As a close partner of Meta* on Llama 2, we are excited to support the launch of Meta Llama 3, the next generation of Llama models. Effective today, we have validated our AI product portfolio on the first Llama 3 8B and 70B models. In addition to running on Intel data center platforms, Intel is enabling developers to now run Llama 3 locally and optimize for applications and models on Intel client CPUs and GPUs.
Innovations, derivative models, and applications based on Llama 2 have enabled a vibrant ecosystem, including Purple Llama, which advances the development of open software to build generative AI trust and safety. Llama 3 introduces new capabilities, additional sizes, and enhanced model performance. This release features pretrained and fine-tuned language models with 8B and 70B parameter counts, demonstrating improved performance on a wide range of industry benchmarks, and enabling new capabilities such as improved reasoning. Llama 3 uses a new tokenizer that encodes language much more efficiently, leading to improved model performance.
Intel is bringing AI everywhere through a robust AI product portfolio that includes ubiquitous hardware and open software. In the data center, Intel® Gaudi® AI accelerators and Intel® Xeon® processors with Intel® Advanced Matrix Extensions (AMX) provide users with options to meet dynamic and wide-ranging AI requirements. On the client side, Intel enables LLMs to be run locally with either AI PCs powered by Intel® Core™ Ultra with an NPU and a built-in Arc™ GPU, or Arc discrete GPUs with Intel® Xᵉ Matrix Extensions (Intel® XMX) acceleration.
We are sharing our initial performance results of Llama 3 models on the Intel AI product portfolio using open-source software such as PyTorch*, DeepSpeed*, Hugging Face Optimum library and Intel® Extension for PyTorch*, which provide the latest software optimizations for LLMs.
Intel® Gaudi® AI Accelerators
Purpose architected for high-performance, high-efficiency training and deployment of generative AI—multi-modal and large language models – Intel® Gaudi® 2 accelerators have optimized performance on Llama 2 models – 7B, 13B and 70B parameter – and provide first-time performance measurements for the new Llama 3 model for inference and fine-tuning. With the maturity of Intel® Gaudi® software, we were able to easily run the new Llama 3 model and quickly generate results for both inference and fine-tuning, which you can see in the tables below. In addition, Meta Llama 3 is supported on the newly announced Intel® Gaudi® 3 accelerator.
| Model | TP | Precision | Input Length | Output Lenght | Throughput | Latency* | Batch |
|---|---|---|---|---|---|---|---|
| Meta-Llama-3-8B-Instruct | 1 | fp8 | 2k | 4k | 1549.27 token/sec | 7.747 ms | 12 |
| Meta-Llama-3-8B-Instruct | 1 | bf16 | 1k | 3k | 469.11 token/sec | 8.527 ms | 4 |
| Meta-Llama-3-70B-Instruct | 8 | fp8 | 2k | 4k | 4927.31token/sec | 56.23 ms | 277 |
| Meta-Llama-3-70B-Instruct | 8 | bf16 | 2k | 2k | 3574.81 token/sec | 60.425 ms | 216 |
Table 1. Llama 3 inference on Intel® Gaudi® 2 Accelerator (* Average next token latency)
|
Model |
# Gaudi2 |
Precision |
Throughput |
Batch Size |
|---|---|---|---|---|
|
Meta-Llama-3-70B-Instruct Fine Tuning (LoRA) |
8 |
bf16 |
2.548 sentences/sec |
10 |
|
Meta-Llama-3-8B-Instruct Fine Tuning (LoRA) |
8 |
bf16 |
131.51 sentences/sec |
64 |
Table 2. Llama 3 fine-tuning on Intel® Gaudi® 2 Accelerator
Use this first example to run the inference performance benchmark and this second example to run the fine-tuning benchmark.
Intel® Xeon® Scalable Processors
Intel Xeon processors address demanding end-to-end AI workloads. Available across major cloud service providers, Intel Xeon processors have an AI engine in every core AMX that unlocks new levels of performance for inference and training. Furthermore, generic computing in Xeons can provide lower latency and work alongside other workloads.
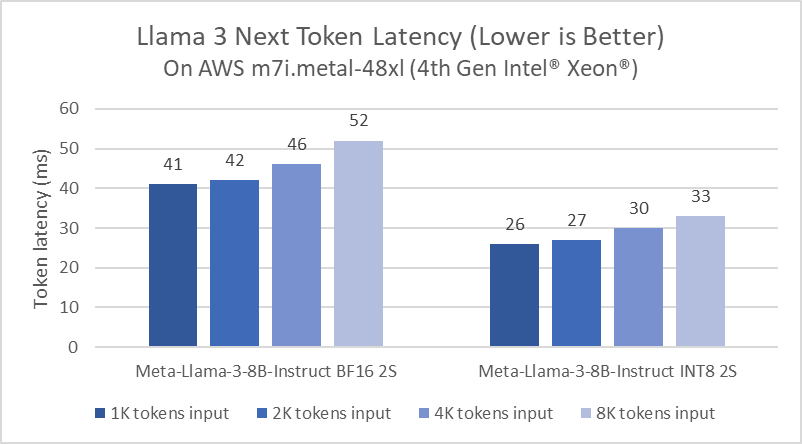
Intel has been continuously optimizing LLM inference for Xeon platforms. As an example, compared to Llama 2 launch software improvements in PyTorch and Intel® Extension for PyTorch have evolved in delivering 5x latency reduction. The optimization makes use of paged attention and tensor parallel to maximize the available compute utilization and memory bandwidth. Figure 1 shows the performance of Meta Llama 3 8B inference on AWS m7i.metal-48x instance, which is based on 4th Gen Intel Xeon Scalable processor.
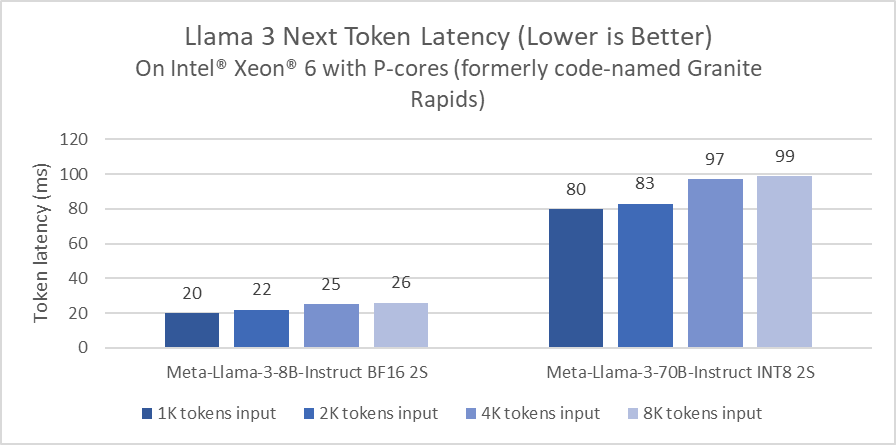
We benchmarked Meta Llama 3 on an Intel® Xeon® 6 processor with Performance cores (formerly code-named Granite Rapids) to share a preview of the performance. These preview numbers demonstrate that Intel Xeon 6 offers a 2x improvement on Llama 3 8B inference latency compared to widely available 4th Gen Intel Xeon processors, and the ability to run larger language models, like Llama 3 70B, under 100ms per generated token on a single two socket server.
Given that Llama 3 is featured with a tokenizer that encodes language more efficiently, a quick comparison between Llama 3 and Llama 2 was done using a randomly picked input prompt. The number of tokens tokenized by Llama 3 is 18% less than Llama 2 with the same input prompt. Therefore, even though Llama 3 8B is larger than Llama 2 7B, the inference latency by running BF16 inference on AWS m7i.metal-48xl for the whole prompt is almost the same (Llama 3 is 1.04x faster than Llama 2 in the case that we evaluated.).
Developers can find instructions to run Llama 3 and other LLMs on Intel® Xeon® platforms.
Intel® Client Platforms
AI PCs powered by Intel® Core™ Ultra processors deliver exceptional local AI performance in the client space through specialized silicon in three engines: CPU, GPU, and NPU. For Llama 3 evaluation, we targeted the built-in Arc™ GPU available in the Core™ Ultra H series products.
In an initial round of evaluation, the Intel® Core™ Ultra processor already generates faster than typical human reading speeds. These results are driven by the built-in Arc™ GPU with 8 Xe-cores, inclusive DP4a AI acceleration, and up to 120 GB/s of system memory bandwidth. We are excited to invest continued performance and power efficiency optimizations on Llama 3, especially as we move to our next-generation processors.
With launch day support across Intel® Core™ Ultra processors and Intel® Arc™ graphics products, the collaboration between Intel and Meta provides both a local development vehicle and deployment across millions of devices. Intel client hardware is accelerated through comprehensive software frameworks and tools, including PyTorch and Intel® Extension for PyTorch used for local research and development and OpenVINO™ Toolkit for model deployment and inference.
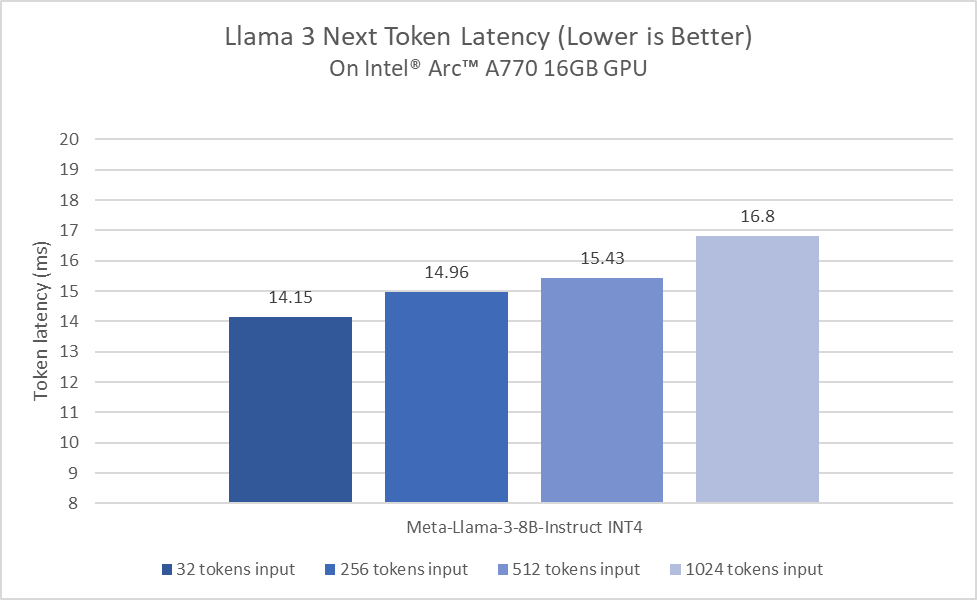
Figure 3 shows how the Intel® Arc™ A770 GPU delivers impressive performance with Llama 3 using PyTorch with Intel® GPU optimizations.
Get started on developing solutions using Llama 3 with PyTorch across Intel client products.
Summary
We have presented our initial evaluation of the inference and fine-turning performance of Llama 3 8B and 70B parameter models and demonstrated that Intel’s AI product portfolio can meet a wide range of AI requirements. We encourage you to try out Llama 3 with these ubiquitous AI solutions by accessing cloud instances or locally on your Intel-based AI PC.
References
Accelerate Llama 2 with Intel® AI Hardware and Software Optimizations
Efficient LLM inference solution on Intel GPU
Llama2 Inference with PyTorch on Intel® Arc™ A-Series GPUs
Boost LLMs with PyTorch on Intel Xeon Processors
Product and Performance Information
Intel Gaudi 2 AI Accelerator: Measurement on System HLS-Gaudi2 with eight Habana Gaudi2 HL-225H Mezzanine cards and two Intel® Xeon® Platinum 8380 CPU @ 2.30GHz, and 1TB of System Memory. Common Software Ubuntu22.04, Gaudi Software version 1.15.0-479, PyTorch: Models run with PyTorch v2.2.0 use this Docker image Environment: These workloads are run using the Docker images running directly on the Host OS. Performance was measured on April 17th 2024.
Intel Xeon Processor: Measurement on Intel Xeon® 6 Processor (formerly code-named: Granite Rapids) using: 2x Intel® Xeon® 6 processors with P-cores, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[8], Total Memory 1536GB (24x64GB DDR5 8800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.0031.D44.2403292312, microcode 0x810001d0, 1x Ethernet Controller I210 Gigabit Network Connection 1x SSK Storage 953.9G, Red Hat Enterprise Linux 9.2 (Plow), 6.2.0-gnr.bkc.6.2.4.15.28.x86_64, Test by Intel on April 17th 2024.
Measurement on 4th Gen Intel® Xeon® Scalable processor (formerly code-named: Sapphire Rapids) using: AWS m7i.metal-48xl instance, 2x Intel® Xeon® Platinum 8488C, 48cores, HT On, Turbo On, NUMA 2, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[8], Total Memory 768GB (16x32GB DDR5 4800 MT/s [4400 MT/s]); (16x16GB DDR5 4800 MT/s [4400 MT/s]), BIOS Amazon EC2, microcode 0x2b000590, 1x Ethernet Controller Elastic Network Adapter (ENA) Amazon Elastic Block Store 256G, Ubuntu 22.04.4 LTS, 6.5.0-1016-aws, Test by Intel on April 17th 2024.
Intel® Core™ Ultra: Measurement on an Intel Core Ultra 7 155H platform (MSI Prestige 16 AI Evo B1MG-005US) using 32GB LP5x 6400Mhz total memory, Intel graphics driver 101.5382 WHQL, Windows 11 Pro version 22631.3447, Balanced OS power plan, Best Performance OS power mode, Extreme Performance MSI Center mode, and core isolation enabled. Test by Intel on April 17th 2024.
Intel® Arc™ A-Series Graphics: Measurement on Intel Arc A770 16GB Limited Edition graphics using Intel Core i9-14900K, ASUS ROG MAXIMUS Z790 HERO motherboard, 32GB (2x 16GB) DDR5 5600Mhz and Corsair MP600 Pro XT 4TB NVMe. Software configurations include Intel graphics driver 101.5382 WHQL, Windows 11 Pro version 22631.3447, Performance power policy, and core isolation disabled. Test by Intel on April 17th 2024.