
Learn How to Build and Run the Open Source OpenAI* Triton Backend for Intel® GPUs
As deep learning (DL) AI solutions become larger and larger, one of the biggest challenges facing AI developers is how to create performant models efficiently. Traditionally, AI model developers had to write their kernels in C++ and then expose it to Python* using pybind. This required AI developers to not only understand DL kernels and models, but also learn C++ and the associated C++ tensor abstractions for kernel development. Recognizing this challenge, OpenAI* released Triton, an open-source, domain-specific, Python-like programming language and compiler that enables developers to write efficient GPU code.
OpenAI Triton Overview
Triton provides an intermediate layer between C++ and Python in terms of functionality and performance. The goal is to allow DL developers to build optimized kernels without having to implement them across multiple layers of the software stack. While Triton is not native Python, it does allow us to develop within the same source file as our Python code, which makes code management much simpler.
As DL inherently deals with large-scale, parallel computation, Triton is designed to work with blocks of data instead of individual elements. This inherently simplifies the syntax of the language where a variable, once defined, represents a set of data. For example, writing:
result = x + y
performs an elementwise addition of the x and y vectors and writes that output vector to the result variable.
Beyond a simplification of syntax, a key benefit of Triton is performance. Triton is a language and a compiler, which means there is the ability to map syntax to a specific hardware design. Neural networks are large and require significant memory operations to execute. Triton is defined intentionally to allow developers and the compiler backends to map the operations in the language to more optimized usage of cache hierarchies and memory than would be available in native Python.
This is just a small part of the functionality enabled by Triton, which includes a variety of operations essential for DL developers. For a deeper dive into Triton, check out OpenAI’s Triton resources.
Triton on Intel® Core™ Ultra Processors
OpenAI is simplifying the software development challenges. As a developer, I want to develop my code where I want and when I want. One could buy a workstation-level laptop, but those tend to be heavy and clunky. Enter my new Intel® Core™ Ultra processor-based laptop, with its more powerful integrated GPU and neural processing unit. I decided to take it for a spin and try Triton on my brand-new AI PC.
Compiling Triton for Intel Core Ultra Processors
Triton is open source, but support for Intel® GPUs is in development and has yet to be upstreamed into the Triton main repository. Intel is developing their Triton backend in open source here. Similar to other hardware vendors, Intel is developing this backend off a fork of Triton and will work to upstream this work. While the GitHub* site mentions that this code is being developed and tested on Intel® Data Center GPU Max Series cards, software developed using oneAPI for any Intel GPU should work on other Intel GPUs too. So, I decided to try to build the code from the source and see how it works on my MSI* Prestige 16 AI Evo laptop. (As an aside, I also did it on my consumer-level Intel® Arc™ A770 GPU and it worked as well.)
System Setup
The system I am using has the following configuration:
- Ubuntu* 23.10, Kernel 6.5.0-17
- Intel® oneAPI Basekit 2024.0.1 (installation instructions)
- Anaconda* (installation instructions)
Note that once after installing Linux*, I did have to update /etc/default/grub to replace:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
with
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash i915.force_probe=7d55"
where 7d55 is the PCI ID of the integrated GPU. You must do this as the upstream Ubuntu integrated driver does not yet recognize the PCI ID of the latest iGPU. Next, run
sudo update-grub
and then reboot.
Getting and Building Triton
Following the build instructions on GitHub can be challenging, so here is a breakdown of the commands I ran to build and run Triton on my AI PC. First, let’s set up the environment:
# checkout Intel XPU Backend for Triton and change to that directory
git clone https://github.com/intel/intel-xpu-backend-for-triton.git -b llvm-target
cd intel-xpu-backend-for-triton
# Create a conda environment using Python 3.10 and activate the environment
conda create --name triton python=3.10
conda activate triton
# setup the oneAPI build and runtime environment
source /opt/intel/oneapi/setvars.sh
# install components as required by Triton build infrastructure and set their recommend environment variable to build with Clang
pip install ninja cmake wheel
export TRITON_BUILD_WITH_CLANG_LLD=true
You will notice that I use Python 3.10 instead of 3.11 or later because Triton does not currently work with Python 3.11 or 3.12. Also, llvm-target is the main branch of the code, so you could get away without specifying the branch.
Following the instructions in the repo, we can run the build:
./scripts/compile-triton.sh
Unfortunately, this build throws an error that CUDA* is not found. A quick attempt to install the CUDA toolkit on 23.10 fails as there are some libraries it depends on that are not available out-of-the-box on 23.10. To work around this, we can add the 23.04 repository to our Ubuntu 23.10 APT sources by editing /etc/apt/sources.list and adding the following line:
deb http://archive.ubuntu.com/ubuntu/ lunar universe
and then do a quick
sudo apt update
which allows us to install CUDA.
Rerunning the build then hits another error, which is that the clang and clang++ compilers are not found. Since I have the Intel oneAPI DPC++ compiler installed, which is based on clang, it is simple to point to the clang included with the Intel DPC++ compiler by setting the PATH variable:
export PATH=$PATH:/opt/intel/oneapi/compiler/latest/bin/compiler
One last run of the compile script and I am up and running.
Testing Triton on Intel Core Ultra
A quick first test is to check out the python/tutorials directory within the intel-xpu-backend-for-triton code base. To evaluate some basic functionality, I am running the first couple of examples from the directory. Looking at the test codes, you will see that there are some basic changes from the OpenAI Triton repository to select the Intel GPU to be used. Changing code like this:
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
to this:
x = torch.rand(size, device='xpu')
y = torch.rand(size, device='xpu')
Setting Up the Runtime Environment
Trying out my new Triton build requires I add PyTorch* to my environment, so my first step is to install the Intel® Extension for PyTorch:
python -m pip install torch==2.1.0a0 torchvision==0.16.0a0 torchaudio==2.1.0a0 intel-extension-for-pytorch==2.1.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
The tutorial examples also require some additional Python libraries, which are easily installed using pip.
pip install matplotlib pandas
Running Examples
The first tutorial is a simple vector add between two blocks of data. The output looks like this:
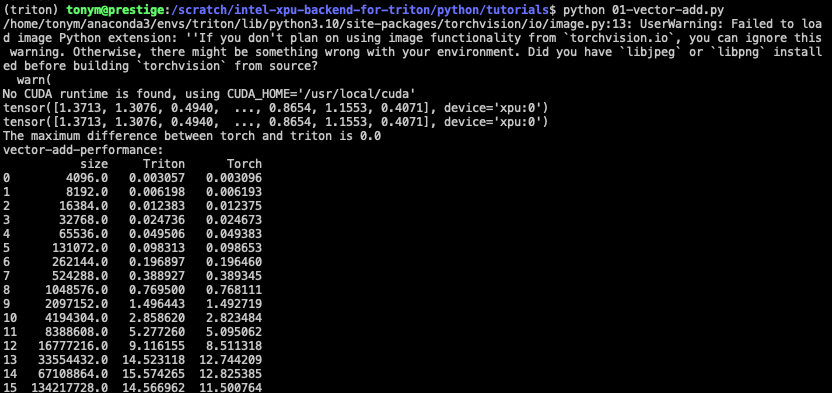
The output measures the correctness of the data and the relative performance of the operations in the vector addition. Here we can see that the numbers that I saw here are in line, but as the size of vectors increases, the Triton approach begins to provide improved performance on my Intel Core Ultra integrated GPU.
The second tutorial is a fused-softmax implementation. The softmax function maps a vector to a probability distribution of outcomes and is often used in DL algorithms as the last activation function of a neural network. As softmax is doing a signification number of operations across the input vector, vectorization and can result in significant performance benefits. The fused-softmax implementation aims to block data accesses to improve a naïve implementation. Note that there is already a native fused-softmax implementation in PyTorch, which means there is a hardware-optimized C++ version of this operation against which we can compare. Running the tutorial gives the following output:

Here we can see the performance of three different implementations of softmax. The first column is the Triton version, the second is the C++-optimized version, and the third is the naïve version. For the Intel Core Ultra, the Triton version is faster than the naïve version, but still slower than the C++-native version of the code. This makes sense because the Torch C++ implementation has already been heavily optimized. However, the ability to write code that is much faster than the naïve implementation using only Python is exciting as a developer.
Conclusion
The Triton framework has significant support among DL kernel developers. The simple parallel syntax and ability to optimize data access on the underlying hardware, all from higher-level Python code, provide a promising path to simplifying DL kernel development. Combined with the Intel Core Ultra processor-based AI PC, this framework provides a promising path to do DL kernel development where I want, when I want. Development of the intel-xpu-backend-for-triton is a work in progress, but I am looking forward to reaping the benefits of this exciting hardware and software combination.