Overview
Mixed precision is the use of both 16-bit and 32-bit floating-point types in a model during training and inference to make it run faster and use less memory. Official TensorFlow supports this feature from TensorFlow 2.12 with all Intel® optimizations enabled by default. Intel® 4th Gen Xeon processor codenamed Sapphire Rapids is the first Intel® processor to support Advanced Matrix Extensions(AMX) instructions, which help to accelerate matrix heavy workflows such as machine learning alongside also having BFloat16 support. Previous generations can be used to test functionality, but Sapphire Rapids provides the best performance gains.
Using one of the methods described here will enable a model written in FP32 data type to operate in mixed FP32 and BFloat16 data type. To be precise, it scans the data-flow graph corresponding to the model, and looks for nodes in the graph (also called as operators) that can operate in BFloat16 type, and inserts FP32ToBFloat16 and vice-versa Cast nodes in the graph appropriately.
For example: Consider a simple neural network with a typical pattern of Conv2D -> BiasAdd -> Relu with the default TensorFlow datatype FP32. TensorFlow data-flow graph corresponding to this model looks like below.
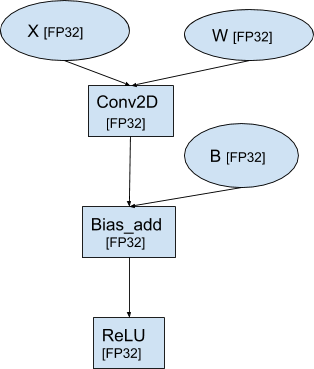
The data-flow graph after porting the model to BFloat16 type looks like below.
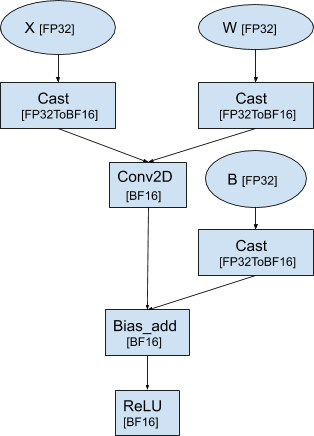
Notice that 2 operators, Conv2D+BiasAdd and ReLU in the graph are automatically converted to operate in BFloat16 type. Also note that appropriate Cast nodes are inserted in the graph to convert TensorFlow tensors from FP32 type to BFloat16 type and vice-versa.
Here are the different ways to enable BF16 mixed precision in TensorFlow.
- Keras mixed precision API
- Mixed Precision for TensorFlow Hub models
- Legacy AutoMixedPrecision grappler pass
- Mixed Precision with HuggingFace and other sources
- Reduced precision math mode via environment variable (introduced in TensorFlow 2.13)
This guide describes the options in details.
I. Keras mixed precision API
Introduction
This session describes how to use the Keras mixed precision API to speed up your models by using Simple MNIST convnet as example.
Getting started with a FP32 Model
By using an existing sample, users can easily understand how to change their own Keras* model.
First, create an environment and install TensorFlow
conda create -n tf_latest python=3.8 -c intel
source activate tf_latest
(tf_latest) pip install tensorflow
Next, get the sample model using the command below and then using python train the model.
wget https://raw.githubusercontent.com/keras-team/keras-io/master/examples/vision/mnist_convnet.py
python mnist_convnet.py
Steps to enable BFloat16 mixed precision
To use bfloat16 as compute data type in the above model, users only need to add the below two lines around line#16 of mnist_convert.py i.e after importing keras and layers. These same steps apply for training and inference usecases.
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import mixed_precision
mixed_precision.set_global_policy('mixed_bfloat16') # <--- note these 2 lines
Users can use oneDNN verbose logs to verify if this modified mnistconvnet indeed uses bfloat16 data type for computation. Using ONEDNN_VERBOSE=1 environment variable as shown below, users will get a oneDNN verbose log file "dnnllog.csv".
ONEDNN_VERBOSE=1 python mnist_convnet.py > dnnl_log.csv
Look in the log for bf16 and then it is using BFloat16 for computation. Here's an example for matmul
onednn_verbose,exec,cpu,matmul,brg:avx512_core_**amx_bf16**,undef,src_bf16::blocked:ba:f0 wei_bf16::blocked:ab:f0 dst_bf16::blocked:ab:f0,attr-scratchpad:user ,,1600x128:128x10:1600x10
Please use Python 3.8 or above for the best performance on Sapphire Rapids Xeon Scalable Processors.
II. Mixed Precision for TensorFlow Hub models
Introduction
This session describes how to enable the auto-mixed precision for TensorFlow Hub models using the tf.config API. Enabling this API will automatically convert the pre-trained model to use the bfloat16 datatype for computation resulting in an increased training throughput on the latest Intel® Xeon® scalable processor. These instructions works for inference or fine tuning usecase.
Steps to do Transfer Learning with Mixed Precision on a Saved Model
We can use this example for Transfer Learning. By applying below experimental option "auto_mixed_precision_onednn_bfloat16" via tf.config API, auto mixed precision with bfloat16 will be enabled on the saved model.
import tensorflow as tf
tf.config.optimizer.set_experimental_options({'auto_mixed_precision_onednn_bfloat16':True})
Steps to enable Bfloat16 Inference for a Saved Model
Here's a TF HUB inference example. Same config as earlier can be used.
import tensorflow as tf
tf.config.optimizer.set_experimental_options({'auto_mixed_precision_onednn_bfloat16':True})
End-to-end example using Mixed Precision for Transfer Learning
For end-to-end example please refer to this Transfer Learning sample which uses a headless ResNet50v1.5 pretrained model from TensorFlow Hub with ImageNet dataset. It also provides examples for performance improvements.
Remember to use Sapphire Rapids server. say eg: C3 instance on GCP.
III. Legacy Auto Mixed Precision (AMP) with Bfloat16
Auto Mixed Precision is a grappler pass that automatically converts a model written in FP32 data type to operate in BFloat16 data type. It mainly supports TF v1 style models that use a session to run the model. We will demonstrate this with examples illustrating:
- How to convert the graph to BFloat16 on-the-fly as you train the model
- How to convert a pre-trained fp32 model to BFloat16
Let’s use a simple neural network with a typical pattern of Conv2D -> BiasAdd -> ReLU. Inputs x and w of Conv2D and input b of bias_add are TensorFlow Variables with default FP32 data type, so this neural network model operates completely in FP32 data type. TensorFlow data-flow graph corresponding to this model looks like below.
Steps to set up the runtime environment
Before running the examples, setup runtime environement with steps below to create an environment and install TensorFlow, as done earlier.
conda create -n tf_latest python=3.8 -c intel
source activate tf_latest
(tf_latest) pip install tensorflow
Enabling BFloat16 using AMP in a Model
Following lines of Python* code will enable BFloat16 data type using Auto Mixed Precision when using grappler via TensorFlow v1. This setting enables BF16 for training AND inference usecase.
graph_options=tf.compat.v1.GraphOptions(
rewrite_options=rewriter_config_pb2.RewriterConfig(
auto_mixed_precision_onednn_bfloat16=rewriter_config_pb2.RewriterConfig.ON))
Auto Mixed Precision grappler pass is disabled by default and can be controlled using RewriterConfig proto of GraphOptions proto. To enable use rewriter_config_pb2.RewriterConfig.ON and to disable use rewriter_config_pb2.RewriterConfig.OFF (default).
Below is the complete code for a neural network model ported to BFloat16 data type using Auto Mixed Precision.
import tensorflow as tf
from tensorflow.core.protobuf import rewriter_config_pb2
tf.compat.v1.disable_eager_execution()
def conv2d(x, w, b, strides=1):
# Conv2D wrapper, with bias and relu activation
x = tf.nn.conv2d(x, w, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
X = tf.Variable(tf.compat.v1.random_normal([784]))
W = tf.Variable(tf.compat.v1.random_normal([5, 5, 1, 32]))
B = tf.Variable(tf.compat.v1.random_normal([32]))
x = tf.reshape(X, shape=[-1, 28, 28, 1])
# Note: Auto Mixed Precision pass is enabled here to run on Xeon CPUs with BFloat16
graph_options=tf.compat.v1.GraphOptions(
rewrite_options=rewriter_config_pb2.RewriterConfig(
auto_mixed_precision_onednn_bfloat16=rewriter_config_pb2.RewriterConfig.ON))
with tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(
graph_options=graph_options)) as sess:
sess.run(tf.compat.v1.global_variables_initializer())
sess.run([conv2d(x, W, B)])
Notice that graph_options variable created by turning Auto Mixed Precision ON is passed to ConfigProto that is eventually passed to tf.Session API.
Create and run the Python* file with the above code conv2D_bf16.py
python conv2D_bf16.py
Console output
2022-08-19 00:06:08.735706: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:2303] Running auto_mixed_precision_onednn_bfloat16 graph optimizer
2022-08-19 00:06:08.735941: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:1488] No allowlist ops found, nothing to do
2022-08-19 00:06:08.750799: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:2303] Running auto_mixed_precision_onednn_bfloat16 graph optimizer
2022-08-19 00:06:08.751058: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:2240] Converted 3/11 nodes to bfloat16 precision using 0 cast(s) to bfloat16 (excluding Const and Variable casts)
No allowlist ops found typically refers to the data session. One can also use ONEDNN_VERBOSE logs as discussed earlier to verify AMX BF16 instructions.
Controlling Ops to be converted to BFloat16 type Automatically
An important point to note is that not all of TensorFlow’s operators for CPU backend support BFloat16 type - this could be because either the support is missing (and is a WIP) or that the BFloat16 version of an operator may not offer much performance improvement over the FP32 implementation. Or for certain operators, BFloat16 type could lead to numerical instability of the neural network model.
So we categorize TensorFlow operators that are supported by MKL backend in BFloat16 type into 1) if they are always numerically stable, and 2) if they are always numerically unstable, and 3) if their stability could depend on the context. Auto Mixed Precision pass uses a specific Allow, Deny, Clear and Infer list of operators respectively to capture these operators. The exact lists could be found in auto_mixed_precision_lists.h file in TensorFlow github repository.
The default values of these lists already capture the most common BFloat16 usage models and also ensure numerical stability of the model. There is, however, a way to add or remove operators from any of these lists by setting environment variables that control these lists. For instance, executing
export TF_AUTO_MIXED_PRECISION_GRAPH_REWRITE_DENYLIST_ADD=Conv2D
before running the model would add Conv2D operator to Deny list. While, executing
export TF_AUTO_MIXED_PRECISION_GRAPH_REWRITE_ALLOWLIST_REMOVE=Conv2D
before running the model would remove Conv2D from Allow list. And executing both of these commands before running a model would move Conv2D from Allow list to Deny list. It's important to note that it is not allowed for same operator to be in more than 1 list.
In general, the template corresponding to the names of the environment variables controlling these lists is:
TF_AUTO_MIXED_PRECISION_GRAPH_REWRITE_${LIST}_${OP}=operator
where ${LIST} would be any of {ALLOW, DENY, INFER, CLEAR}, and ${OP} would be any of {ADD, REMOVE}.
IV. Mixed Precision with other ways of executing model
Apart from the above usecases, there are many places that serve as Model Hub. For example, HuggingFace is a popular place where one can pick easy to experiment scripts to try a model. To enable mixed precision with we can use the keras method described above if it is keras based model.
HuggingFace BFloat16 Mixed Precsion Inference
We can use this TF Distilbert model as example and used Keras Mixed Precision API to enable BFloat16 computation.
from transformers import AutoTokenizer, TFDistilBertForSequenceClassification
import tensorflow as tf
tf.keras.mixed_precision.set_global_policy('mixed_bfloat16') # <--- note this
For other models sources
- If it is a TFHub like SavedModel, one can use the config API described in section II.
- If it is an older SavedModel saved in a .pbtxt file, one can use the config API described in secction III.
V. Reduced precision math mode via environment variable
In TensorFlow 2.13, a new environment variable, TF_SET_ONEDNN_FPMATH_MODE, is introduced to enable mixed precision computation in hardwares enpowered by new generation of Intel® Xeon processors starting from SPR. When setting this variable TF_SET_ONEDNN_FPMATH_MODE=BF16, Intel® oneDNN library inside TensorFlow will perform reduced precision math computation on high cost operations such as convolution and matrix multiplication. This option is different from the others listed above, no Cast nodes are added in the graph level by TensorFlow framework, instead, the conversion between FP32 and BF16 is handled inside the oneDNN library. This environment variable can be added as prefix to the model run command, i.e.,
TF_SET_ONEDNN_FPMATH_MODE=BF16 python mnist_convnet.py