A newer version of this document is available. Customers should click here to go to the newest version.
Kernel Launch
In SYCL, work is performed by enqueueing kernels into queues targeting specific devices. These kernels are submitted by the host to the device, executed by the device and results are sent back. The kernel submission by the host and the actual start of execution do not happen immediately - they are asynchronous and as such we have to keep track of the following timings associated with a kernel.
- Kernel submission start time
-
This is the at which the host starts the process of submitting the kernel.
- Kernel submission end time
-
This is the time at which the host finished submitting the kernel. The host performs multiple tasks like queuing the arguments, allocating resources in the runtime for the kernel to start execution on the device.
- Kernel launch time
-
This is the time at which the kernel that was submitted by the host starts executing on the device. Note that this is not exactly same as the kernel submission end time. There is a lag between the submission end time and the kernel launch time, which depends on the availability of the device. It is possible for the host to queue up a number of kernels for execution before the kernels are actually launched for execution. More over, there are a few data transfers that need to happen before the actual kernel starts execution which is typically not accounted separately from kernel launch time.
- Kernel completion time
-
This is the time at which the kernel finishes execution on the device. The current generation of devices are non-preemptive, which means that once a kernel starts, it has to complete its execution.
Tools like VTuneTM Profiler (vtune), clIntercept, and zeIntercept provide a visual timeline for each of the above times for every kernel in the application.
The following simple example shows time being measured for the kernel execution. This will involve the kernel submission time on the host, the kernel execution time on the device, and any data transfer times (since there are no buffers or memory, this is usually zero in this case).
void emptyKernel1(sycl::queue &q) {
Timer timer;
for (int i = 0; i < iters; ++i)
q.parallel_for(1, [=](auto) {
/* NOP */
}).wait();
std::cout << " emptyKernel1: Elapsed time: " << timer.Elapsed() / iters
<< " sec\n";
} // end emptyKernel1
The same code without the wait at the end of the parallel_for measures the time it takes for the host to submit the kernel to the runtime.
void emptyKernel2(sycl::queue &q) {
Timer timer;
for (int i = 0; i < iters; ++i)
q.parallel_for(1, [=](auto) {
/* NOP */
});
std::cout << " emptyKernel2: Elapsed time: " << timer.Elapsed() / iters
<< " sec\n";
These overheads are highly dependent on the backend runtime being used and the processing power of the host.
One way to measure the actual kernel execution time on the device is to use the SYCL built-in profiling API. The following code demonstrates usage of the SYCL profiling API to profile kernel execution times. It also shows the kernel submission time. There is no way to programmatically measure the kernel launch time since it is dependent on the runtime and the device driver. Profiling tools can provide this information.
//==============================================================
// Copyright © 2022 Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <CL/sycl.hpp>
class Timer {
public:
Timer() : start_(std::chrono::steady_clock::now()) {}
double Elapsed() {
auto now = std::chrono::steady_clock::now();
return std::chrono::duration_cast<Duration>(now - start_).count();
}
private:
using Duration = std::chrono::duration<double>;
std::chrono::steady_clock::time_point start_;
};
int main() {
Timer timer;
sycl::queue q{sycl::property::queue::enable_profiling()};
auto evt = q.parallel_for(1000, [=](auto) {
/* kernel statements here */
});
double t1 = timer.Elapsed();
evt.wait();
double t2 = timer.Elapsed();
auto startK =
evt.get_profiling_info<sycl::info::event_profiling::command_start>();
auto endK =
evt.get_profiling_info<sycl::info::event_profiling::command_end>();
std::cout << "Kernel submission time: " << t1 << "secs\n";
std::cout << "Kernel submission + execution time: " << t2 << "secs\n";
std::cout << "Kernel execution time: "
<< ((double)(endK - startK)) / 1000000.0 << "secs\n";
return 0;
}
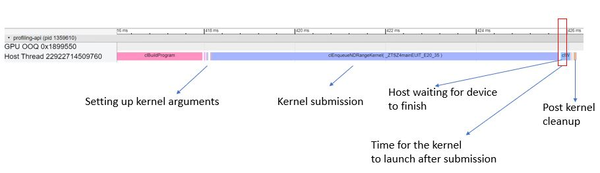
The following picture shows the timeline of the execution for the above example. This picture is generated from running clIntercept to generate a trace file and using Chrome* tracing to visualize the timeline. In this timeline there are two swim lanes, one for the host side and another for the device side. Notice that the only activity on the device side is the execution of the submitted kernel. A significant amount of work is done on the host side to get the kernel prepared for execution. In this case, since the kernel is very small, total execution time is dominated by the JIT compilation of the kernel, which is the block labeled clBuildProgram in the figure below.
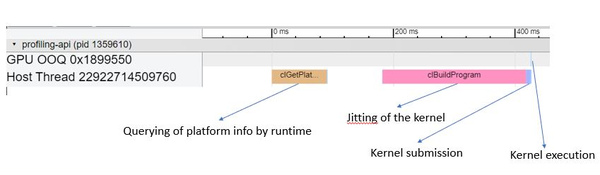
The following picture is the zoomed in version to show the detail of the functions called on the host side to submit the kernel. Here the time is dominated by the clEnqueueNDRangeKernel. Also notice that there is a lag between the completion of kernel submission on the host and the actual launch of the kernel on the device.