
Introduction
OpenACC* and OpenMP* both support offloading to accelerators. The earlier availability of OpenACC made it appealing to users willing to use GPU devices for their computational workloads. However, OpenACC supports a limited number of device vendors, and there has been an increasing demand to adopt OpenMP for offloading to accelerators, especially now with an increasing number of accelerator vendors supporting OpenMP offload.
The Intel® Application Migration Tool for OpenACC* to OpenMP* API is an open-source project that aims to help migrate OpenACC-based applications to OpenMP (reference to the IWOMP paper). This tool parses C/C++ and Fortran application sources, identifies OpenACC constructs, and proposes OpenMP (5.0 or higher) constructs that are semantically equivalent, when possible. Not all OpenACC constructs can be translated to OpenMP due to a variety of reasons, including the descriptive/prescriptive differences between them. This is especially true when dealing with performance tuning options. Hence, the tool only focuses on providing a semantically correct migrated code but does not focus on providing a performance-optimized version of the migrated code, thus leaving performance optimizations to a later stage. The tool generates a message in the migration report if it cannot convert any of the OpenACC constructs. There is further information on the mapping between the two languages in the IWOMP paper. Once the application sources have been migrated, the developer only needs to pick an OpenMP 5.0 compliant compiler and compile the application for the architecture of their interest.
In the subsequent sections we cover two successful migrations stories: POT3D and GEM. Later, we conclude this paper with some remarks.
Application Migration Examples
We have selected two applications to demonstrate the value of the migration tool. The applications are POT3D and GEM, and the reader will find some details in Table 1. These applications have been migrated and later compiled with the compilers and libraries found in Intel® HPC Toolkit 2024.0.1. Both applications have been executed on a single node containing 2S Intel® Xeon® Platinum 8480+ and four Intel® Data Center GPU Max 1550s. Each GPU consists of two compute tiles, for a total of eight compute tiles in the node. We validated the execution results against the reference output provided in the corresponding repository.
|
|
|
|
OpenACC* constructs / clauses |
||||
|---|---|---|---|---|---|---|---|
|
Application |
Language |
# lines |
# compute |
# data |
# atomic |
# async |
# API calls |
|
POT3D |
Fortran |
~11k |
33 |
33 |
2 |
23 |
0 |
|
GEM |
Fortran |
~18k |
34 |
69 |
118 |
0 |
1 |
Table 1. Application characteristics
Note: Compute constructs covered: kernels, loop, parallel and loop. Data constructs covered: enter/exit data, host_data, and update. Atomic constructs covered: atomic. Async constructs covered: async and wait.
POT3D
POT3D (commit-id: 5e8ee69f92860a372d5746462199ddfa702bbac2) is a Fortran code that computes potential field solutions to approximate the solar coronal magnetic field using observed photospheric magnetic fields as a boundary condition. The code is parallelized using MPI but has two alternatives when it comes down to GPU acceleration: OpenACC and the Fortran standard do concurrent construct. We focus on the OpenACC version in this article.

Figure 1. POT3D tracing magnetic field lines through the potential field solution, with the surface radial magnetic field shown as the red-blue colormap.
The code was translated using the following command:
${PATH_TO_TRANSLATOR}/intel-application-migration-tool-for-openacc-to-openmp src -async=none
Where src refers to the source directory of the application, and -async=none translates the code by ignoring asynchronous OpenACC statements (including wait and async) that are present in the source code. OpenMP does not provide an exact mapping for these statements. Fortunately, according to the developers, these asynchronisms provide little benefit to this application.
Some Notes on the Migration
Among the comments and warnings emitted in the migration report, we want to highlight that the application uses !$acc set device_num(iprocsh) to specify which OpenACC device to use. OpenMP offers an API call (omp_set_default_device) and an environment variable (OMP_DEFAULT_DEVICE) that mimic this behavior. Intel® MPI also offers an environment variable to pin MPI ranks with GPU devices (or tiles) (I_MPI_OFFLOAD_PIN). Consequently, we have ignored the translation of the construct and relied on the Intel MPI infrastructure when it comes to MPI rank – GPU tile binding.
When it comes to the translation, we observe that many data allocations are annotated with !$acc data create, which allocates the data counterpart in the accelerator address space, and that is translated using !$omp target enter data. We also notice that the most time-consuming region (i.e., cgsolve) contains !$acc parallel loop clauses that have been converted into !$omp target teams loop. Interestingly, the original constructs explicitly use the present(X) or default(present) clauses to let the offload runtime to check for the presence of the given variables in the accelerator address space. Those clauses are translated to map with present map-type-modifier or defaultmap clauses, respectively. There are also clauses such as !$acc update in the boundary exchanges or before/after doing I/O, among others, in order to synchronize contents of the host and accelerator address spaces.
The corresponding Makefile was manually tuned to use the MPI compiler wrapper for IFX (i.e., mpiifx) and added the necessary flags to process the OpenMP offload constructs (i.e., -fiopenmp -fopenmp-targets=spir64) and the HDF5 dependencies.
With respect to the application execution, we used the small test that comes with the application repository, and we invoked the binary (through mpirun) while setting the following environment variables I_MPI_ADJUST_BARRIER=1 I_MPI_OFFLOAD_PIN=1 I_MPI_OFFLOAD_PRINT_TOPOLOGY=1 I_MPI_DEBUG=3. The timings achieved are shown in Figure 2. The results show that the application exposes a close-to-ideal scalability up to four MPI ranks (using one compute tile on each GPU) but efficiency drops when moving to eight MPI ranks (using two compute tiles on each GPU). We have exchanged some ideas with the application developers to study the rationale of this performance drop.
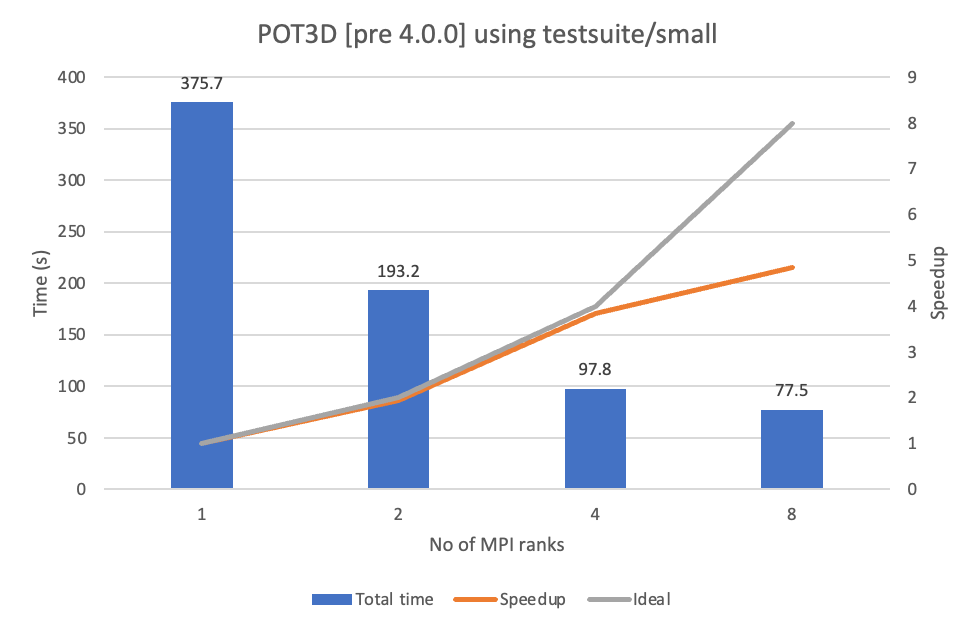
Figure 2. Performance achieved on POT3D when executed on the target system
GEM
GEM is an open-source particle-in-cell (PIC) simulation code considering physical field effect written by Fortran since 1990s. It aims to study transport in magnetically confined fusion devices, such as ITER.

Figure 3. GEM simulates the plasma particles moving in a torus shape in a magnetic equilibrium.
There are two time-consuming tasks in GEM:
- Nested loops with/without reduction
- Matrix solvers of the physical field
Both are subject to be accelerated by means of GPUs, but the code uses OpenACC to accelerate only the nested loops because developers prefer to use the standard LAPACK to implement the solvers for code maintainability. Consequently, we rely on the migration tool to convert the OpenACC constructs into OpenMP, and then we manually modify the translated code to use the oneMKL library (which provides a parallel and accelerated LAPACK implementation) through the !$omp dispatch construct. The latter translation is not within the context of this article.
The file structure of the application is simple: All source files are contained in the same folder. The command to translate the code is as follows:
lTRANSLATOR}/intel-application-migration-tool-for-openacc-to-openmp *.f90
After the translation, we have replaced the OpenACC compiler flags by -DOPENACC2OPENMP_ORIGINAL_OPENMP -fiopenmp -fopenmp-targets=spir64 to enable OpenMP offload capability on the IFX Fortran compiler. We added the -DOPENACC2OPENMP_ORIGINAL_OPENMP compiler flag because the original code also applies OpenMP constructs launching multiple threads when handling some loops too small for OpenACC to send to GPU, and these are kept by the migration tool but protected with this preprocessor variable.
Some Notes on the Migration
We would like to highlight idiosyncrasies we found during the migration:
- On the data management
- When expressing parallelism on loop constructs
Data Management
With respect to moving data around GPU and CPU, GEM uses an unstructured data approach, which provides the flexibility to establish a data mapping between the host and the device immediately after the code allocates (or deallocates) the data on host memory (i.e., using the !$acc enter data create(X) construct at data allocation time). The construct is translated by the migration tool as !$omp target enter data(X).
Then, when other application modules need to access the device data, they rely on the present(X) clause from OpenACC. This clause is converted into a map-type modifier (i.e., map(present,alloc:X)). Even though they do not look the same, the two express the same semantics; but in OpenMP, the presence check needs to go with a map-type (alloc in this case), even though the allocation is not performed.
In addition, the application code relies on the acc_is_present(X) API to identify potential cases where data is not present in the GPU address space. This API routine is not translated by the migration tool, and the tool generates a warning about this mistranslation.
Parallelism Through Loops Constructs
We identify two major parallel regions accelerated by the means of !$acc loop. The first implements some reductions using the !$acc atomic constructs. These have been translated to their OpenMP counterparts. The second region is represented by the code below. Note that there is a control-flow (if) structure inside. This loop contains a nested loop construct but, given that this is not a perfectly nested loop, one cannot use the collapse clause.
!$acc parallel present(xp,s_buf,ipsend,s_displ,s_counts)
!$omp target teams map(present,alloc:xp,s_buf,ipsend,s_displ,s_counts)
!$acc loop independent private(i,isrt,iend,isbuf)
!$omp loop order(concurrent) private(i,isrt,iend,isbuf)
DO i=0,nvp-1
IF( s_counts(i) .GT. 0 ) THEN
isrt = s_displ(i)+1
iend = s_displ(i)+s_counts(i)
!$acc loop independent
!$omp loop order(concurrent)
DO isbuf=isrt,iend
s_buf(isbuf) = xp(ipsend(isbuf))
END DO
!$acc end loop
!$omp end loop
END IF
END DO
!$omp end loop
!$acc end parallel
!$omp end target teams
The initial OpenMP implementation resulting from the migration can compile and execute with several minor manual modifications. The performance observed when run with 4 MPI ranks using 1 GPU tile per rank is shown in Figure 4, and it is aligned with developer expectations.
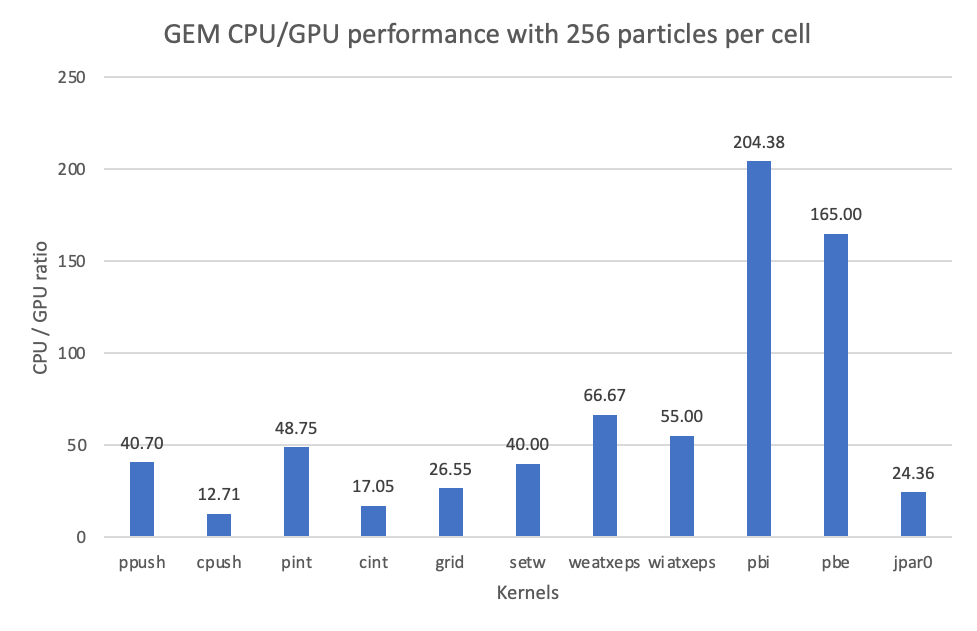
Figure 4. CPU-to-GPU ratio observed in the GEM application for the meaningful offloaded kernels
Concluding Remarks
We have shown that the Intel Application Migration Tool for OpenACC to OpenMP API has helped in porting OpenACC codes to OpenMP, allowing a user to run these codes on a variety of hardware/software if they support OpenMP 5.0. Even though the tool cannot provide a perfect translation for every OpenACC application, due to the implicit differences between the two programming models, it provides a particularly good starting point for this task. As of today, GEM developers have created a repository fork for the OpenACC translated code. We are still in discussions with the POT3D developers about adding the changes to their repository at the time of publishing this article.
In terms of potential future functionality, we are adding more translations of the OpenACC API calls to their OpenMP counterpart (if they exist) based on user feedback. We are also working towards offering a mapping alternative to the dissimilar async mechanisms found in OpenACC and OpenMP. Finally, there have been some efforts to identify CPU OpenMP directives in the original codes, and we could consider using OpenMP metadirectives for a translation supporting both CPUs and GPUs. Performance-wise, the tool cannot ensure the most performant translation due to the variety of hardware and software available, so we strongly recommend using performance tools to tune the source code.