Overview
Deep learning is a complex structure of machine learning algorithms that enables the processing of unstructured data like images, text, and videos. Deep learning frameworks make it easier for data scientists and developers to collect, analyze, and interpret large amounts of data.
To optimize deep learning framework performance and build faster applications on various hardware architectures, Intel offers Intel® oneAPI Deep Neural Network Library (oneDNN).
Benefits
oneDNN is a performance library that provides highly optimized implementations of building blocks for deep learning applications and frameworks. It is an open source, cross-platform library that helps developers and data scientists use the same API for CPUs, GPUs, or both. The advantages are:
- Improve the performance of frameworks that you already use, such as PyTorch*, TensorFlow*, AI Tools from Intel, and OpenVINO™ toolkit.
- Build faster deep learning applications and frameworks using optimized building blocks.
- Implement AI applications optimized across hardware architectures (including Intel CPUs and GPUs) without writing any target-specific code.
Features
The following image illustrates the primitive attributes and descriptors in the oneDNN programming model.
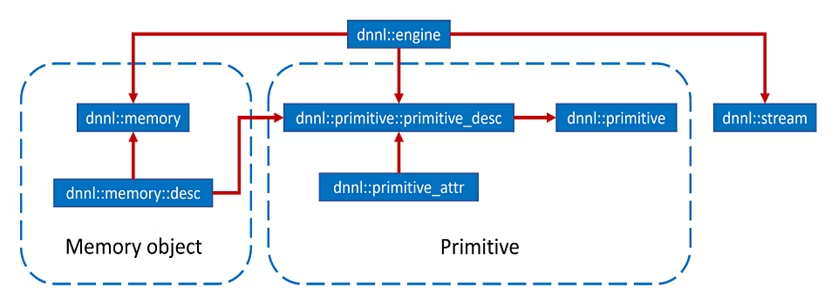
An Abstract Programming Model
The key concepts of the oneDNN programming model are primitives, engines, streams, and memory objects.
- Primitives: Any low-level operations from which more complex operations are constructed, such as convolution, data format reorder, and memory.
- Engines: An abstraction of a computational device, such as a CPU or GPU.
- Streams: A queue of primitive operations on an engine.
- Memory objects: Handles to memory allocated on a specific engine, tensor dimensions, data type, and memory format.
Automatic Optimization
oneDNN enables the support of using existing deep learning frameworks. You can develop platform-independent deep learning applications and deploy instruction set architecture (ISA) with automatic detection.
Network Optimization
This library enables you to identify performance bottlenecks using Intel® VTune™ Profiler. Additionally, it allows you to use automatic memory format selection and propagation based on hardware and convolutional parameters.
Optimized Implementations of Key Building Blocks
oneDNN supports primitives such as convolution, matrix multiplication, pooling, batch normalization, activation functions, recurrent neural network (RNN) cells, and long short-term memory (LSTM) cells.
Get Started
Installation
Binary distribution of oneDNN software can be installed in the following ways:
- As a part of the Intel® oneAPI Base Toolkit
- From Anaconda*
- As a stand-alone version
If the configuration you need is unavailable, you can build a oneDNN library from the source. This library is optimized for use on Intel® architecture processors and Intel® Processor Graphics and to boost the performance of deep learning frameworks such as PyTorch and TensorFlow. Check the system requirements page and build options for more details about CPU and GPU runtimes.
Code Example
In this C++ code example, we demonstrate the basics of oneDNN programming model:
- Creating oneDNN memory objects and oneDNN primitives.
- Running the primitives.
The first step is to create a getting_started_tutorial() function with all the steps needed to create a oneDNN programming model. In turn, this function is called from the main() function. The steps implemented in the code sample are:
- Include public headers.
To use the oneDNN library, we must first include the dnnl.hpp header file in the program. We are also using dnnl_debug.h for debugging facilities."oneapi/dnnl/dnnl.hpp" "oneapi/dnnl/dnnl_debug.h" - Create an engine and stream to run a primitive.
oneDNN primitives and memory objects are attached to a particular dnnl::engine and require a dnnl::stream for running. An engine requires dnnl::engine::kind and the index of the device of the given kind. A stream just needs an engine object, like the following:eng(engine_kind, 0); engine_stream(eng); - Prepare data.
Create a 4D tensor in NHWC format. Note that even though we work with one image only, the image tensor is still 4D. The extra dimension (here, N) corresponds to the batch and, in the case of a single image, is equal to 1. The prepared 4D tensor needs to be wrapped into a oneDNN memory object.int N = 1, H = 13, W = 13, C = 3; //Compute physical strides for each dimension int stride_N = H * W * C; int stride_H = W * C; int stride_W = C; int stride_C = 1; // An auxiliary function that maps logical index to the physical offset auto offset = [=](int n, int h, int w, int c) { return n * stride_N + h * stride_H + w * stride_W + c * stride_C; }; // The image size const int image_size = N * H * W * C; // Allocate a buffer for the image std::vector<float> image(image_size); // Initialize the image with some values for (int n = 0; n < N; ++n) for (int h = 0; h < H; ++h) for (int w = 0; w < W; ++w) for (int c = 0; c < C; ++c) { int off = offset( n, h, w, c); // Get the physical offset of a pixel image [off] = -std::cos(off / 10.f); } - Wrap data into a oneDNN memory object.
Wrap the prepared image in a dnnl::memory object, which allows us to pass it to oneDNN primitives. This can be performed in two steps:
a. Initialize the dnnl::memory::desc struct:auto src_md = memory::desc( {N, C, H, W}, // logical dims, the order is defined by a primitive memory::data_type::f32, // tensor's data type memory::/format_tab::nhwv // memory format, NHWC in this case );
b. Create the dnnl::memory object itself:// src_mem contains a copy of image after write_to_dnnl_memory function auto src_mem = memory(src_md, eng); // For dst_mem the library allocates buffer auto dst_mem = memory(src_md, eng); - Create an ReLU primitive. This requires two steps:
a. Create an operation primitive descriptor that defines operation parameters and is a lightweight descriptor of the actual algorithm that implements the given operation:auto relu_pd = eltwise_forward::primitive_desc( eng, // an engine the primitive will be created for prop_king::forward_inference, algorithm::eltwise_relu, src_md, // source memory descriptor src_md, // destination memory descriptor 0.f, // alpha parameter means negative slope in case of ReLU 0.f // beta parameter is ignored in case of ReLU );
b. Create a primitive that can be run on memory objects to compute the operation:auto relu = eltwise_forward(relu_pd);
Note Remember that primitive creation is an expensive operation, so consider creating it once and running it multiple times.
- Run the ReLU primitive and wait for its completion.
Input and output memory objects are passed to the execute() method using a <tag, memory> map. A primitive runs in a stream. Depending on the stream kind, a run might be blocking or nonblocking. This means that we need to call dnnl::stream::wait before accessing the results.// Execute ReLU (out-of-place) relu.execute(engine_stream, // The execution stream { // A map with all inputs and outputs {DNNL_ARG_SRC, src_mem}, // Source tag and memory obj {DNNL_ARG_DST, dst_mem}, // Destination tag and memory obj }); // Wait the stream to complete the execution engine_stream.wait(); - Obtain the result and validation.
The result is stored in the dst_mem memory object. It means that we need to receive it and cast it to float*. This is safe since we created dst_mem as an f32 tensor with a known memory format.std::vector<float> relu_image(image_size); read_from_dnnl_memory(relu_image.data(), dst_mem); - Call the prepared function in main().
Here, we can define additional error handling if needed.int main(int argc, char **argv) { engine_kind = parse_engine_kind(argc, argv); getting_started_tutorial(engine_kind); finalize(); return 0; }
The getting_started.cpp code example highlights how to create and run oneDNN memory objects and primitives. Additionally, it demonstrates that these key concepts of oneDNN play a significant role in improving the deep learning performance on various hardware architectures.
What's Next?
Adopt the oneDNN library to accelerate deep learning performance on various hardware architectures. Watch the get started video about oneDNN and learn how to develop high-performance, optimized deep learning applications on CPUs and GPUs.
Learn about feature information and release downloads for the latest and previous releases of oneDNN on GitHub* and feel free to contribute to the project.
We encourage you to also check out and incorporate Intel's other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of the Intel® AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
Get Started with AI Development
Additional Resources
- AI Frameworks
- Overview of oneDNN
- oneDNN Documentation
- oneDNN Developer Guide and Reference
- Optimized Machine Learning and Deep Learning with oneDNN
- AI Concepts: Machine Learning | Inference
- AI and Machine Learning Ecosystem: Developer Hub | Developer Resources
- AI Tools Documentation
Featured Software
Download oneDNN as a part of the Intel® oneAPI Base Toolkit (Base Kit) or as a stand-alone version.
AI Code Samples
- Accelerate PyTorch Models Using Quantization Techniques with Intel® Extension for PyTorch*
- How to Build an Interactive Chat-Generation Model Using DialoGPT and PyTorch
- Fine-Tune Text Classification with Intel® Neural Compressor