Unify Data Science with Traditional Analytics on Modern Hardware
Venkat Krishnamurthy, product vice president, and Kathryn Vandiver, senior director, Platform and Core Engineering, OmniSci*
@IntelDevTool
Get the Latest on All Things CODE
Sign Up
OmniSci has a vision of pioneering modern hardware and software to allow for data insights at the speed of curiosity. One catalyst for this effort is today’s open-data science stack, a platform for experimentation. Through our shared vision and collaboration with Intel, we're working to advance and unify the worlds of data science with traditional analytics on modern hardware. In this article, we look at the relationship between data science applications and data discovery and explain how OmniSci and Intel are working together to advance innovation in this ecosystem.
It’s clear that we now live in a world where AI is rapidly extending human perception and intuition. Our colleagues at Intel also see this shift, and the natural progression of AI, as part of the continuum of ways for people to understand the world through data. It’s useful to think of a natural “loop” for how this understanding develops (Figure 1):
- Start at data exploration with visual analytics tools (since there's no match for human visual perception to quickly understand trends in data).
- Move to experimentation, where a data scientist builds models.
- End with explanation, where both visual analytics tools and machine learning methods combine to reveal key insights in a seamless workflow.
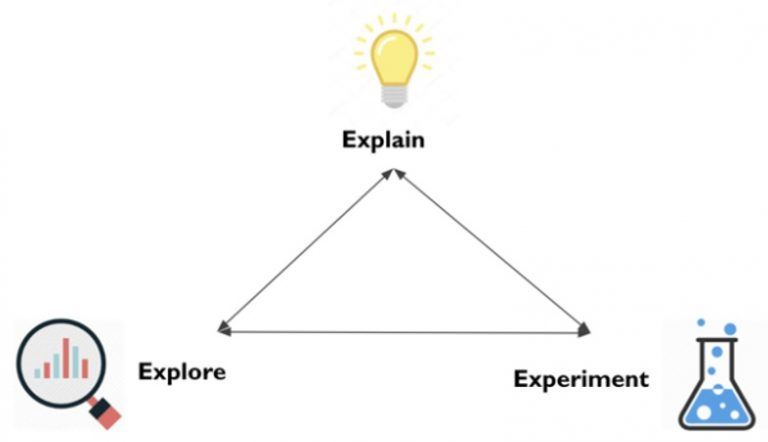
Figure 1. The loop of understanding
Today’s open-data science stack is a platform for experimentation, founded on interlocking open-source innovation across multiple ecosystems:
- Python* and PyData* stack (NumPy/SciPy)
- pandas
- Matplotlib
- Dask
- Numba*
- R language and its ecosystem
- Julia*
- Jupyter* and JupyterLab project
These components lower the cost of curiosity and help drive interactive computing in general, and data-driven storytelling in particular. As an example, Figure 2 shows the first-ever photograph of a black hole, coming to life inside a Jupyter* Notebook that's powered by these tools.
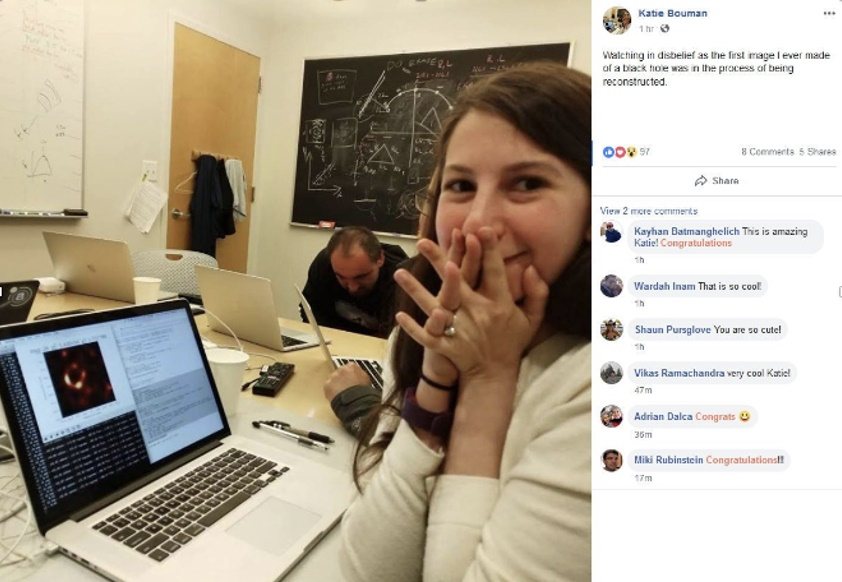
Figure 2. Photographing a black hole (more information)
Back in 2017, when OmniSci was still known as MapD*, we recognized the need to be part of this world and contribute to its growth. In-memory databases and dataframes are becoming essential technology, serving as an entry point for any type of data in the preparation, preprocessing, extraction, transformation, and loading phases of end-to-end analytics.
For an end-to-end analytics pipeline that's powered by Python, there are libraries, like pandas, that have functional power but lack optimizations for Intel® architecture. This means there's a need for an open-source, performant framework that can harness the computing power of existing and emerging Intel® hardware. Our collaboration with Intel allows OmniSciDB to be the basis for such a framework.
pandas is a critical component of the PyData ecosystem, and we decided it would be counterproductive to replicate its entire API. Instead, we believe a great deal of the pandas value lies in its powerful, expressive way of evaluating analytic expressions on an in-memory DataFrame. This is how running an OmniSciDB query already works, so the problem became to find (or build) an API that was familiar and like Python while using OmniSciDB underneath. The next step in this process is working with Intel. We're putting in place a common dataframe for OmniSci that allows for a scalable and performant workflow execution within the open data science ecosystem.
As it turns out, Wes McKinney, the creator of pandas, had already started down this road with Ibis*. His goal is to take the productivity that pandas provides and adapt it to a higher level of scalability using languages such as SQL*. Ibis, as we're discovering, is an absolute delight to use—especially paired with the OmniSci speed and scale. The deferred expression model makes it easy to perform complex analytics on any back end that's accessible via SQL (and, in a nice twist, pandas itself). By aligning on a consistent dataframe and Python bindings, the creation of a scalable workflow with OmniSci and pandas can now become a high-performance back end with Ibis.
Figure 3 shows Ibis at work on a telematics dataset with 1.45 billion rows where we're setting up an aggregate expression and performing a lazy evaluation, producing a pandas DataFrame as a result. Ibis compiles it into a SQL query and then runs it only when needed. Also, notice that the response is close to instantaneous, even running against an OmniSci server in our data center over a VPN.
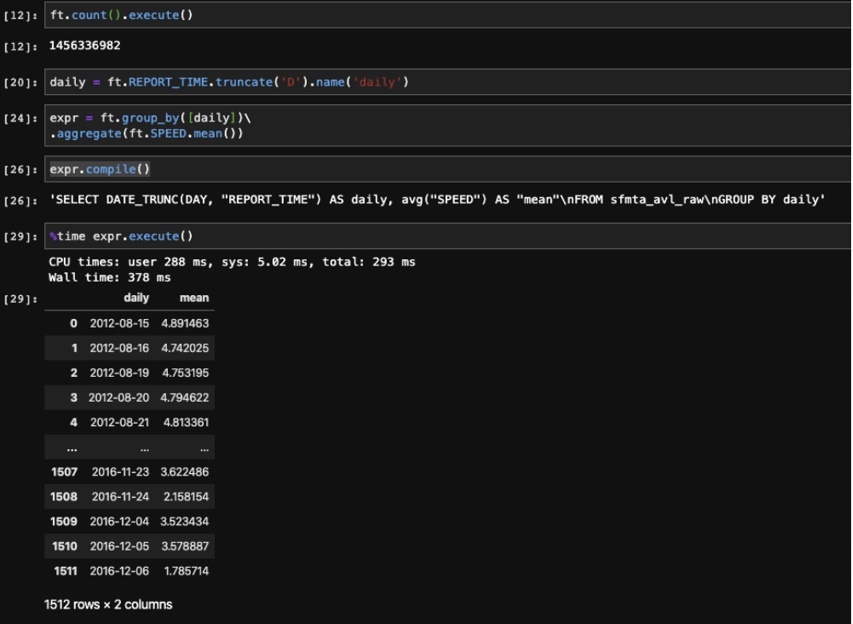
Figure 3. Ibis on a dataset with 1.45 billion rows
Thanks to this new Python API, we can already direct Ibis output to dataframe memory based on Apache Arrow* using pandas. Work is underway with Intel data scientists and machine-learning experts to continue to reduce the overhead of the interface with further acceleration on Intel® Xeon® Scalable processors with our internal result set format.
(Here’s a pretty cool aside: A back end that's supported by Ibis and pandas means you can do analysis across data sources inside a single JupyterLab notebook with oneAPI. Simply create a connection over any of these back ends and you can run Ibis expressions against them. Also, because the returned results for remote back ends default to pandas, you can wrap an Ibis connection around that pandas DataFrame. The possibilities are endless.)
There and Back Again
Finally, we've also worked on pymapd to keep up with the breathless pace of change on underlying projects (particularly Apache Arrow). A data scientist can now use all these tools and produce a dataframe that can be loaded into OmniSci via the load_table APIs in pymapd (and Ibis). The icing on the cake is the Visiual Data Fusion feature in OmniSci Immerse (announced in OmniSci 4.7) that lets a user set up charts (combo and multilayer geo charts for now) across multiple tables and sources.
Put It All Together
A key point bears repeating: We've developed each one of the capabilities we've discussed within the respective open-source project communities rather than simply forcing them to develop their own. Our work on Ibis and pandas is available to everyone involved with those communities. OmniSciDB itself is open source, as it has been for more than two years. We've also invested deeply in the packaging and installation aspects so that users can add OmniSci to their data science workflows in multiple ways.
We took care to package everything with Docker*. Our JupyterLab image includes all the tools you need to get started. As a matter of fact, you can download and try the whole setup, including OmniSciDB, on your Mac* or Linux* laptop. We use Anaconda* for Python package management. You can download and install OmniSciDB itself from conda-forge with conda install -c conda-forge omniscidb-cpu, and then the PyData tools for OmniSci with conda install -c conda-forge omnisci-pytools. Alternatively, you can get a prebuilt version of OmniSci from the downloads page.
Looking Back, Looking Forward
Let's give credit where it’s due. None of these new capabilities would've seen the light of day without the work and guidance of our open-source collaborators, including those at Intel. Ultimately, we believe cutting-edge methods in data science are in the service of the user, not the other way around. As far as a consumer of insights is concerned, we think it’s better to have the entire assembly of tools become invisible, but ensure the insights and their explanations become obvious. Through our shared vision, we're working to advance and unify the world of data science with traditional analytics on modern hardware.
______
You May Also Like
Intel® Distribution for Python*
Develop fast, performant Python code with this set of essential computational packages including NumPy, SciPy, scikit-learn*, and more.
Get It Now
See All Tools