In the three months since our last update release of Intel® oneAPI Base Toolkit, Intel® oneAPI HPC Toolkit, and Intel® AI Tools, we have added many feature extensions to their components. The main focus this time was again driving toward an ever more complete, easy-to-use, and comprehensive set of capabilities and interoperability for advanced multiarchitecture parallelism in HPC and AI, driving optimized performance and productivity for AI, graphics, and accelerated compute.
New Release Highlights
Some of the standout innovations in this newest release are
- More efficient parallel algorithm programming, coding options, and performance using Intel® oneAPI DPC++ Library (oneDPL) expanded range-based APIs, which align with the upcoming C++26 standard.
- The ability to leverage the combined power of multiple GPUs for 2D and 3D non-batch FFTs using the new SYCL DFT API in Intel® oneAPI Math Kernel Library (oneMKL).
- Increased productivity and debugging efficiency in Visual Studio* for gaming and complex simulation developers with advanced thread filtering, focusing on active threads, and simplifying error management. Furthermore, the latest Intel® Distribution for GDB* features the ability to set breakpoints on GPU kernels written in assembly from various inferiors, ideal for highly parallel matrix-multiply kernel offload to GPU, as present in many AI and simulation workloads.
- Improved cross-platform compatibility, performance, and efficiency with the Intel® oneAPI DPC++/C++ Compiler's enhanced SYCL* interoperability with Vulkan* and DirectX* graphics APIs, benefiting applications like rendering and data visualization, among many others.
The Intel oneAPI HPC Toolkit ensures productivity, performance, and robust memory usage with additional enhanced Intel® Fortran Compiler LLVM* MemorySanitizer support for device code on Intel® Data Center GPUs.
It continues to evolve, staying on the leading edge of implementing the latest C++ 26, OpenMP* 6.0, Fortran 2023, and MPI 4.1 features, as well as ensuring the ability for MPI, SYCL, and OpenMP to coexist seamlessly for parallelism in hierarchical distributed computing.
Regarding Fortran 2023 and OpenMP 6.0 specifically,
- The Intel Fortran Compiler adds the Fortran 2023 Selected_Logical_KIND intrinsic for advanced logical type handling and support for allocatable arrays of coarrays, perfect for optimizing parallel computing and complex data structures in scientific applications.
- Developers gain more flexible control over the offload execution flow with OpenMP 6.0's new stripe loop-transformation construct and the nowait clause's optional Boolean argument to conditionally choose between asynchronous or synchronous offloading in the Intel® oneAPI DPC++/C++ Compiler and Fortran Compiler.
You can find a brief news update listing of the key feature improvements at this link:
⇒ Intel® Software Developer Tools 2025.2: Driving Performance and Productivity for AI, Graphics, and Accelerated Compute.
Of course, all of the development tool components continue to expand their coverage for the latest and upcoming generations of Intel® Xeon® processors, Intel® Core™ processors, and Intel® Arc™ Graphics. This, among other things, includes the Intel® VTune™ Profiler adding platform awareness to its catalog of performance analysis capabilities for the new single-socket Intel® Xeon® 6 SoC (code-named Granite Rapids-D), a compact form-factor Intel Xeon processor package popular, for example, for use in high-bandwidth industrial gateways and in-flight aviation control systems.
Scalable Parallelism Interoperability
Among the features introduced in the Intel® Compilers are early implementations of proposed extensions to SYCL and OpenMP.
SYCL Joint Matrix Extension API
The experimental SYCL namespace sycl::ext::oneAPI::experimental::matrix defines a new data type used for joint matrix operations:
using namespace sycl::ext::intel::experimental::matrix;
template <typename Group, typename T, use Use, size_t Rows,
size_t Cols, layout Layout = layout::dynamic>
struct joint_matrix;
enum class use { a, b, accumulator};
enum class layout {row_major, col_major, dynamic};
The typical memory load, store, and pointer operations can be applied for entire SYCL work groups, and data can be prefetched for streamlined execution. Pointers can be overloaded.
void joint_matrix_mad(Group g, joint_matrix<>&D,
joint_matrix<>&A, joint_matrix<>&B, joint_matrix<>&C);
void joint_matrix_apply(Group g, joint_matrix<>&jm, F&& func);
void joint_matrix_apply(Group g,
joint_matrix<>& jm0, joint_matrix<>& jm1, F&& func);
void joint_matrix_copy(Group g, joint_matrix<Group, T1, Use1,
Rows, Cols, Layout1> &dest,
joint_matrix<Group, T2, Use2, Rows, Cols, Layout2> &src);
Matrix multiply and add (D=A*B+C) supports all the essentials, like per-element operations, activation functions, (de-)quantization, and matrix copy with data type conversion.
void joint_matrix_fill(Group g, joint_matrix<>&dst, T v);
void joint_matrix_load(Group g, joint_matrix<>&dst,
multi_ptr<> src, size_t stride, Layout layout);
void joint_matrix_load(Group g, joint_matrix<>&dst,
multi_ptr<> src, size_t stride);
void joint_matrix_store(Group g, joint_matrix<>src,
multi_ptr<> dst, unsigned stride, Layout layout);
void joint_matrix_prefetch(Group g, T* ptr, size_t
stride, layout Layout, Properties properties);
The vision and net effect will be that using SYCL matrices and tensors can more efficiently represent and manipulate the properties of computational objects, accelerating a wide range of computations like simulations, advanced numerical differential equations, visual computing, CGI VFX, financial risk analysis, gaming, and AI; all with a unified interface for matrix and tensor operations compatible with SPIR-V* cooperative matrix extensions.
This architecture makes unified joint matrices inherently scalable and portable across different platforms and architectures.
Find out more about unified joint matrix SYCL extensions in the following article:
⇒ IXPUG Take-Out: Unified Joint Matrix SYCL* Extension
Enhanced OpenMP Composability
OpenMP is designed to offer a portable, scalable model that gives programmers a flexible interface for developing parallel applications for platforms ranging from laptops to supercomputers.
Key features to facilitate this include:
- directives-based parallelism, which feels very natural for any C or Fortran developer.
- shared memory model, with the only limitation of the shared memory domain being what the operating system supports.
- task and loop parallelism, making it easy to introduce parallelism to preexisting code.
- device offloading for acceleration and custom routine execution.
- portability across architectures and compilers, due to OpenMP’s open standard approach.
Consider an environment with multiple sockets, multiple offload software programming models, and probably even different NUMA domains. The memory architecture is getting more complex, with FPGAs, custom accelerators, chiplets, and GPUs all gaining popularity and entering the fray.
Our composability approach facilitates the coexistence of SYCL libraries, OpenMP, and MPI with minimal changes. Of course, like any multi-layered high-performance computing stack, additional complexity implies additional performance tuning requirements. Yet the concept is very straightforward, as seen in Figure 1.
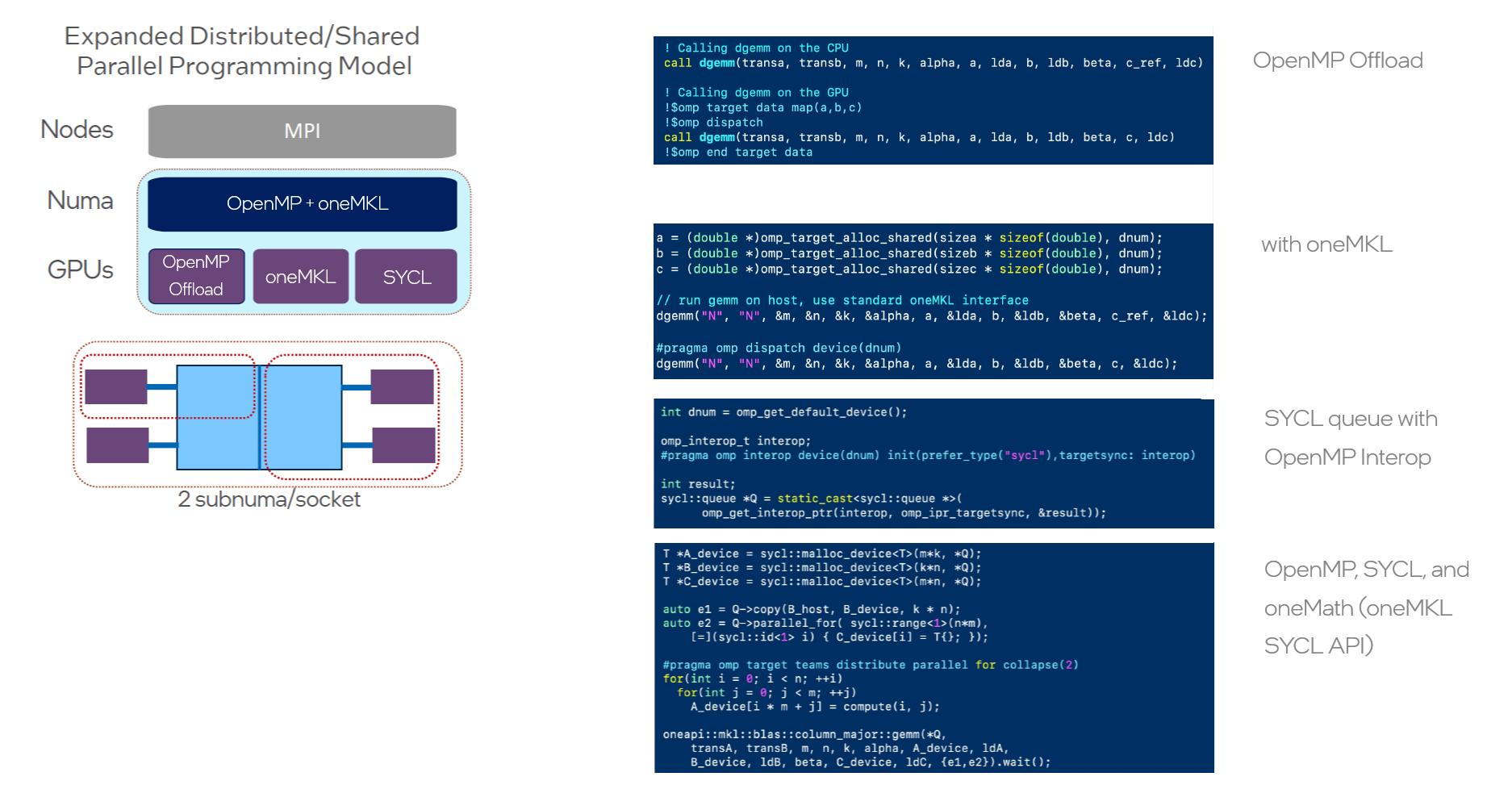
Figure 1: Scaling OpenMP Composability
Find out more about OpenMP Composability in the following article:
⇒ OpenMP and the Future of Scientific Computing
Virtual Functions in SYCL
Virtual functions have been a standard staple of modern C++ software development since the language’s inception. Common backend abstractions like the Kokkos* C++ performance portability interface, widely used in high-performance scientific computing, rely on it.
The SYCL specification one-definition rule (ODR) use of virtual inheritance can be a bit limiting, though, as virtual member functions cannot be called within a device function, leading to complications when porting some code bases to SYCL.
We tackle this by introducing a oneAPI kernel property extension that introduces an indirectly_callable property, declaring a virtual function to be a special device function with all its restrictions.

Figure 2: Basic virtual class inheritance setup with oneAPI kernel property extension
If you want to try virtual functions with SYCL and learn more, check out the following article and presentation recording:
⇒ Dimensions of SYCL* Expansion: C++ Virtual Functions and SPIR-V* Backend.
Following Intel’s committed support for the open source community, our compiler developers are actively engaged contributors to these and other leading-edge software development framework discussions, whether it is parallel programming methods like OpenMP, SYCL, and MPI, backend definitions like SPIR-V, compiler frameworks like LLVM, or AI frameworks like TensorFlow* and PyTorch*.
Accelerated Image Processing and Visualization
Image processing and visual computing are key ingredients in many accelerated computing, gaming, and CGI VFX workloads.
To that end, we enhanced cross-platform compatibility, performance, and efficiency with the Intel® oneAPI DPC++/C++ Compiler's enhanced SYCL interoperability with Vulkan* and DirectX* graphics APIs, adding full awareness of these enhancements to the Intel® DPC++ Compatibility Tool and thus to the process of migrating CUDA* GPU offload code to open-standards cross- and multi-architecture SYCL code as well. The Intel® DPC++ Compatibility Tool now automatically migrates an additional 357 APIs used by popular AI and accelerated computing apps.
Bindless images expand on image support in the SYCL 2020 standard by adding control over how images are stored on a device and which memory access model (e.g., unified shared memory (USM), buffer accessors, device-optimized memory layout, imported memory) is used. This goes beyond accessor-based memory access requests and supports runtime image rendering, mipmaps, cube maps, image arrays, and more.
Being able to copy and reinterpret image data through flexible auxiliary copy functions rounds out the picture.
This allows for minimizing the amount of data that has to be transferred back and forth between CPU host processes and accelerator devices.
In short, the execution flow changes from Figure 3
![]()
Figure 3: Data Transfer between Host and Device without Interoperability
to something simpler and considerably more resource-efficient:
![]()
Figure 4: Data Transfer between Host and Device with Interoperability
We eliminate 2 extra copy steps, reusing the same memory allocation within the SYCL and Vulkan or DirectX 12 context, by introducing an API for importing external memory into the SYCL image processing framework.
Find out more about SYCL interoperability with DirectX and Vukan in the following article:
⇒ SYCL* Interoperability with DirectX* and Vulkan* for Bindless Image Memory
Performance through Library Parallelism
Scalable multi-architecture parallelism is not just about advanced parallel programming concept support in popular languages and language extensions. It is also about having a rich ecosystem of optimized performance libraries that can directly benefit from both language extensions and underlying hardware features.
The Intel® Integrated Performance Primitives accelerate high-precision image processing on AVX-512 equipped Intel® CPUs by allowing faster manipulation and alignment of 32-bit floating point images when using Intel® Integrated Performance Primitives (IPP) Warp Perspective functions with Nearest Interpolation or OpenCV*.
In addition to image processing, signal processing also benefits from a significant performance boost for 16-bit data on AVX2 and AVX512 capable CPUs.
Taking cross-architecture parallel execution for Fast Fourier Transforms (FFTs) to the next level, the Intel® oneAPI Math Kernel Library (oneMKL), now enables you to conveniently access the combined power of multiple GPUs for 2D and 3D non-batch FFTs using the new SYCL DFT API.
Multiple GPUs attached to a CPU in a distributed multi-node cluster is a common platform configuration in HPC, which brings us back to the OpenMP Composability with SYCL and MPI discussed earlier.
You can now gain flexible control over offloading processes with OpenMP 6.0's new stripe loop-transformation construct and the nowait clause's optional Boolean argument to choose between asynchronous or synchronous offloading in the Intel®Compilers conditionally.
Intel® MPI Library users have access to
- enhanced control over provider initialization with a new capability to set a list for I_MPI_OFI_PROVIDER.
- full MPI 4.1 functionality with ongoing updates to ensure future stability, portability, and compatibility with updates to MPI 4.1
- better resource utilization and performance with newly extended multi-threading capabilities for the full suite of collective operations, improvements to device-initiated RMA interoperability and performance.
This results in scalable parallelism, from a laptop using only a CPU, all the way to exascale supercomputers for HPC and AI.
Supercharge AI on CPU and GPU
Talking about AI, we have also added more optimizations to Intel’s contributions to PyTorch, as well as the Intel® oneAPI Deep Neural Network Library (oneDNN).
oneDNN’s latest optimizations for Intel® Core™ Ultra Series 2 processors, Intel® Xeon® 6 processors with P-cores, and Intel® Arc™ GPUs are upstreamed to the PyTorch 2.7 release, and supercharge popular AI inference workflows such as BERT, Llama, and GPT on Intel Xeon 6 processors as well.
The VTune Profiler allows you to streamline and optimize AI performance on Intel client GPUs and NPUs with new analysis tool features and achieve faster performance of DirectML-based AI applications.
Find out more about how Intel helps accelerate PyTorch-based AI applications with this blog:
⇒ Accelerate PyTorch 2.7 on Intel® GPUs
and these videos:
⇒ Deploy Compiled PyTorch Models on Intel GPUs with AOTInductor
⇒ PyTorch Export Quantization with Intel GPUs
Take Charge of Your Parallel Code
Scale, optimize, and streamline the execution of any workload through comprehensive, highly integrated parallelism, regardless of whether you run on an AI PC or a supercomputer. One developer solution for AI, HPC, and imaging through seamless interoperability between MPI, OpenMP, SYCL, PyTorch, Vulkan, DirectX, and more.
Download the latest developer tools in version 2025.2 today:
- AI Tools and Frameworks
- Intel® Distribution for Python*
- Intel® oneAPI Base Toolkit
- Intel® oneAPI HPC Toolkit
Additional Resources
News Update
Accelerated Computing
- OpenMP* and the Future of Scientific Computing
- Deepen the Understanding of Light-Matter Interaction Dynamics (oneMKL and mixed precision in HPC)
- Unified Joint Matrix SYCL* Extension
- Dimensions of SYCL* Expansion: C++ Virtual Functions and SPIR-V* Backend
- SYCL* Interoperability with DirectX* and Vulkan* for Bindless Image Memory
Artificial Intelligence and Machine Learning
- Accelerate PyTorch 2.7 on Intel® GPUs
- Deploy Compiled PyTorch Models on Intel GPUs with AOTInductor
- PyTorch Export Quantization with Intel GPUs