At Intel Extreme Performance Users Group’s (IXPUG) Annual Conference 2025, Ye Luo of Argonne Leadership Computing Facility, Argonne National Laboratory and Jeongnim Kim of Intel Corporation presented "OpenMP in oneAPI: Empowering Scientific Computing on Intel Platforms, From Laptop to Aurora Exascale Supercomputer", covering the important role the OpenMP parallel programming model plays not just in existing workloads, but also for the future of accelerated offload computing on all types of hierarchical heterogeneous platforms. Intel® Core™ processors, Intel® Xeon® processors, and other CPUs can handle what they are best at, while specialized accelerators and GPUs can assist with highly parallelizable compute or signal processing tasks, and the coordination of the different parallel computational streams is efficiently coordinated using OpenMP.
In this article, we will briefly summarize the main points made at the conference, encouraging you to replay the full video for additional deeper insights.

⇒ Dive deeper into the topic, and replay the presentation "OpenMP in oneAPI: Empowering Scientific Computing on Intel Platforms, From Laptop to Aurora Exascale Supercomputer", from the Intel Extreme Performance Users Group’s (IXPUG) Annual Conference 2025 at the Texas Advanced Computing Center (TACC)
⇒ Slides are also available online.
OpenMP Parallel Programming Model
To quickly recap, OpenMP’s mission. It is designed to offer a portable, scalable model that gives programmers a flexible interface for developing parallel applications for platforms ranging from laptops to supercomputers.
Key features to facilitate this include:
- directives-based parallelism, which feels very natural for any C or Fortran developer.
- shared memory model, with the only limitation of the shared memory domain being what the operating system supports.
- task and loop parallelism, making it easy to introduce parallelism to preexisting code.
- device offloading for acceleration and custom routine execution.
- portability across architectures and compilers, due to OpenMP’s open standard approach.
A typical simple parallel offload routine computing a vector-scalar product and adding the result to a vector would look something like this:
void axpy(const float *a, const float *b, float *c, int n)
{
#pragma omp target teams distribute parallel for \
map(to:a[0:n],b[0:n]) map(from:c[0:n])
for (int id=0; id < n; id++)
{
c[id] = a[id] + b[id];
}
}
// …
float a[64]={1}. B[64]={2}, c[64];
axpy(a,b,c,64);
OpenMP has come a long way since its inception in 1997 (Fortran) and 2002 (C/C++), and the addition of the target offload construct with OpenMP 4.5 in 2015.
[7min 25sec] into the presentation, Yeongmin Kim proceeds to list the key additions to the OpenMP specification in recent years (Figure 1)

Figure 1: Recent additions to the OpenMP specification
For a detailed discussion of these additions, check out the following press releases on the OpenMP webpage:
⇒ OpenMP 5.0 is a Major Leap Forward
⇒ OpenMP® ARB Releases OpenMP 6.0 for Easier Programming
The Intel® oneAPI DPC++/C++ Compiler and Intel® Fortran Compiler stay at the forefront of support for the newest OpenMP features. The developer team behind those compilers actively contributes to the OpenMP standard and its implementation in LLVM*-compatible open source compilers.
For the latest information about OpenMP support in Intel® Compilers, check out the
⇒ Intel® Software News Updates and the article
⇒ Advanced OpenMP* Device Offload with Intel® Compilers,
discussing OpenMP implementation support in the 2025.x compiler generation.
Enhanced OpenMP Composability
One addition specifically in the Intel Compilers is very relevant for scientific compute and hierarchical heterogeneous multi-node compute composability across different distributed computing and GPU accelerator offload frameworks.
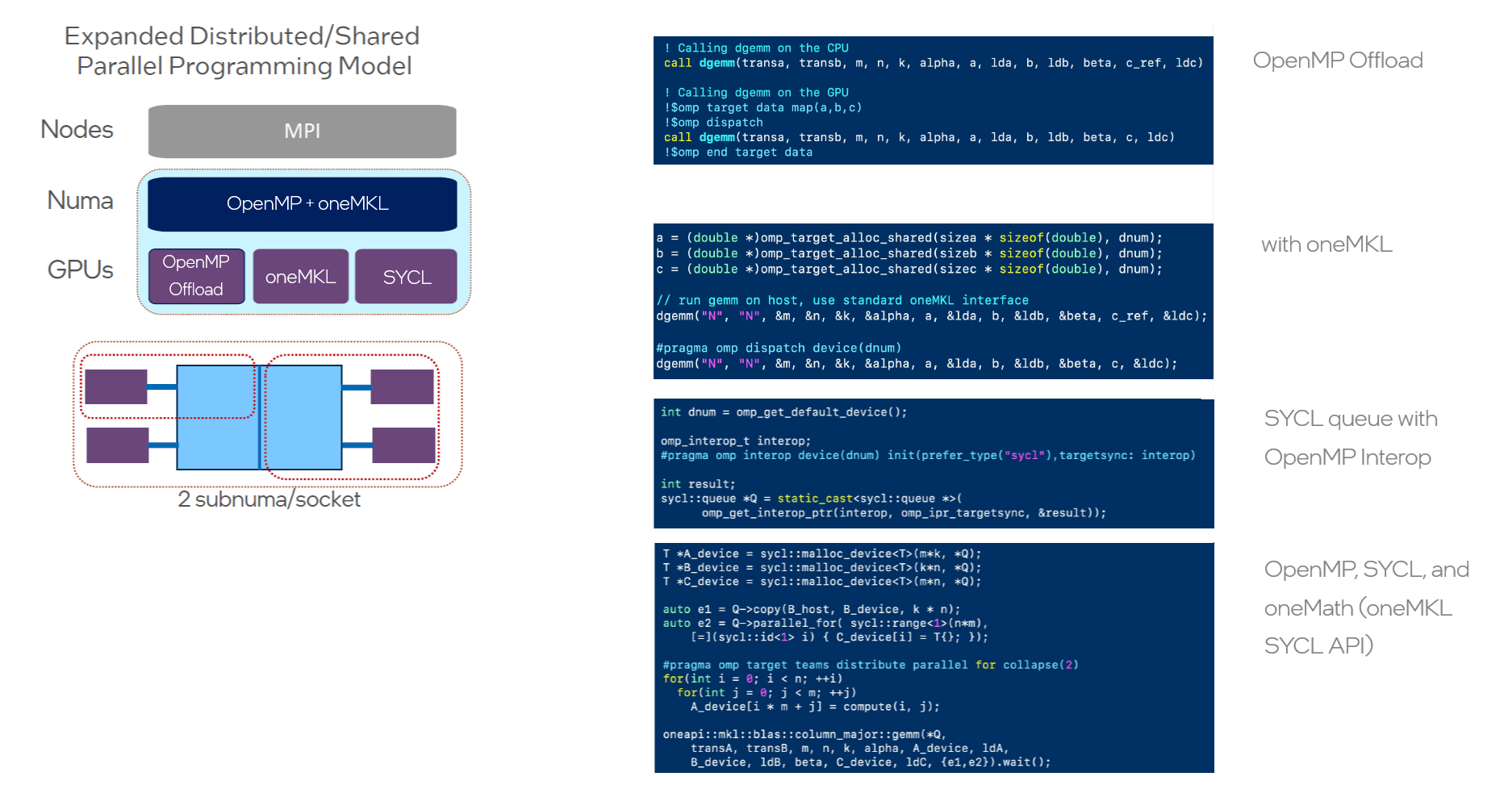
Figure 2: OpenMP Multi-API Composability
Consider an environment with multiple sockets, multiple offload software programming models, and probably even different NUMA domains. The memory architecture is getting more complex, with FPGAs, custom accelerators, chiplets, and GPUs all gaining popularity and entering the fray.
Jeongnim Kim discusses how enhanced openMP composability in the Intel® oneAPI Toolkits assists with this type of advanced compute architecture next [11 min] into her talk.
Figure 2 uses an example gemm code using OpenMP offload calls with oneMKL C API alongside a SYCL queue calling the oneMath SYCL API, all in perfect coordination. It illustrates the core principle behind this level of composability, where performance libraries (e.g., Intel® oneAPI Math Kernel Library, Intel® oneAPI Collective Communications Library), as well as SYCL user kernels, MPI nodes, and even Python* calls, can all coexist and collaborate.
The composability approach facilitates the use of SYCL libraries together with OpenMP and MPI with minimal changes. It has been integrated into the OpenMP backend of multi-platform scientific compute frameworks like Kokkos*, and any programming model that uses C/C++ binding. Of course, like any multi-layered high-performance computing stack, additional complexity implies additional performance tuning requirements.
There are multiple applications and scientific workloads, where this is already happening, such as GAMESS*, VASP*, BerkeleyGW*, and ThunderSVM*.
QMCPACK OpenMP Portability Case Study
QMCPACK*, a modern, high-performance open-source Quantum Monte Carlo (QMC) simulation focused on electronic structure calculations, employs enhanced OpenMP composability exactly in the way just discussed by using MPI, OpenMP, SYCL, and oneMKL together, efficiently managing computational availability across nodes and GPUs.
[19 min] into the talk, Ye Luo goes into more detail on the benefits of OpenMP portability assisted by oneAPI for QMCPACK. He points out how the flexibility it provides helps with running its simulation workloads not just on Aurora but also with moving code from other supercomputers at Argonne Leadership Computing Facility (ALCF), Argonne National Laboratory, with relative ease.
Enhanced OpenMP composability with oneAPI makes QMCPACK portable across all Department of Energy (DOE) funded Exascale Computing Project (ECP) platforms.
He highlights how performance is consistent, and with some diligence and awareness of data movement between compute units, it is very straightforward to maintain not just functional portability, but also performance portability for compute kernels targeting a mixed SYCL and OpenMP environment. This allows QMCPACK to have access to and unleash the compute power for his teams’ science needs.
Ever More Parallel Compute with OpenMP
OpenMP continues to be a robust, multi-vendor, multi-platform, multi-base language programming framework for accelerated computing. OpenMP’s approach is open and standards-based so that vendors can offer their own implementation with optimized performance for the underlying hardware.
Application developers can write highly portable and performant codes that achieve the near-best GPU hardware potential by implementing these high-level OpenMP programming concepts and techniques. OpenMP Enhanced Composability in addition ensures larger code bases can be integrated and migrated to support and coexist with SYCL-based heterogeneous offload, with the OpenMP programming frameworks intact.
At Intel, we are happy to be at the forefront of these discussions and integrate these capabilities into our OpenMP runtime libraries, Intel® Fortran Compiler and Intel® oneAPI DPC++/C++ Compiler. We embrace the spirit of open standards, contributing to many open source initiatives for accelerated compute frameworks like OpenCL*, SYCL, and OpenMP, and compiler initiatives like LLVM* and the intermediate SPIR-V* abstraction layer. Download the Compilers Now
You can download the Intel Fortran Compiler and Intel oneAPI DPC++/C++ Compiler on Intel’s oneAPI Developer Tools product page.
They are also available as part of the Intel® oneAPI HPC Toolkit and the Intel® oneAPI Base Toolkit, respectively, which include an advanced set of foundational tools, libraries, analysis, debug, and code migration tools.
You may also want to check out our contributions to the LLVM compiler project on GitHub.
Additional Resources
- Solving Heterogeneous Programming Challenges with Fortran and OpenMP
- The Parallel Universe Magazine
- The Case for OpenMP Target Offloading [1:06:07]
- OpenMP Support: Intel® Fortran Compiler Developer Guide and Reference
- OpenMP Support: Intel® oneAPI DPC++/C++ Compiler Developer Guide and Reference
- OpenMP Specifications