed by default, but can be enabled using the floating-point math controls described in Primitive Attributes: floating-point math mode.
Floating-point environment
oneDNN floating-point computation behavior is controlled by the floating-point environment as defined by the C and C++ standards, in the fenv.h header. In particular, the floating-point environment can control:
the rounding mode. It is set to round-to-nearest tie-even by default on x64 systems and can be changed using the fesetround() C function.
the handling of denormal values. Computation on denormals can negatively impact performance on x64 systems and are not flushed to zero by default.
NOTE:
Most DNN applications do not require precise computations with denormal numbers and flushing these denormals to zero can improve performance. On x64 systems, the floating-point environment can be updated to allow flushing denormals to zero as follow:
#include <xmmintrin.h>
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);Hardware Limitations
While all the platforms oneDNN supports have hardware acceleration for fp32 arithmetics, that is not the case for other data types. Support for low precision data types may not be available for older platforms. The next sections explain limitations that exist for low precision data types for Intel(R) Architecture processors, Intel Processor Graphics and Xe Architecture graphics.
Intel(R) Architecture Processors
oneDNN performance optimizations for Intel Architecture Processors are specialized based on Instruction Set Architecture (ISA). The following ISA have specialized optimizations in the library:
Intel Streaming SIMD Extensions 4.1 (Intel SSE4.1)
Intel Advanced Vector Extensions (Intel AVX)
Intel Advanced Vector Extensions 2 (Intel AVX2)
Intel Advanced Vector Extensions 512 (Intel AVX-512)
Intel Deep Learning Boost (Intel DL Boost)
Intel Advanced Matrix Extensions (Intel AMX)
The following table indicates the minimal supported ISA for each of the data types that oneDNN recognizes.
Data type |
Minimal supported ISA |
|---|---|
f32 |
Intel SSE4.1 |
s8, u8 |
Intel AVX2 |
bf16 |
Intel DL Boost with bfloat16 support |
f16 |
Intel AVX512-FP16 |
boolean |
Intel AVX2 |
f8_e5m2, f8_e4m3 |
TBA. |
NOTE:
See Nuances of int8 Computations in the Developer Guide for additional limitations related to int8 arithmetic.
NOTE:
The library has functional bfloat16 support on processors with Intel AVX-512 Byte and Word Instructions (AVX512BW) support for validation purposes. The performance of bfloat16 primitives on platforms without hardware acceleration for bfloat16 is 3-4x lower in comparison to the same operations on the fp32 data type.
NOTE:
The Intel AMX instructions ignore the floating-point environment flag and always round to nearest tie-even and flush denormals to zero.
NOTE:
f64 configuration is not available for the CPU engine.
NOTE:
The current f16 CPU instructions accumulate to f16. To avoid overflow, the f16 primitives might up-convert the data to f32 before performing math operations. This can lead to scenarios where a f16 primitive may perform slower than similar f32 primitive.
Intel(R) Processor Graphics and Xe Architecture graphics
oneDNN performance optimizations for Intel Processor graphics and Xe Architecture graphics are specialized based on device microarchitecture (uArch). The following uArchs and associated devices have specialized optimizations in the library:
Xe-LP (accelerated u8, s8 support via DP4A)
Intel(R) UHD Graphics for 11th-14th Gen Intel(R) Processors
Intel(R) Iris(R) Xe Graphics
Intel(R) Iris(R) Xe MAX Graphics (formerly DG1)
Xe-HPG (accelerated f16, bf16, u8, and s8 support via Intel(R) Xe Matrix Extensions (Intel(R) XMX), aka DPAS)
Intel(R) Arc(TM) Graphics (formerly Achemist)
Intel(R) Data Center GPU Flex Series (formerly Arctic Sound)
Xe-HPC (accelerated f16, bf16, u8, and s8 support via DPAS and f64 support via MAD)
Intel(R) Data Center GPU Max Series (formerly Ponte Vecchio)
The following table indicates the data types with performant compute primitives for each uArch supported by oneDNN. Unless otherwise noted, all data types have reference support on all architectures.
uArch |
Supported Data types |
|---|---|
Xe-LP |
f32, f16, s8, u8 |
Xe-HPG |
f32, f16, bf16, s8, u8 |
Xe-HPC |
f64, f32, bf16, f16, s8, u8 |
TBA |
f64, f32, bf16, f16, s8, u8, f8_e5m2, f8_e4m3 |
NOTE:
f64 configurations are only supported on GPU engines with HW capability for double-precision floating-point.
NOTE:
f8_e5m2 compute operations have limited performance through upconversion on Xe-HPC.
NOTE:
f16 operations may be faster with f16 accumulation on GPU architectures older than Xe-HPC. Newer architectures accumulate to f32.
NOTE:
Boolean is only supported by the oneDNN graph API when the graph compiler backend is enabled. The graph compiler backend only supports the CPU engine.