To fully utilize the power of Intel® architecture (IA) for high performance, you can enable TensorFlow* to be powered by Intel’s highly optimized math routines in the Intel® oneAPI Deep Neural Network Library (oneDNN). oneDNN includes convolution, normalization, activation, inner product, and other primitives.
The oneAPI Deep Neural Network Library (oneDNN) optimizations are now available both in the official x86-64 TensorFlow and Intel® Optimization for TensorFlow* after v2.5. Users can enable those CPU optimizations by setting the the environment variable TF_ENABLE_ONEDNN_OPTS=1 for the official x86-64 TensorFlow after v2.5.
Most of the recommendations work on both official x86-64 TensorFlow and Intel® Optimization for TensorFlow. Some recommendations such as OpenMP tuning only applies to Intel® Optimization for TensorFlow.
For setting up Intel® Optimization for TensorFlow* framework, please refer to this installation guide.
Maximum Throughput vs. Real-time Inference
You can perform deep learning inference using two different strategies, each with different performance measurements and recommendations. The first is Max Throughput (MxT), which aims to process as many images per second as possible, passing in batches of size > 1. For Max Throughput, you achieve better performance by exercising all the physical cores on a socket. With this strategy, you simply load up the CPU with as much work as you can and process as many images as you can in a parallel and vectorized fashion.
An altogether different strategy is Real-time Inference (RTI) where you typically process a single image as fast as possible. Here you aim to avoid penalties from excessive thread launching and orchestration among concurrent processes. The strategy is to confine and execute quickly. The best-known methods (BKMs) differ for these two strategies.
TensorFlow Graph Options Improving Performance
Optimizing graphs help improve latency and throughput time by transforming graph nodes to have only inference related nodes and by removing all training nodes.
Users can use tools from TensorFlow github.
First, use freeze_graph
First, freezing the graph can provide additional performance benefits. The freeze_graph tool, available as part of TensorFlow on GitHub, converts all the variable ops to const ops on the inference graph and outputs a frozen graph. With all weights frozen in the resulting inference graph, you can expect improved inference time. Here is a LINK to access the freeze_graph tool.
Second, Use optimize_for_inference
When the trained model is used only for inference, after the graph has been frozen, additional transformations can help optimize the graph for inference. TensorFlow project on GitHub offers an easy to use optimization tool to improve the inference time by applying these transformations to a trained model output. The output will be an inference-optimized graph to improve inference time. Here is a LINK to access the optimize_for_inference tool.
TensorFlow Runtime Options Improving Performance
Runtime options heavily affect TensorFlow performance. Understanding them will help get the best performance out of the Intel Optimization of TensorFlow.
Recommended settings (RTI):intra_op_parallelism = number of physical core per socket
Recommended settings: inter_op_parallelism = number of sockets
Users can put below bash commands into a bash script file, and then get the number of physical core per socket and number of sockets on your platform by executing the bash script file.
total_cpu_cores=$(nproc)
number_sockets=$(($(grep "^physical id" /proc/cpuinfo | awk '{print $4}' | sort -un | tail -1)+1))
number_cpu_cores=$(( (total_cpu_cores/2) / number_sockets))
echo "number of CPU cores per socket: $number_cpu_cores";
echo "number of socket: $number_sockets";
For example, here is how you can set the inter and intra_op_num_threads by using TensorFlow Benchmark.tf_cnn_benchmarks usage (shell)
python tf_cnn_benchmarks.py --num_intra_threads=<number of physical cores per socket> --num_inter_threads=<number of sockets>
intra_op_parallelism_threads and inter_op_parallelism_threads are runtime variables defined in TensorFlow.
ConfigProto
The ConfigProto is used for configuration when creating a session. These two variables control number of cores to use.
- intra_op_parallelism_threads
- This runtime setting controls parallelism inside an operation. For instance, if matrix multiplication or reduction is intended to be executed in several threads, this variable should be set. TensorFlow will schedule tasks in a thread pool that contains intra_op_parallelism_threads threads. As illustrated later in Figure 2, OpenMP* threads are bound to thread context as close as possible on different cores. Setting this environment variable to the number of available physical cores is recommended.
- inter_op_parallelism_threads
- NOTE: This setting is highly dependent on hardware and topologies, so it’s best to empirically confirm the best setting on your workload.
This runtime setting controls parallelism among independent operations. Since these operations are not relevant to each other, TensorFlow will try to run them concurrently in the thread pool that contains inter_op_parallelism_threads threads. This variable should be set to the number of parallel paths where you want the code to run. For Intel® Optimization for TensorFlow, we recommend starting with the setting '2’, and adjusting after empirical testing.
Recommended settings → data_format = NHWC
tf_cnn_benchmarks usage (shell)
python tf_cnn_benchmarks.py --num_intra_threads=<number of physical cores per socket> --num_inter_threads=<number of sockets> --data_format=NHWC
Efficiently using cache and memory yields remarkable improvements in overall performance. A good memory access pattern minimizes extra cost for accessing data in memory and improves overall processing. Data layout, how data is stored and accessed, plays an important role in achieving these good memory access patterns. Data layout describes how multidimensional arrays are stored linearly in memory address space.
In most cases, data layout is represented by four letters for a two-dimensional image:
-
N: Batch size, indicates number of images in a batch.
-
C: Channel, indicates number of channels in an image.
-
W: Width, indicates number of horizontal pixels of an image.
-
H: Height, indicates number of vertical pixels of an image.
The order of these four letters indicates how pixel data are stored in the one-dimensional memory space. For instance, NCHW indicates pixel data are stored as width first, then height, then channel, and finally batch (Illustrated in Figure 2). The data is then accessed from left-to-right with channel-first indexing. NCHW is the recommended data layout for using oneDNN, since this format is an efficient data layout for the CPU. TensorFlow uses NHWC as its default data layout, but it also supports NCHW.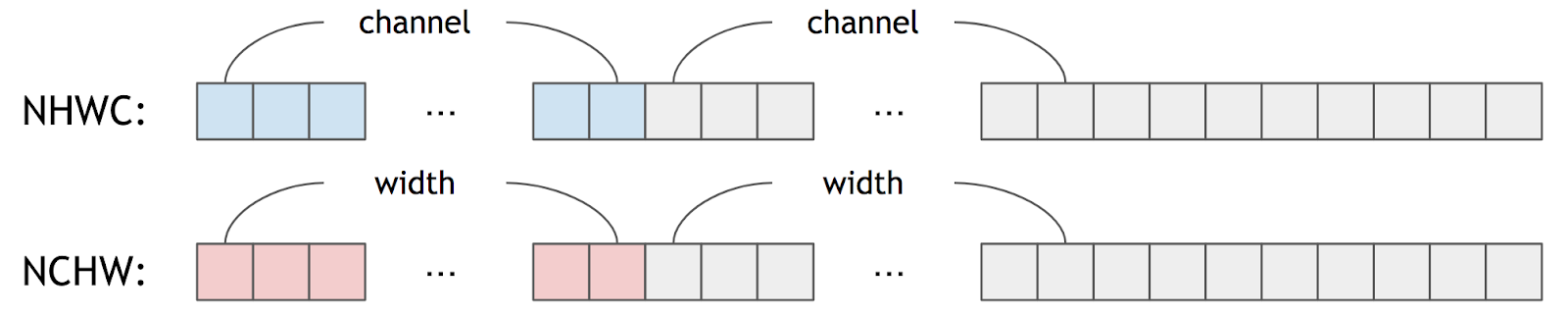
Figure 1: Data Formats for Deep Learning NHWC and NCHW
NOTE : Intel Optimized TensorFlow supports both plain data formats like NCHW/NHWC and also oneDNN blocked data format since version 2.4. Using blocked format might help on vectorization but might introduce some data reordering operations in TensorFlow.
Users could enable/disable usage of oneDNN blocked data format in Tensorflow by TF_ENABLE_MKL_NATIVE_FORMAT environment variable. By exporting TF_ENABLE_MKL_NATIVE_FORMAT=0, TensorFlow will use oneDNN blocked data format instead. Please check oneDNN memory format for more information about oneDNN blocked data format.
We recommend users to enable NATIVE_FORMAT by below command to achieve good out-of-box performance. export TF_ENABLE_MKL_NATIVE_FORMAT=1 (or 0)
There are some runtime arguments related to oneDNN optimizations in TensorFlow.
Users could tune those runtime arguments to achieve better performance.
| Environment Variables | Default | Purpose |
|---|---|---|
| TF_ENABLE_ONEDNN_OPTS | True | Enable/Disable oneDNN optimization |
| TF_ONEDNN_ASSUME_FROZEN_WEIGHTS | False | Frozen weights for inference. Better inference performance is achieved with frozen graphs. Related ops: fwd conv, fused matmul |
| TF_ONEDNN_USE_SYSTEM_ALLOCATOR | False | Use system allocator or BFC allocator in MklCPUAllocator. Usage:
|
| TF_MKL_ALLOC_MAX_BYTES | 64 | MklCPUAllocator: Set upper bound on memory allocation. Unit:GB |
| TF_MKL_OPTIMIZE_PRIMITIVE_MEMUSE | True | Use oneDNN primitive caching or not.
|
For deep learning workloads, TCMalloc can get better performance by reusing memory as much as possible than default malloc function. TCMalloc features a couple of optimizations to speed up program executions. TCMalloc is holding memory in caches to speed up access of commonly-used objects. Holding such caches even after deallocation also helps avoid costly system calls if such memory is later re-allocated. Use environment variable LD_PRELOAD to take advantage of one of them.
$ sudo apt-get install google-perftools
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libtcmalloc.so.4 python script.py …
Non-uniform memory access (NUMA) Controls Affecting Performance
NUMA, or non-uniform memory access, is a memory layout design used in data center machines meant to take advantage of locality of memory in multi-socket machines with multiple memory controllers and blocks. Running on a NUMA-enabled machine brings with it, special considerations. Intel® Optimization for TensorFlow runs inference workload best when confining both the execution and memory usage to a single NUMA node. When running on a NUMA-enabled system, recommendation is to set intra_op_parallelism_threads to the numbers of local cores in each single NUMA-node.
Recommended settings: --cpunodebind=0 --membind=0
Usage (shell)
numactl --cpunodebind=0 --membind=0 python
You can optimize performance by breaking up your workload into multiple data shards and then running them concurrently on more than one NUMA node. On each node (N), run the following command:
Usage (shell)
numactl --cpunodebind=N --membind=N python
For example, you can use the “&” command to launch simultaneous processes on multiple NUMA nodes:
numactl --cpunodebind=0 --membind=0 python & numactl --cpunodebind=1 --membind=1 python
Users could bind threads to specific CPUs via "--physcpubind=cpus" or "-C cpus"
Setting its value to "0-N" will bind threads to physical cores 0 to N only.
Usage (shell)
numactl --cpunodebind=N --membind=N -C 0-N python
For example, you can use the “&” command to launch simultaneous processes on multiple NUMA nodes on physical CPU 0 to 3 and 4 to 7:
numactl --cpunodebind=0 --membind=0 -C 0-3 python & numactl --cpunodebind=1 --membind=1 -C 4-7 python
NOTE : oneDNN will get the CPU affinity mask from users' numactl setting and set the maximum number of working threads in the threadpool accordingly after TensorFlow v2.5.0 RC1.
OpenMP Technical Performance Considerations for Intel® Optimization for TensorFlow
This section is only for Intel® Optimization for TensorFlow, and it does not apply to official TensorFlow release.
Intel® Optimization for TensorFlow utilizes OpenMP to parallelize deep learning model execution among CPU cores.
Users can use the following environment variables to be able to tune Intel® optimized TensorFlow performance . Thus, changing values of these environment variables affects performance of the framework. These environment variables will be described in detail in the following sections. We highly recommend users tuning these values for their specific neural network model and platform.
Recommended settings for CNN→ OMP_NUM_THREADS = num physical cores
Usage (shell)
export OMP_NUM_THREADS=num physical cores
This environment variable sets the maximum number of threads to use for OpenMP parallel regions if no other value is specified in the application.
With Hyperthreading enabled, there are more than one hardware threads for a physical CPU core, but we recommend to use only one hardware thread for a physical CPU core to avoid cache miss problems.
tf_cnn_benchmarks usage (shell)
OMP_NUM_THREADS=<number of physical cores per socket> python tf_cnn_benchmarks.py --num_intra_threads=<number of physical cores per socket> --num_inter_threads=<number of sockets> --data_format=NCHW
Users can bind OpenMP threads to physical processing units. KMP_AFFINITY is used to take advantage of this functionality. It restricts execution of certain threads to a subset of the physical processing units in a multiprocessor computer.
The value can be a single integer, in which case it specifies the number of threads for all parallel regions. The value can also be a comma-separated list of integers, in which case each integer specifies the number of threads for a parallel region at a nesting level.
The first position in the list represents the outer-most parallel nesting level, the second position represents the next-inner parallel nesting level, and so on. At any level, the integer can be left out of the list. If the first integer in a list is left out, it implies the normal default value for threads is used at the outer-most level. If the integer is left out of any other level, the number of threads for that level is inherited from the previous level.
The default value is the number of logical processors visible to the operating system on which the program is executed. This value is recommended to be set to the number of physical cores.
Recommended settings → KMP_AFFINITY=granularity=fine,verbose,compact,1,0
export KMP_AFFINITY=granularity=fine,compact,1,0
tfcnnbenchmarks usage (shell)
OMP_NUM_THREADS=<number of physical cores per socket> python tf_cnn_benchmarks.py --num_intra_threads=<number of physical cores per socket> --num_inter_threads=<number of sockets> --data_format=NCHW --kmp_affinity=granularity=fine,compact,1,0
Users can bind OpenMP threads to physical processing units. KMP_AFFINITY is used to take advantage of this functionality. It restricts execution of certain threads to a subset of the physical processing units in a multiprocessor computer.
Usage of this environment variable is as below.
KMP_AFFINITY=[,…][,][,]
Modifier is a string consisting of keyword and specifier. type is a string indicating the thread affinity to use. permute is a positive integer value, controls which levels are most significant when sorting the machine topology map. The value forces the mappings to make the specified number of most significant levels of the sort the least significant, and it inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations. offset is a positive integer value, indicates the starting position for thread assignment. We will use the recommended setting of KMP_AFFINITY as an example to explain basic content of this environment variable.
KMP_AFFINITY=granularity=fine,verbose,compact,1,0
The modifier is granularity=fine,verbose. Fine causes each OpenMP thread to be bound to a single thread context. Verbose prints messages at runtime concerning the supported affinity, and this is optional. These messages include information about the number of packages, number of cores in each package, number of thread contexts for each core, and OpenMP thread bindings to physical thread contexts. Compact is value of type, assigning the OpenMP thread +1 to a free thread context as close as possible to the thread context where the OpenMP thread was placed.
NOTE The recommendation changes if Hyperthreading is disabled on your machine. In that case, the recommendation is: KMP_AFFINITY=granularity=fine,verbose,compact if hyperthreading is disabled.
Fig. 2 shows the machine topology map when KMP_AFFINITY is set to these values. The OpenMP thread +1 is bound to a thread context as close as possible to OpenMP thread , but on a different core. Once each core has been assigned one OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.
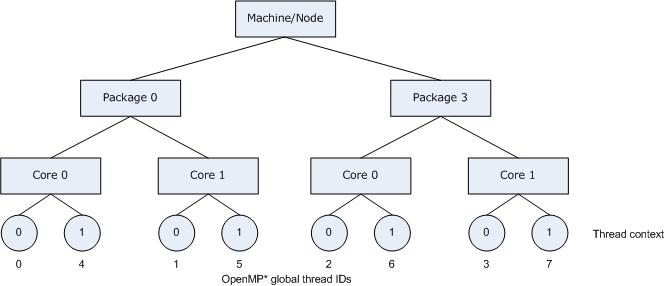
Figure 2. Machine topology map with setting KMP_AFFINITY=granularity=fine,compact,1,0
The advantage of this setting is that consecutive threads are bound close together, so that communication overhead, cache line invalidation overhead, and page thrashing are minimized. If the application also had a number of parallel regions that did not use all of the available OpenMP threads, you should avoid binding multiple threads to the same core, leaving other cores not utilized.
For a more detailed description of KMP_AFFINITY, please refer to Intel® C++ developer guide.
Recommended settings for CNN→ KMP_BLOCKTIME=0
Recommended settings for non-CNN→ KMP_BLOCKTIME=1 (user should verify empirically)
usage (shell)
export KMP_BLOCKTIME=0 (or 1)
tfcnnbenchmarks usage (shell)
OMP_NUM_THREADS=<number of physical cores per socket> python tf_cnn_benchmarks.py --num_intra_threads=<number of physical cores per socket> --num_inter_threads=<number of sockets> --data_format=NCHW --kmp_affinity=granularity=fine,compact,1,0 --kmp_blocktime=0( or 1)
This environment variable sets the time, in milliseconds, that a thread should wait, after completing the execution of a parallel region, before sleeping. The default value is 200ms.
After completing the execution of a parallel region, threads wait for new parallel work to become available. After a certain time has elapsed, they stop waiting, and sleep. Sleeping allows the threads to be used, until more parallel work becomes available, by non-OpenMP threaded code that may execute between parallel regions, or by other applications. A small KMP_BLOCKTIME value may offer better overall performance if application contains non-OpenMP threaded code that executes between parallel regions. A larger KMP_BLOCKTIME value may be more appropriate if threads are to be reserved solely for use for OpenMP execution, but may penalize other concurrently-running OpenMP or threaded applications. It is suggested to be set to 0 for convolutional neural network (CNN) based models.
Usage (shell)
export KMP_SETTINGS=TRUE
This environment variable enables (TRUE) or disables (FALSE) the printing of OpenMP run-time library environment variables during program execution.
Enable Mixed Precision
Mixed precision is the use of both 16-bit and 32-bit floating-point types in a model during training and inference to make it run faster and use less memory.
There are two options to enable BF16 mixed precision in TensorFlow.
- Keras mixed precision API
- AutoMixedPrecision oneDNN BFloat16 grappler pass through low level session configuration
Refer to Getting Started with Mixed Precision Support in oneDNN Bfloat16 for more details.
Additional Information
| AddN |
| AvgPool |
| AvgPool3D |
| AvgPool3DGrad |
| AvgPoolGrad |
| Conv2D |
| Conv2DBackpropFilter |
| Conv2DBackpropFilterWithBias |
| Conv2DBackpropInput |
| Conv2DWithBias |
| Conv2DWithBiasBackpropBias |
| Conv3D |
| Conv3DBackpropFilter |
| Conv3DBackpropInput |
| DepthwiseConv2dNative |
| DepthwiseConv2dNativeBackpropFilter |
| DepthwiseConv2dNativeBackpropInput |
| Dequantize |
| Einsum |
| Elu |
| EluGrad |
| FusedBatchNorm |
| FusedBatchNorm |
| FusedBatchNormFusion |
| FusedBatchNormGrad |
| FusedBatchNormGrad |
| FusedConv2D |
| FusedDepthwiseConv2dNative |
| FusedMatMul |
| LeakyRelu |
| LeakyReluGrad |
| LRN |
| LRNGrad |
| MatMul |
| MaxPool |
| MaxPool3D |
| MaxPool3DGrad |
| MaxPoolGrad |
| Mul |
| Quantize |
| QuantizedAvgPool |
| QuantizedConcat |
| QuantizedConv2D |
| QuantizedDepthwiseConv2D |
| QuantizedMatMul |
| QuantizedMaxPool |
| Relu |
| Relu6 |
| Relu6Grad |
| ReluGrad |
| Softmax |
| Tanh |
| TanhGrad |
Known issues
- Performance degradation may be observed running with BF16 on small batch size.
Resources
Check out these resource links for more information about Intel’s AI Kit and TensorFlow optimizations: