Using Intel Toolkit, Parallel Hierarchic Adaptive Stabilized Transient Analysis (PHASTA) was able to increase performance 3x on Intel® Data Center GPUs compared to 4th Gen Intel® Xeon® Scalable processor.
Introduction
PHASTA is a parallel computational fluid dynamics (CFD) analysis package that supports the simulation of complex physical flow systems on unstructured meshes using the stabilized finite element method. It is written in Fortran 90 and uses MPI to scale up to 1000s of CPU nodes. PHASTA uses the Portable, Extensible Toolkit for Scientific Computation (PETSc) for its solvers and OpenMP* for parallelization of the Equation Formation. PHASTA is part of Early Science Program (ESP), which aims to provide research teams with critical preproduction computing time and resources to prepare for the Aurora ExaScale Supercomputer. PHASTA has been used at Argonne’s Systems to measure Aerodynamic Flow Control and multiphase flow.
Flow past a commercial aircraft's vertical tail with flow separation over the rudder.
The Challenge
Aurora Supercomputer will provide cutting edge technology with Intel’s new Intel® Data Center GPU Max Series. Aurora supports two paradigms for programming GPUs: SYCL* and OpenMP Target. SYCL is a single-source language based on pure C++17 designed for applications written in C++, lending itself well to various domains. OpenMP Target is an API extension of OpenMP that supports offloading data and computation to the GPU for C++, C, and Fortran. Since PHASTA is written in Fortran, OpenMP Target is the paradigm that gives us the flexibility we need and will be used to offload computations and data to GPU. The main challenge is identifying which portions of the equation formation calculations and data need to be offloaded efficiently.
The Solution
Cross-architecture Intel® tools, which enable single-language and platform applications to be ported to (and optimized for) multiple single and heterogeneous architecture-based platforms, provide support to OpenMP Target in C, C++, and Fortran. At the same time, Intel tools include the Intel® VTune™ Profiler, a performance analysis tool for x86, as well as Intel® Iris® Xe graphics and Intel® Data Center GPUs.
Our first step is to run Intel VTune Profiler with the most optimized, most performant version of the PHASTA mini application that focuses on the main kernels that will use up to 80% of computation (element formation and residual calculation). The first run uses the CPU. This version uses OpenMP to thread over the main loops; these loops, in turn, call a deep stack. By using the -xCORE-AVX512 compilation flag, the compiler generates code that vectorizes the most inner loops down the call stack. We can see how well this version works by running the Intel VTune Profiler hot spots profile. At the same time, the Intel VTune Profiler hot spot analysis gives information on which subroutines are the most used and by how much compared to the rest of the code and the whole code stack.
Since the most used routines were already using OpenMP, we used OpenMP Target to offload those loops and their associated arrays. Our first try wasn’t performant compared to CPU, so we profiled it using Intel VTune Profiler gpu-hotspots to determine GPU occupancy, peak GPU occupancy, workgroup sizes, number of global items, and more.
After obtaining this information, we follow the recommendations from both Intel VTune Profiler User Guide and the Intel oneAPI GPU Optimization Guide based on the results provided by Intel VTune Profiler for fine-tuning our OpenMP Target loops.


Figure 1. An Intel VTune Profiler hot spots analysis on a CPU for a PHASTA Eq. formation
Using Intel VTune Profiler, we are able to see that the most important functions, the ones that take up most of the time, are as1imfg, as234gimfg, as5gimf, as1res, and as24ires. With this knowledge we know that most of the computation being run in those functions and the corresponding data needs to be offloaded or created on GPU.
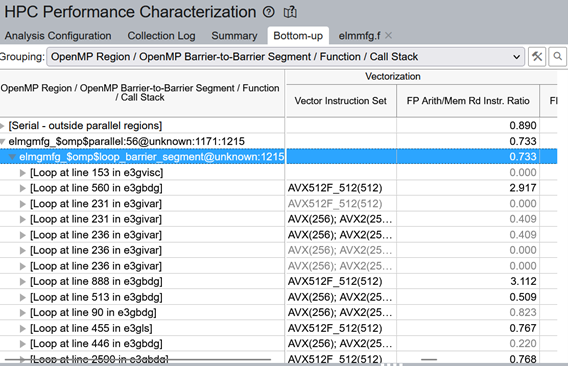
Figure 2. An Intel VTune Profiler HPC on a CPU analysis for a PHASTA Eq. formation
The application is vectorized on the CPU using Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions. Since the code is written in Fortran, we used OpenMP Target to offload both computations and data related to the functions. The baseline was the best threaded with the Intel AVX-512 version of the equation solver running on the 4th gen Intel® Xeon® Scalable processor with 52 cores. The figure of merit (FOM) is the millions of elements processed per second. The initial implementation, which we call Baseline GPU, used a !$omp declare target for the call stack, which in some cases was four levels deep.

Figure 3. Pseudo code for a GPU with OpenMP Target implementation using the !$omp declare target
"Intel VTune Profiler has been very helpful in determining hot spots in our OpenMP code, which have guided our team to code restructuring that has yielded substantial performance improvements."
Performance was 10x slower on Intel® Data Center GPU MAX SEries 1550. To dig deeper, we used Intel VTune Profiler to analyze the cause of this degradation. Occupancy in the loops that call the functions was very low, on average 13.2%.

Figure 4. Intel VTune Profiler analysis of GPU hot spots using the PHASTA Eq. formation GPU as a baseline
Our first optimization included collapsing the call stack to just one level, limiting the OpenMP Target num_teams to 10k and thread limit to 64, compiling code with large register mode, and using SIMD16. These optimizations work well when we have a large kernel running on GPU. By doing this optimization, we were able to increase performance; however, we were still 3.78x slower than the best CPU-threaded version.
Our second optimization consisted of collapsing all the call stack, eliminating the need to use the !$omp declare target since we no longer were calling any functions, thus bringing all computational loops to the main level.

Figure 5. Pseudo code for the PHASTA Eq. formation with no call stack
After running the Intel VTune Profiler gpu-hotspots, we saw that occupancy was now 66.4% on average.

Figure 6. Intel VTune Profiler analysis of GPU hot spots using a PHASTA Eq. formation with no callstack
By doing this, performance improved by was still 0.2x slower than the baseline.
Our final optimization consisted of removing the coloring scheme used to prevent the use of atomics. By removing the coloring and adding atomics to assembly loops, we obtained 3.1x better performance than the baseline.
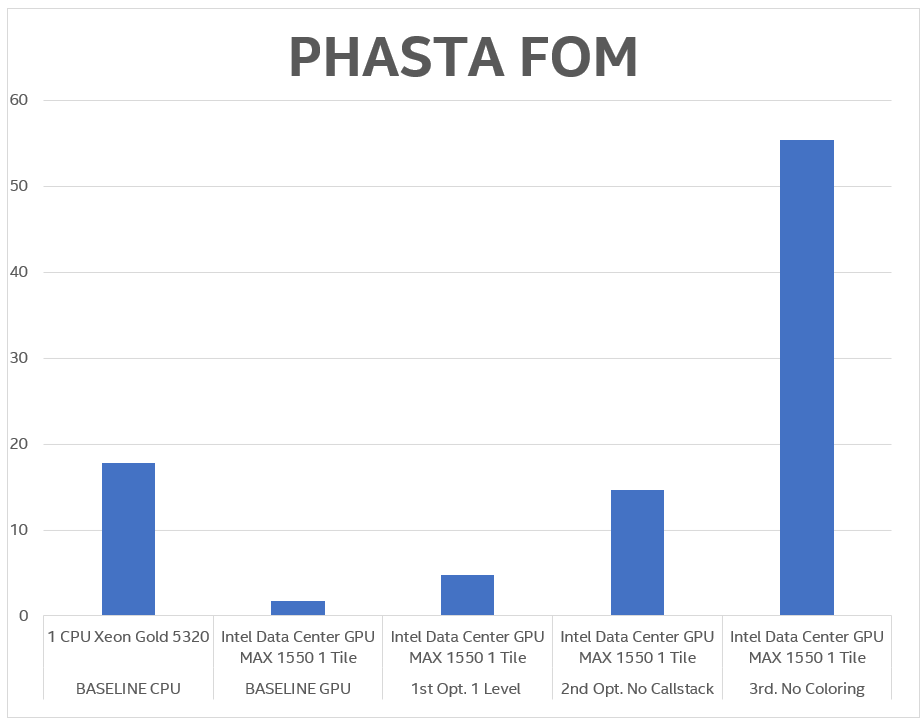
Figure 7. PHASTA benchmark
Conclusion
OpenMP Target allowed Fortran code to use state-of-the-art GPUs along with all the tools that more modern languages use. However, the process to port CPU applications to GPU might need fine-tuning. We saw with PHASTA that just using OpenMP Target in previous loops that were using classic OpenMP was not enough. Only after careful analysis provided by Intel VTune Profiler and understanding of the capacities of our GPU, we were able to obtain good performance improvement. After obtaining good performance on equation formation from PHASTA, the PHASTA team is focusing on the Equation Solver, analyzing and testing both PETSc and PHASTA internal solvers.
Notes and Disclaimers
10% to up to 25% rendering efficiency with thousands of hours saved in rendering production time. Fifteen hours per frame per shot to 12-13 hours.
Cinesite Configuration: 18-core Intel Xeon Scalable processors (W-2295) used in a render farm, 2nd gen Intel Xeon processor-based workstations (W-2135 and -2195) used. Rendering tools: Gaffer, Arnold, along with optimizations by Intel® Open Image Denoise.
Intel technologies may require enabled hardware, software, or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.