Intel Gives Data Scientists the Performance and Ease-of-Use They Need
Andrey S. Morkovkin, machine-learning engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
The newest 3rd generation Intel® Xeon® Scalable processors enhance AI, cloud computing, security, and many other areas. Intel has optimized an array of software tools, libraries, and frameworks so that applications can take advantage of the latest hardware advances. The results are impressive. This blog focuses on the popular scikit-learn* machine learning library and Intel® Extension for Scikit-learn*.
A previous article demonstrated the performance leadership of the 2nd generation Intel Xeon Scalable processors over NVIDIA* and AMD* processors by changing just two lines of code. This article shows that Intel Extension for Scikit-learn delivers 1.09x to 1.63x speedup on the latest Intel Xeon Scalable processors over previous generations, a range of 0.65x to 7.23x speed-up compared to NVIDIA A100, and a range of 0.61x to 2.63x speed up compared to AMD EPYC* processors, codenamed Milan.
Intel® Extension for Scikit-learn*
This extension (previously known as daal4py) contains drop-in replacement functionality for the stock scikit-learn package. You can take advantage of its performance optimizations by adding just two lines of code before the usual scikit-learn imports:
from sklearnex import patch_sklearn
patch_sklearn()
f# the start of the user’s code
from sklearn.cluster import DBSCAN
…
Intel Extension for Scikit-learn is part of Intel® oneAPI AI Analytics Toolkit (AI Kit), which provides a consolidated package of Intel’s latest deep-learning and machine-learning optimizations. You can download it from several distribution channels: Docker* Container, YUM, APT, and Anaconda*. Alternatively, you can also download just the Intel Extension for Scikit-learn component using Python Package Index* (PyPI) or conda* Forge:
pip install scikit-learn-intelex
fconda install scikit-learn-intelex -c conda-forge
Intel Extension for Scikit-learn uses the Intel® oneAPI Data Analytics Library (oneDAL) to achieve its acceleration. The library enables all the latest vector instructions, such as Intel® Advanced Vector Extensions 512 (Intel® AVX-512). It also uses cache-friendly data blocking, fast BLAS operations with the Intel® oneAPI Math Kernel Library, and scalable multithreading with the Intel® oneAPI Threading Building Blocks.
Performance Leadership
Let's compare the performance of several machine learning algorithms in Intel Extension for Scikit-learn on 2nd and 3rd generation Intel Xeon Scalable processors and observed 1.09x to 1.63x speedups in training and inference.
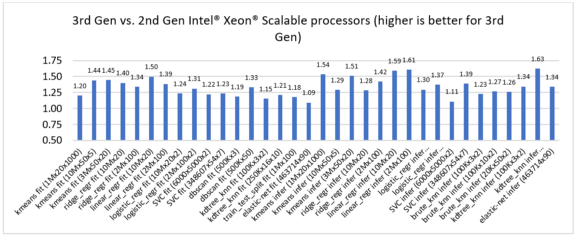
Figure 1. Performance improvement of 3rd generation Intel Xeon Scalable processors over 2nd generation Intel Xeon Scalable processors
To assess competitive performance, let's compare 3rd generation Intel Xeon Scalable processors to the latest NVIDIA A100 and AMD EPYC processors, codenamed Milan. The Intel Xeon Scalable processors demonstrated performance leadership across various machine-learning algorithms: 0.65x to 7.23x speedup compared to NVIDIA A100 (Figure 2) and 0.61x to 2.63x speedup compared to AMD Milan (Figure 3).
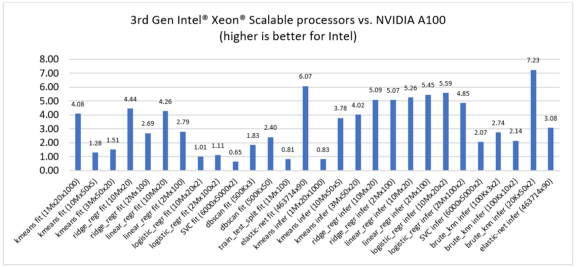
Figure 2. Speedup of 3rd generation Intel Xeon Scalable processors (using Intel Extension for Scikit-learn) over NVIDIA A100 (using RAPIDS cuML)
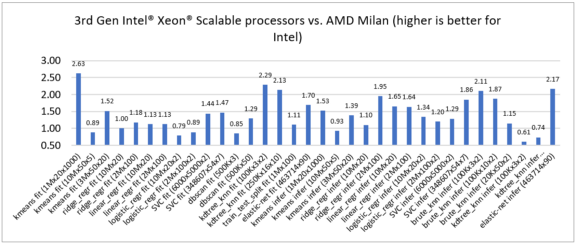
Figure 3. Speedup of 3rd generation Intel Xeon Scalable processors over AMD EPYC processors using Intel Extension for Scikit-learn on both processors
Intel’s Most Advanced Data Center Processor
The 3rd generation Intel Xeon Scalable processors feature a flexible architecture with built-in AI acceleration via Intel® Deep Learning Boost technology and a host of other enhancements:
- Faster memory: The number of memory channels per socket increased from six to eight, and the maximum frequency of memory increased from 2933 MHz to 3200 MHz. As a result, DRAM memory bandwidth increased up to 1.45x. Data analytics workloads are often DRAM-bound because many operations must be performed in-memory, so 3rd Generation Intel Xeon Scalable processors offer a significant improvement for these workloads.
- More cores: Top-bin 3rd generation Intel Xeon Scalable processors have 40 cores per socket, providing greater multithreaded data processing.
- Advanced microarchitecture: Instructions per cycle (IPC) improved from four to five, and the core of the new processor has ten execution ports instead of eight. In addition, new instructions were introduced to improve single-core performance, for example, Intel AVX-512 Bit Algorithms (BITALG), Intel AVX-512 Vector Byte Manipulation Instructions (VBMI2), and others.
- Larger caches: The Intel® Xeon® Platinum 8380 processor provides 60 MB of last-level cache (LLC), which is 56 percent more than the Intel® Xeon® Platinum 8280 L processor (38.5 MB). L2 cache increased from 1 MB to 1.25 MB per core, and L1 cache increased from 32 KB to 48 KB per core. Some machine-learning algorithms spend most of their time processing data residing in caches, so caching improvements can have a significant impact on performance.
- New level of security: Machine-learning algorithms often process confidential data, so new Intel Xeon Scalable processors provide hardware-based memory encryption with granular control via Intel® Software Guard Extensions (Intel® SGX).
The optimizations in Intel Extension for Scikit-learn plus the advanced capabilities of 3rd generation Intel Xeon Scalable processors deliver superior performance for machine learning and data analytics workloads. This allows you to run enterprise applications on a single architecture, optimizing total cost of ownership for mixed workloads and bringing innovative solutions to market faster.
Hardware and Software Benchmark Configurations
All configurations were tested by Intel.
| Platform | Model | Parameters | Testing date |
|---|---|---|---|
| 3rd generation Intel Xeon Scalable processors | 3rd generation Intel Xeon Platinum 8380 processor | 2 sockets, 40 cores per socket, Hyperthreading: on, |
3/19/2021 |
| 2nd generation Intel Xeon Scalable processors | 2nd generation Intel Xeon Platinum 8280L processor |
2 sockets, 28 cores per socket, Hyperthreading: on, |
2/5/2021 |
| AMD Milan | AMD EPYC 7763 | AMD EPYC 7763 64 cores: 2 sockets, 64 |
3/8/2021 |
| NVIDIA A100 | NVIDIA A100, AMD EPYC™ 7742 |
NVIDIA A100 Tensor (DGX-A100), AMD |
2/4/2021 |
| Software | CPU workloads | GPU workload |
|---|---|---|
| Python* | 3.7.9 | 3.7.9 |
| scikit-learn | Sklearn 0.24.1 | - |
| Intel Extension for Scikit-learn | 2021.2.2 | - |
| NVIDIA RAPIDS* | - | RAPIDS 0.17 |
| CUDA* Toolkit | - | CUDA 11.0.221 |