Portability across Heterogeneous Architectures
Nitya Hariharan, application engineer, and Rama Kishan Malladi, performance modeling engineer, Intel Corporation @IntelDevTools
Get the Latest on All Things CODE
Sign Up
The OpenMP* standard has supported accelerator offload since version 4.0. These directives enable you to offload data and computation to devices like GPUs. This makes it easier to write portable, heterogeneous parallel code. In this article, we discuss some of the OpenMP offload directives and show how they are used with code samples. We also show some examples of porting OpenACC* to OpenMP.
Port OpenACC* to OpenMP
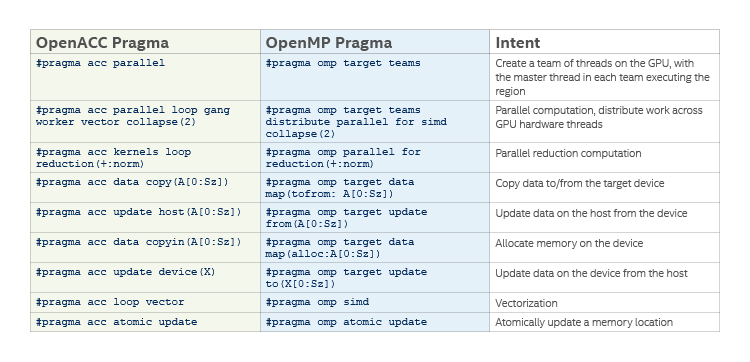
OpenACC is the directive-based programming method for NVIDIA* GPUs, but lack of support from other vendors limits it to one platform. Conversely, OpenMP offload has broader industry support: the oneAPI framework, the NVIDIA HPC SDK, the AMD ROCm* stack, and the IBM XL compiler* suite. There is nearly a 1:1 mapping of OpenACC directives to OpenMP (Table 1), so porting legacy OpenACC code to OpenMP is usually straightforward. Table 1 shows some commonly used OpenACC pragmas and their OpenMP equivalents.
Table 1. Common OpenACC pragmas and their OpenMP equivalents.
Figures 1a and 1b show a code snippet ported from OpenACC to OpenMP. This is a kernel from a radio astronomy package tConvolveACC. The OpenACC directive, #pragma acc parallel loop, is replaced with the OpenMP offload directive, #pragma omp target parallel for, plus explicit data transfer directives to and from the target device. The OpenACC implementation possibly used an implicit copy or unified shared memory allocation to manage the data transfer.

Figure 1a. The sample kernel from tConvolveACC is implemented in OpenACC.

Figure 1b. A sample kernel from tConvolveACC is implemented in OpenMP.
OpenMP Offload on Intel® Platforms
Let's look at the steps required to build and run the offload code. We tested our OpenMP offload code with the 2021.2.0 version of the Intel® oneAPI Base Toolkit using the following compiler flags:

The -fiopenmp and -fopenmp-targets=spir64 flags are two new options that tell the compiler to generate a fat binary for the GPU. The -vpo-paropt-enable-64bit-opencl-atomics=true compiler option enables atomic and reduction operations. For more details, see the documentation.
Set the OMP_TARGET_OFFLOAD environment variable to run OpenMP offload code on the GPU. (A runtime error appears if the GPU is unavailable.) You can also choose between the Level Zero or OpenCL™ standard back ends:

The LIBOMPTARGET_DEBUG environment variable can be set to one or higher to obtain debugging information for a GPU offload. In Figure 2a, we highlight the debug information from the tConvolveACC OpenMP offload kernel when run with the Level Zero plug-in. The two offload regions are in functions gridKernelACC and degridKernelACC, which belong to a class named Benchmark. Figure 2b shows the map clause transferring the variable to the target device. Figure 2c shows the data being transferred from the host to the target device. Once all the data required for the computation is present on the device, the kernel runs as shown at the bottom of Figure 2a.

Figure 2a. Class and function information for the tConvolveACC OpenMP offload kernel is highlighted in red.

Figure 2b. Variable information for the tConvolveACC OpenMP offload kernel is highlighted in blue.

Figure 2c. Data transfer information for the tConvolveACC OpenMP offload kernel is highlighted in green.
Map OpenMP Threads to the Target Device
At runtime, the OpenMP thread hierarchy is mapped to the target device. The #pragma omp teams construct creates a league of teams, and the initial thread in each team runs the region. The #pragma omp distribute clause distributes the work across the initial threads in the teams, with each team scheduled on a subslice (on Intel® GPUs). Further parallelization of work within each team is done with the parallel for clause, with the threads in a team mapped onto the execution unit (EU) threads. Finally, the #pragma omp simd clause uses the EU vector lanes to run vectorized code. Threads within a team synchronize at the end of a work sharing construct. This is illustrated for Intel® Processor Graphics (9th generation), which has:
- One slice
- Three subslices
- Eight EUs per subslice
- Seven threads per EU
- Single Instruction Multiple Data (SIMD) vector processing units in each EU
See Figure 3 for details. Mapping of OpenMP offload pragmas to these respective units on 9th generation Intel Processor Graphics is also shown.
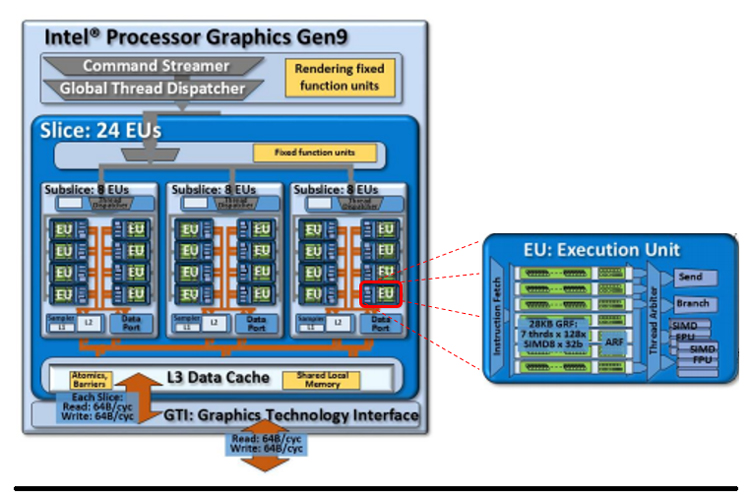
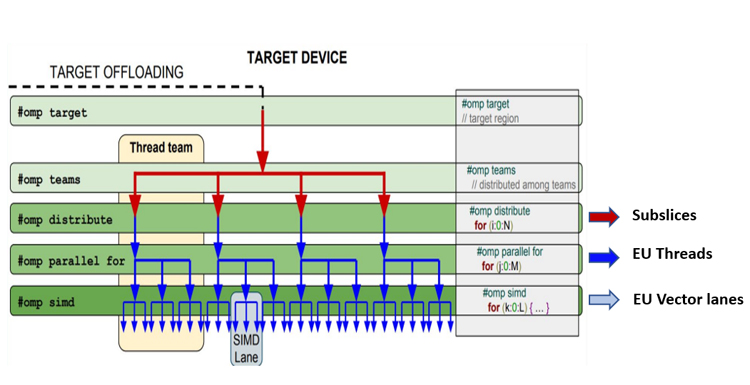
Figure 3. Mapping OpenMP offload to hardware features on 9th generation Intel Processor Graphics (adapted from OpenMP Offloading Verification and Validation: Workflow and Road to 5.0)
OpenMP Directives for Better Data Transfer to and from the Target Device
Having built an application and successfully offloaded some of the kernels to the target, the next step is to explore optimization opportunities, such as data transfer. OpenMP has directives to implement efficient data transfer between host and target. The following image is an example of tHogbomCleanACC, which has two offload targets in the HogbomClean function. A naïve OpenMP offload results in a data transfer during both target invocations. The problem gets worse if this is repeated in a loop for g_niters, as shown in the code snippet (Figure 4a).

Figure 4a. Naïve implementation of two OpenMP offload kernels resulting in unnecessary data transfers.
Figure 4b shows an optimized implementation of HogbomClean function that performs a more efficient data transfer. The #pragma omp target data map statement defines the scope for the data to be persistent on the target. Any kernel offload within this scope can reuse the data (with the handle). Subsequent map calls to the offloaded kernel do not require data transfers (except for the ones that are explicitly marked for transfer).
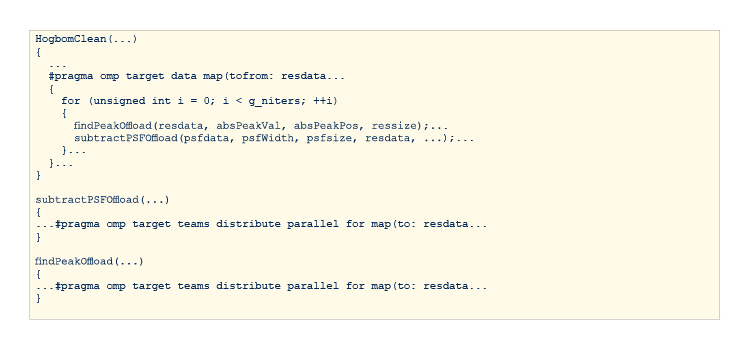
Figure 4b. An OpenMP orphaning example with a more efficient copy for a once and reuse data transfer.
Enhanced Support for Variant Function Dispatch
The OpenMP offload specification supports function variants that can be conditionally invoked instead of the base function. The implementation of this OpenMP offload function with a variant API from Intel is supported using a #pragma omp target variant dispatch. This directive tells the compiler to emit a conditional dispatch code around the function call. If the target device is available, the function variant is invoked instead of the base function. Figures 5a, 5b, and 5c show an example of the target variant dispatch API. Note that the function variant must have the same arguments as the base function, plus an additional last argument of type void *.

Figure 5a. The function variant, findPeakOffload, runs on the target device.
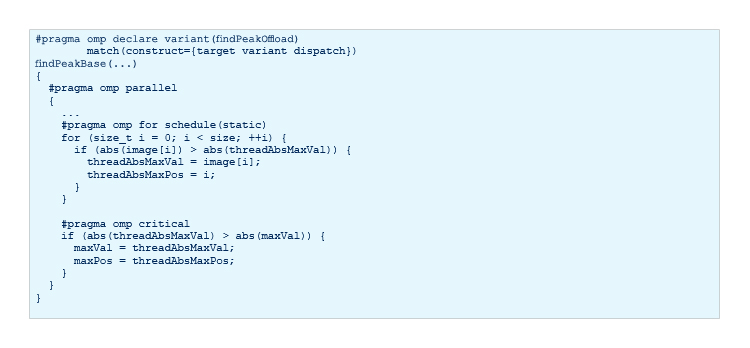
Figure 5b. The base function, findPeak, runs on the host.

Figure 5c. Invocation needs to be the host version. The offload target function runs if the target device is present, and the host version runs.
Conclusion
The platform- and vendor-agnostic device offload support provided by the OpenMP standard makes it easier to target multiple heterogeneous architectures using the same code base. Therefore, we expect increasing adoption of OpenMP heterogeneous parallelism among users, and hardware and software vendors.
______
You May Also Like
Use OpenMP Accelerator Offload for Programming Heterogeneous Architectures
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.
Get It Now
See All Tools