Learn how to run Llama 2 inference on Windows* and Windows Subsystem for Linux* (WSL2) with Intel® Arc™ A-Series GPU.
Generative AI (GenAI) has gained wide popularity and usage for generating texts, images, and more. Among generative models, large language models (LLMs) have been an integral part in taking deep learning to the next step in text generation. LLMs can have billions to trillions of parameters, trained on massive text datasets, showing remarkable capabilities. LLMs typically have a transformer-based architecture with multiple decoder layers, which generate the next token from the preceding tokens. The generation task is memory bound due to iterative decode. Popular LLMs include GPT-J, LLaMA, OPT, and BLOOM. Llama 2 is a collection of pretrained and fine-tuned Llama language models ranging from 7 billion to 70 billion parameters.1
These characteristics of LLMs make GPUs well suited for LLM workloads as GPUs excel at massive data parallelism and high memory bandwidth. The Intel Arc A-series graphics, including Intel® Arc™ A770 Graphics, are high-performance graphics containing up to 16 GB GPU memory and 32 Xe-cores. Each Xe-core is equipped with 16 Intel® Xe Matrix Extensions (Intel® XMX) engines, in total up to 512 Intel XMX engines, used to optimize millions of repeated GEMM (General Matrix Multiply) operations in deep learning inference and training. The Intel Arc A-series graphics provide capability for accelerated execution of deep learning models, including LLMs.

Intel® Extension for PyTorch* extends PyTorch with the latest performance optimizations for Intel hardware, taking advantage of Intel XMX engines on Intel discrete GPUs. Intel Extension for PyTorch enables PyTorch XPU devices, which allows users to easily move PyTorch model and input data to the device to run on an Intel discrete GPU with GPU acceleration. The latest release of Intel Extension for PyTorch (v2.1.10+xpu) officially supports Intel Arc A-series graphics on WSL2, built-in Windows, and native Linux. Users can run PyTorch models on Intel Arc A-series graphics via Intel Extension for PyTorch.
In this article, we show how to run Llama 2 inference on Intel Arc A-series GPUs via Intel Extension for PyTorch. We demonstrate with Llama 2 7B and Llama 2-Chat 7B inference on Windows and WSL2 with an Intel Arc A770 GPU.
Setup
Prerequisites
Note WSL2 provides users with a Linux environment within their Windows system. If you wish to use WSL2, follow the instructions for installation and setup before proceeding.
System Requirements
Make sure that your system is compatible with the following system requirements. Refer to the Installation Guide for more details.
Hardware
Install drivers for Intel Arc A-series GPU. Once installed, you can verify under Device Manager > Display adapters that your Intel Arc A-series gPU is listed.
Software
Install Intel® oneAPI Base Toolkit.
Preparation
Setup conda virtual environment
conda create -n llm python=3.9 -y
conda activate llm
Install Requirements
Install Dependencies (Windows Only)
conda install pkg-config libuv
python -m pip install accelerate sentencepiece
Install PyTorch and Intel Extension for PyTorch
python -m pip install torch==2.1.0a0 intel-extension-for-pytorch==2.1.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
Install Transformers
python -m pip install transformers==4.31.0
Verification
Activate Intel oneAPI Base Toolkit environment
Windows
call "{ONEAPI_PATH}\setvars.bat"
WSL2
source {ONEAPI_PATH}/setvars.sh
Run the following command to verify the installations of PyTorch and Intel Extension for PyTorch, and the detection of a driver for an Intel Arc A-series GPU.
python -c "import torch; import intel_extension_for_pytorch as ipex; print(torch.__version__); print(ipex.__version__); [print(f'[{i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
A sample output of the above command is shown:
2.1.0a0+cxx11.abi
2.1.10+xpu
[0]: _DeviceProperties(name='Intel(R) Arc(TM) A770 Graphics', platform_name='Intel(R) Level-Zero', dev_type='gpu, support_fp64=0, total_memory=13004MB, max_compute_units=512, gpu_eu_count=512)
Run Llama 2 Inference with PyTorch on Intel Arc A-Series GPUs
We're now ready to run Llama 2 inference on Windows and WSL2 with Intel Arc A-series GPU.
Make sure to have Intel oneAPI Base Toolkit environment activated as before.
Llama 2 7B FP16 Inference
Let's run meta-llama/Llama-2-7b-hf inference with FP16 data type in the following example. Let's generate some creative text about Schrödinger’s cat!
Note Intel Arc A770 graphics (16 GB) running on Intel® Xeon® w7-2495X processor was used in this blog. Llama 2 7B inference with half precision (FP16) requires 14 GB of GPU memory.2
Note meta-llama on Hugging Face* requires access request and approval.
import torch
from transformers import AutoModelForCausalLM, LlamaTokenizer
############# code changes ###############
# import ipex
import intel_extension_for_pytorch as ipex
# verify Intel Arc GPU
print(ipex.xpu.get_device_name(0))
##########################################
# load model
model_id = "meta-llama/Llama-2-7b-hf"
dtype = torch.float16
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype, low_cpu_mem_usage=True)
tokenizer = LlamaTokenizer.from_pretrained(model_id)
############# code changes ###############
# move to Intel Arc GPU
model = model.eval().to("xpu")
##########################################
# generate
with torch.inference_mode(), torch.no_grad(), torch.autocast(
############# code changes ###############
device_type="xpu",
##########################################
enabled=True,
dtype=dtype
):
text = "You may have heard of Schrodinger cat mentioned in a thought experiment in quantum physics. Briefly, according to the Copenhagen interpretation of quantum mechanics, the cat in a sealed box is simultaneously alive and dead until we open the box and observe the cat. The macrostate of cat (either alive or dead) is determined at the moment we observe the cat."
input_ids = tokenizer(text, return_tensors="pt").input_ids
############# code changes ###############
# move to Intel Arc GPU
input_ids = input_ids.to("xpu")
##########################################
generated_ids = model.generate(input_ids, max_new_tokens=128)[0]
generated_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
print(generated_text)
Here is a sample output. Generated text is encapsulated in the blue box.
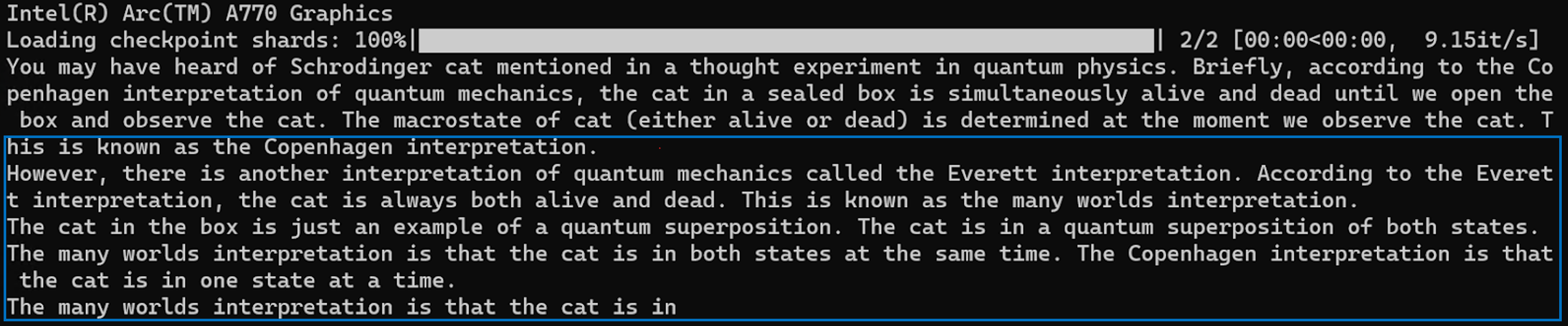
Llama 2-Chat 7B FP16 Inference
Let's also try chatting with Llama 2-Chat. Llama 2-Chat is a fine-tuned Llama 2 for dialogue use cases.1
Let's run meta-llama/Llama-2-7b-chat-hf inference with FP16 data type in the following example. Let's ask if it thinks AI can have generalization ability like humans do.
Note Intel Arc A770 graphics (16 GB) running on an Intel Xeon w7-2495X processor was used in this blog. Llama 2 7B inference with half precision (FP16) requires 14 GB GPU memory.
Note meta-llama on Hugging Face requires access request and approval.
import torch
from transformers import AutoModelForCausalLM, LlamaTokenizer
############# code changes ###############
# import ipex
import intel_extension_for_pytorch as ipex
# verify Intel Arc GPU
print(ipex.xpu.get_device_name(0))
##########################################
# load model
model_id = "meta-llama/Llama-2-7b-chat-hf"
dtype = torch.float16
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype, low_cpu_mem_usage=True)
tokenizer = LlamaTokenizer.from_pretrained(model_id)
############# code changes ###############
# move to Intel Arc GPU
model = model.eval().to("xpu")
##########################################
# generate
with torch.inference_mode(), torch.no_grad(), torch.autocast(
############# code changes ###############
device_type="xpu",
##########################################
enabled=True,
dtype=dtype
):
text = "Humans have good generalization abilities. For example, children who have learned how to calculate 1+2 and 3+5 can later calculate 15 + 23 and 128 x 256. Can deep learning have such generalization ability like humans do?"
input_ids = tokenizer(text, return_tensors="pt").input_ids
############# code changes ###############
# move to Intel Arc GPU
input_ids = input_ids.to("xpu")
##########################################
generated_ids = model.generate(input_ids, max_new_tokens=512)[0]
generated_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
print(generated_text)
Here is a sample output. Generated text is encapsulated in a blue box:
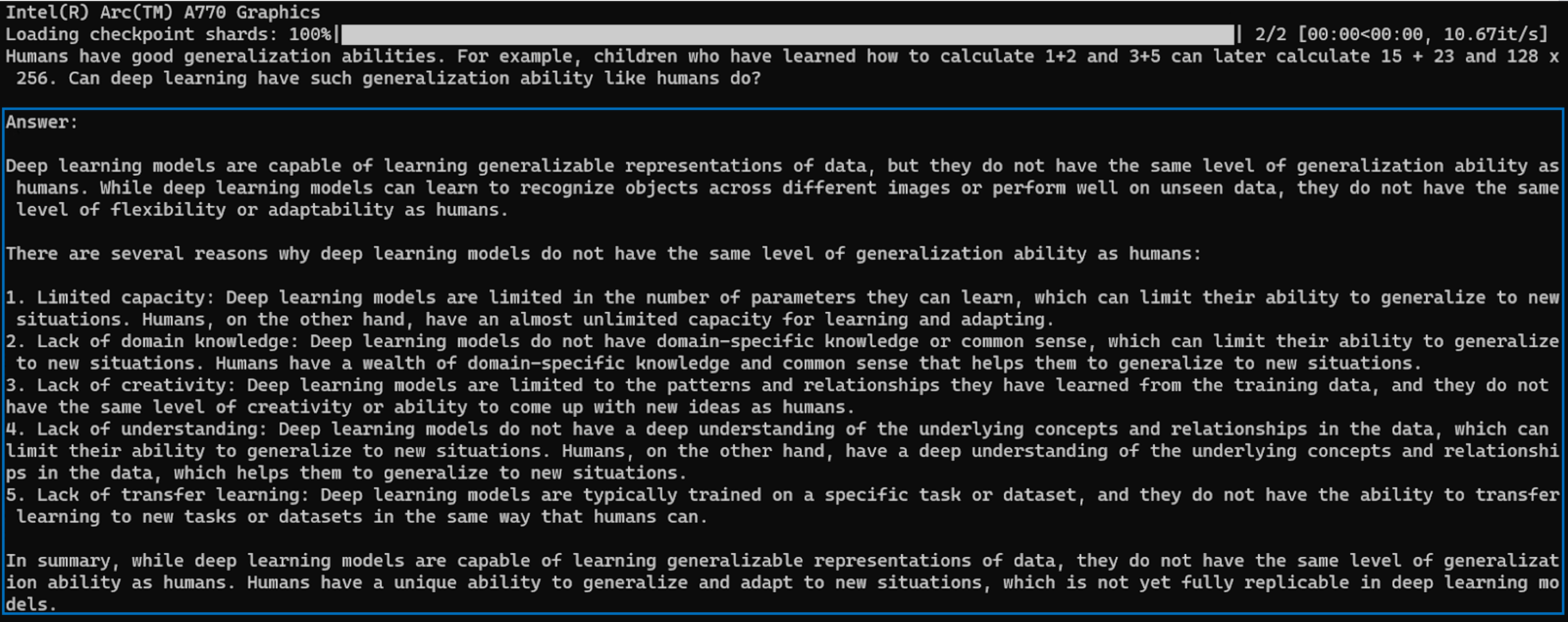
Let's also ask about Moore's Law.
Here is a sample output. Generated text is encapsulated in a blue box:

Summary
In this blog, we showed how to run Llama 2 inference with PyTorch on Intel Arc A-series graphics via Intel Extension for PyTorch. Here are the key takeaways:
- GPUs are well suited for LLM workloads as GPUs excel at massive data parallelism and high memory bandwidth. The Intel Arc A-series graphics, including Intel Arc A770 graphics, are high-performance graphics, with up to 512 Intel XMX engines, providing the capability for accelerated execution of deep learning models, including LLMs.
- Intel Extension for PyTorch extends PyTorch with the latest performance optimizations for Intel hardware, taking advantage of Intel XMX engines on Intel discrete GPUs.
- Intel Extension for PyTorch enables a PyTorch XPU device, which allows it to more easily move a PyTorch model and input data to a device to run on a discrete GPU with GPU acceleration.
- The latest release of Intel Extension for PyTorch (v2.1.10+xpu) officially supports Intel Arc A-series graphics on WSL2, built-in Windows and built-in Linux.
- Demonstrated running Llama 2 7B and Llama 2-Chat 7B inference on Intel Arc A770 graphics on Windows and WSL2 via Intel Extension for PyTorch.
- To run Llama 2, or any other PyTorch models, on Intel Arc A-series GPUs, simply add a few additional lines of code to import intel_extension_for_pytorch and .to("xpu") to move model and data to device to run on a Intel Arc A-series GPU.
You can similarly run other LLMs or any other PyTorch models on Intel discrete GPUs. In a future post, we will show how to optimize LLM performance on Intel Arc A-series GPUs.
Next Steps
Get the Software
Try out the Intel Extension for PyTorch on Intel Arc A-series GPU to run Llama 2 inference on Windows and WSL2.
Check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow.
Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
Recommended Resources
- Intel Extension for PyTorch on GitHub Repository
- Intel Extension for PyTorch for Python Package Index* (PyPI)
- Intel Extension for PyTorch Documentation
- Intel Arc A-Series Graphics
- Introduction to the Xe HPG Microarchitecture