Story at a Glance
- Intel® Neural Compressor is an open-source Python* library for model compression that reduces the model size and increases the speed of deep learning inference for deployment on CPUs or GPUs.
- It provides unified interfaces across multiple deep learning frameworks for popular network compression technologies, such as quantization, pruning, knowledge distillation and neural architecture search.
- In this blog, we demonstrate how to use Intel Neural Compressor to distill and quantize a BERT-Mini model to accelerate inference while maintaining the accuracy.
- This example uses the SST-2 dataset, which is part of the General Language Understanding Evaluation benchmark set. Our distilled and quantized BERT-Mini model shows1:
- A 16.47x speedup over BERT-Base (PyTorch) while keeping similar accuracy.
- An 8.77x speedup over BERT-Base (ONNX Runtime) while keeping similar accuracy.
- An accuracy improvement of 6.9% on the SST-2 dataset over default BERT-Mini. This improvement is mostly due to GPT-2 data augmentation, which is planned for Intel Neural Compressor.
Orchestration of Compression Methods
Arbitrary, meaningful combinations of supported compression methods under one-shot or multi-shot are supported in Intel Neural Compressor. Such orchestration brings extra benefits in terms of accuracy and/or performance. Possible combinations could be distillation during pruning and quantization-aware training, or distillation and then post-training quantization.
Let’s look at each.
Distillation
Knowledge distillation (KD) from a large model to a much simpler architecture shows promising results for reducing model size and computational load while preserving much of the original model’s accuracy (Tang et al., 2019 and Wasserblat et al., 2020).
A typical KD setup has two stages (Figure 1). In the first stage, a large, cumbersome, and accurate teacher neural network for a specific downstream task is trained. In the second stage, a smaller and simpler student model is trained to mimic the behavior of the teacher. This model is easier to deploy in environments with limited resources. To simplify the system, we only use a single loss generated for each training batch by calculating the mean-squared error (MSE) distance between the target predictions produced by the student and teacher models.
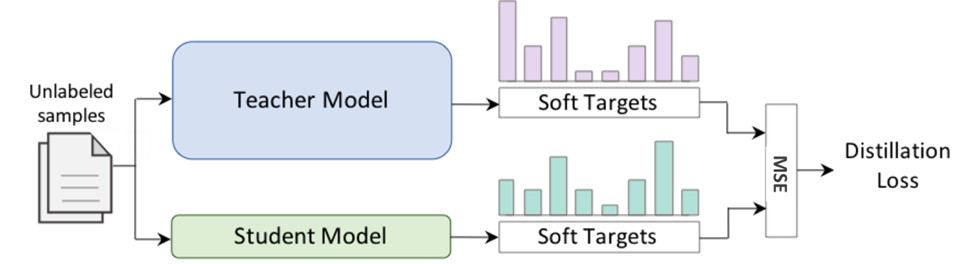
Figure 1. Flow of knowledge distillation
Quantization
Quantization is a widely used compression technique that can reduce model size while also improving inference and training latency. The full-precision model weights are converted to low-precision. The inference performance of the quantized model can improve, and do so with little degradation in model accuracy, by reducing memory bandwidth and accelerating computations with low-precision instructions.
Intel provides several lower-precision instructions (e.g., 8- or 16-bit multipliers) that benefit training and inference. Please see this article on lower numerical precision inference and training in deep learning for more details.
Example
The code snippets below show how to train a BERT-Mini model on the SST-2 dataset through distillation, and then leverage quantization to accelerate inference while maintaining accuracy using Intel Neural Compressor. The complete code is available in the BERT-Mini SST-2 notebook.
Distillation
from transformers import Trainer
import torch.nn.functional as F
class RegressionTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
loss = F.mse_loss(logits, labels)
return (loss, outputs) if return_outputs else loss
trainer = RegressionTrainer(
student_model,
args=training_args,
train_dataset=ds["train"],
eval_dataset=ds["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics_for_regression,
)
trainer.train()
trainer.save_model(model_output_dir)
Quantization
from neural_compressor.experimental import Quantization, common
os.environ["GLOG_minloglevel"] = "2"
model_input = "onnx_bert_mini/model.onnx"
model_output = "bert-mini_engine_int8"
quantizer = Quantization("bert-mini_engine_static.yaml")
quantizer.model = common.Model(model_input)
quantizer.eval_dataloader = common.DataLoader(DatasetForINC(ds["validation"], engine_order=True), 1)
quantizer.calib_dataloader = common.DataLoader(DatasetForINC(ds["validation"], engine_order=True), 1)
q_model = quantizer()
q_model.save(model_output)
Results
The example above first trains a BERT-Mini model on the SST-2 dataset through distillation to obtain comparable accuracy to BERT-Base. Next, it leverages quantization and the reference natural language processing (NLP) engine to improve the inference performance of the BERT-Mini model while maintaining its accuracy. The reference NLP engine is a framework for high-performance NLP model inference. This engine uses hardware and software optimizations to boost performance of extremely compressed NLP models:
- The baseline accuracy of BERT-Base on the SST-2 dataset is 94.0%. BERT-Mini using knowledge distillation is able to achieve 92.8% accuracy, which is an improvement over BERT-Mini without distillation (85.9%).
- With quantization and the reference NLP engine, BERT-Mini (Reference NLP Engine INT8) achieves a 16.47x speedup compared to BERT-Base (PyTorch FP32) — 1.04 vs. 17.13 millisecond latency — while maintaining comparable accuracy (92.8% vs. 94%).
- Even compared with the quantized BERT-Base (ONNX Runtime INT8), BERT-Mini still outperforms it with a 8.77x speedup (1.04 vs. 9.12 milliseconds) and maintains comparable accuracy (92.8% vs. 93.5%).
Future Work
We demonstrated how to use Intel Neural Compressor to optimize a BERT-Mini model on the SST-2 dataset through orchestration of distillation and quantization to accelerate inference while maintaining the accuracy. We will try incorporating the pruning approach to further accelerate this model’s inference in the future.
We invite users to explore this example and send us feedback through GitHub issues. We also encourage you to check out Intel’s other AI Tools and Framework optimizations and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio.
Get the Software
Intel® AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now
See All Tools