This article was originally published in the Proceedings of IWOCL'24.
Since widening its scope and becoming its independent working group 5 years ago, SYCL* has evolved into the alternative to CUDA* by championing an open-source and standards-based approach to accelerator offload, including GPUs. SYCL became the cornerstone of the oneAPI industry initiative, which combines it with a range of library and API specifications to create a multiarchitecture, multi-vendor programming model with the components needed by a developer relying on an ecosystem of ready-to-use device interfaces for common optimized and specialized routines.
In September last year, this industry initiative became the starting point of the Unified Acceleration Foundation (UXL), governed by the Linux Foundation and hosted by the Linux Foundation’s Joint Development Foundation (JDF). Its steering members include Arm, Fujitsu, Google Cloud, Imagination Technologies, Intel, Qualcomm Technologies Inc., Samsung, and VMware. SYCL and the drive to wide SYCL 2020 adoption and compliance are still at the heart of this effort. To help enable ecosystem-wide usage across workloads and accelerator hardware, it must be possible to conveniently migrate the CUDA-based legacy codebase of popular applications to SYCL. SYCLomatic was developed to provide a tool to ingest a project targeting C++ with CUDA-based GPU offload and translate it into ready-to-build C++ with SYCL code. This article go into advanced considerations for successful, and performant migrated code.
Migration Flow
 Figure 1: CUDA to SYCL Migration Flow
Figure 1: CUDA to SYCL Migration Flow
- Compile your original source code using the compiler defined for your original CUDA project and verify that it functions as expected.
- Use intercept build to obtain a JSON build environment database file, which is used to pass on all the make or cmake project details to the migration tool and generate a makefile for the branched SYCL project.
- Execute SYCLomatic.
c2s [options] [<source0>... <sourceN>] - Process the results and address warnings.

Figure 2: Basic SYCLomatic Command Options
SYCLomatic uses CLANG build infrastructure. Syntax-checking differences between CLANG and NVCC need to be taken into consideration.
Over the last year, the improvements to SYCLomatic and its binary distribution equivalent, the Intel® DPC++ Compatibility Tool, have been strongly focused on simplifying any efforts associated with step 4.
The goal is to make resolving warnings easier, automatically migrating CUDA library calls, assisting with multiarchitecture memory latency and work group management, and leveraging SYCL 2020 interoperability for temporary solutions when intrinsics or difficult-to-map code is found in the original source.
Library Call Migration
SYClomatic, by default, uses a YAML rule file to migrate CUDA library calls to the equivalent calls to oneAPI spec elements:
| cuBLAS, cuFFT, cuRAND, cuSolver, cuSparse | oneMKL |
| Thrust, CUB | oneDPL |
| cuDNN | oneDNN |
| NCCL | oneCCL |
Suppose different libraries should be targeted for the migration (for example, BLIS), or the default migration rules need to be modified to account for custom requirements. In that case, SYCLomatic provides the following syntax for user-defined rules:
c2s sample.cu --rule-file=rule_file1.YAML
Multiple custom rule files can be passed to the migration tool.
Additionally, the open backend specification of oneAPI has been leveraged to permit SYCL code with migrated oneAPI spec library calls to run on many different target hardware-specific runtimes.

Figure 3: oneAPI Library Backend Multi-vendor Support
Taking the example of BLAS functionality (Figure.3), while the default assumption is a hardware agnostic portBLAS backend, it is also possible to pair the migrated codebase with backend code for NVIDIA cuBLAS, AMD rocBLAS or Intel® oneAPI Math Kernel Library (oneMKL).
In the very rare scenario that a CUDA library call cannot be resolved as part of migration or intrinsics are used in the original codebase, SYCLomatic will flag this, and SYCL interoperability can be used as a temporary mitigation, while the SYCLomatic team and/or developer identifies a better approach.
Work Group Size and Data Access Latency
One aspect of GPU offload acceleration that is often underappreciated is the grouping of data accesses to minimize data movement between CPU and GPU as well as data transfers between GPU compute engines or tiles. When moving code from CUDA to SYCL with the intent of executing parts of it on different hardware, this means that often a second look is recommended to optimize
- Inefficient SYCL kernel use
- Data transfer grouping,
- Local memory use
- Work group sizing optimization
- Data access indexing
SYCLomatic provides you with some guidance, such as
- DPCT1049: The work-group size passed to the SYCL kernel may exceed the limit. To get the device limit, query info::device::max_work_group_size. Adjust the work-group size if needed.
- DPCT 1065: Consider replacing sycl::nd_item::barrier() with sycl::nd_item::barrier(sycl::access::fence_space::local_space) for better performance if there is no access to global memory.
In addition, it is recommended to consult advanced performance analysis utilities like the Intel® VTune™ Profiler or equivalent to get an idea where to focus.
Performance Portability
Following the guidance of the SYCLomatic tool and taking software framework differences into account, it is possible to achieve comparable performance with SYCL on a platform that natively would be using CUDA or HIP as offload programming approaches. Using select datasets from Velocity Bench, Figure 4 shows relative performance looking at the original CUDA code on its native hardware platform configuration against the SYCL code performance on the same setup.
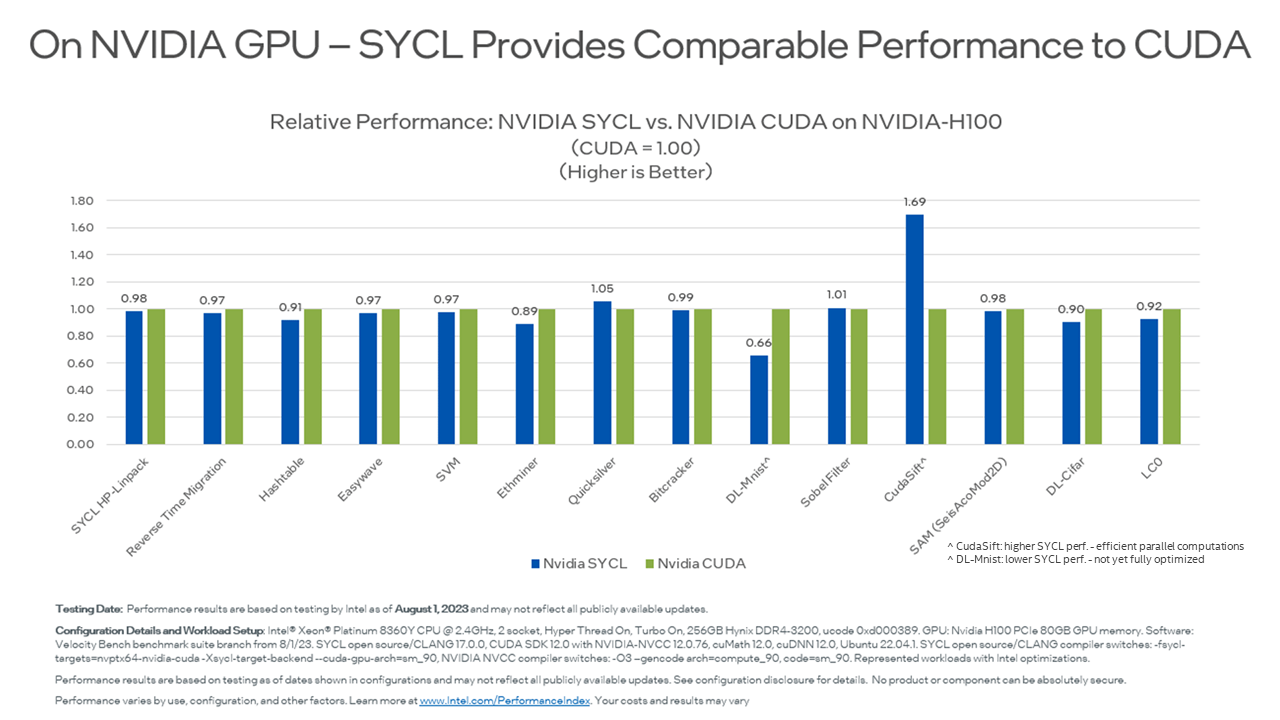
Figure 4: Relative Data Set Performance /w SYCL and CUDA
Conclusion
SYCLomatic evolves at a fast pace with ongoing updates to create ever more comprehensive tutorials for different use cases. Please contribute to the awesome list of oneAPI projects and catalog of applications ported using SYCLomatic. We are constantly adding new capabilities like additional migration rule templates and CodePin for debugging and verification of migrated SYCL projects.
Get The Software
Download oneAPI-powered Intel® DPC++ Compatibility Tool, the binary distribution equivalent of SYCLomatic, as a part of the Intel® oneAPI Base Toolkit.